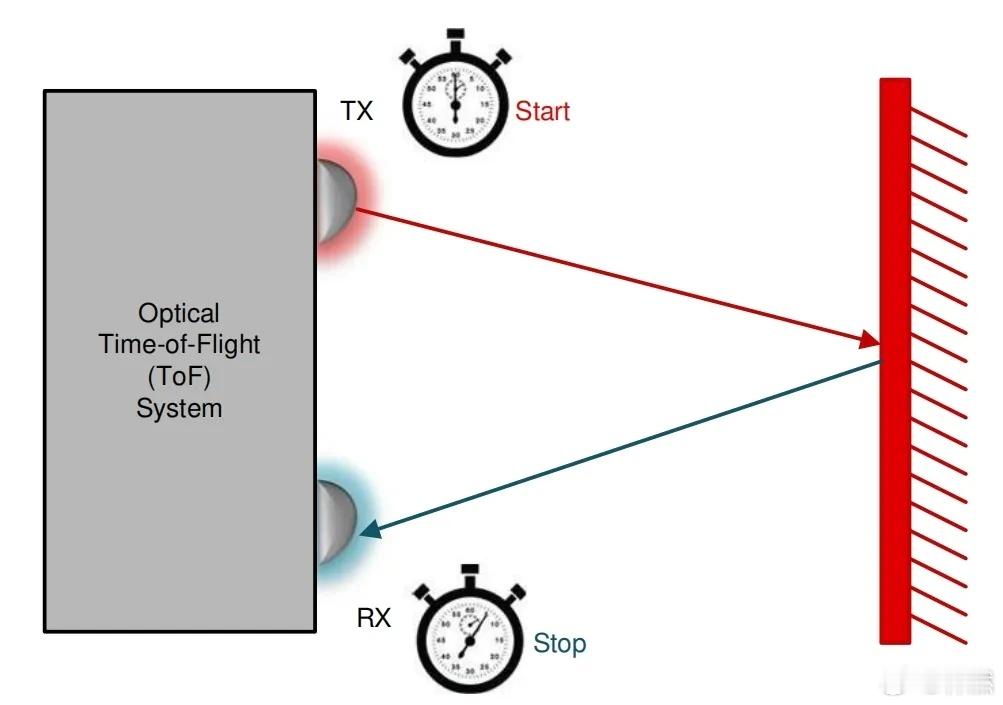
和VLA的核心-语言智能相比,世界模型的核心-空间智能显然更加接近驾驶任务的本质。在语言智能和空间智能这两种智能形式里,语言智能以一维序列信息处理抽象的符号和逻辑,空间智能重在理解物体在三维空间中的位置、形状、深度、运动等几何属性以及各类物体之间的物理关系。很显然,比起一维的语言智能,三维的空间智能更加适合自动驾驶这种需要在三维空间中完成的任务。站在空间智能的视角下,可直接提供三维信息的激光雷达正是为自动驾驶系统提供三维空间理解能力、构建空间智能的核心传感器。通过发射激光束并测量其返回时间,激光雷达能直接生成周围环境的三维点云,每个点都包含精确的XYZ坐标,相当于为车辆实时绘制出高精度的几何素描。这种基于物理测量的深度信息意味着原生的三维能力,在准确性、可靠性和稳定性上,优于只能提供二维信息、并通过算法间接推断三维深度的摄像头传感器。这种维度上的天然优势,是视觉方案的支持者无法回避的。大v聊车