为何会提出光互连解决当前HBM封装的极限?最本质的原因是:我们正在一步步接近HBM封装的极限。
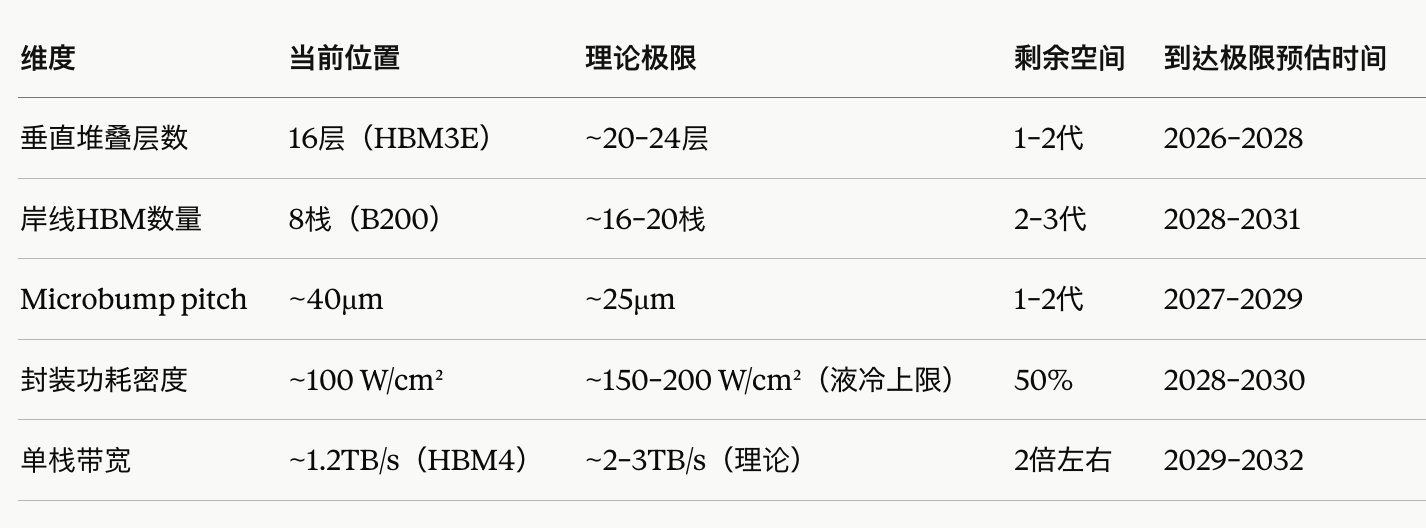
一、物理规律的极限被逐渐触及:极限1️⃣:垂直堆叠层数——已触顶HBM的堆叠演进:HBM2(8层)→ HBM2E(8层)→ HBM3(12层)→ HBM3E(12/16层)→ HBM4(计划16–20层)。每多叠一层,TSV(硅穿孔)的深宽比就要提高。目前16层的TSV深宽比约为20:1,这是电镀铜填充工艺的极限边缘——再往上,铜填充时气泡无法逸出,良率断崖式下跌。更深的问题是热阻叠加。每层DRAM die的导热路径要穿越所有下层芯片才能到达散热器。12层堆叠时底层die的结温(junction temperature)比顶层高约15°C,20层时这个差距会超过25°C,已经超过DRAM工作安全边界。这都导向一个事实——垂直方向的物理扩展空间已所剩无几。
极限②:硅中介层岸线——已触顶GPU的「岸线」(shoreline)是GPU die四周边缘的物理周长。HBM堆栈通过硅中介层与GPU并排,HBM的数量上限就是:GPU周长能容纳多少个HBM接口宽度。假设GPU die最终做到一个reticle极限,周长约为130mm,单个HBM4堆栈接口约需4mm,理论上限约为32个堆栈——但实际上电源/信号走线、角落利用率等因素会把这个数字压到16–20个以内。
极限③:带宽密度(单位面积IO数)——接近极限Microbump的物理极限大约在25–30μm pitch,低于这个数字,焊锡球的表面张力和对准精度无法维持量产良率。
极限④:功耗密度——这是最被低估的极限HBM3E每栈满载功耗约15W,8栈就是120W,加上GPU本身的600–700W,整个封装的功耗密度已经超过100 W/cm²,相当于火箭发动机喷口附近的热流密度。散热才是最硬的物理墙。HBM越叠越高,散热路径越长,这是垂直堆叠无法回避的热阻叠加问题,与材料科学的边界直接碰撞。—————————————————————————
二、光连接的解法电信号传输本质上是在用「极短距离」这个物理条件换取优势。光的优势恰好在电的弱点处显现——光信号的带宽与距离几乎无关。当GPU与HBM的物理间距被迫增加,光互连的相对优势就从「理论上可行」变成「工程上合理」。—————————————————————————三、目前技术架构的可能形态方案A:光学Bridge芯片在硅中介层中嵌入硅光子波导层,GPU与HBM之间的信号不再走铜线,而是走片内波导。距离仍在毫米级,但打破了「必须紧邻」的约束,允许HBM在中介层上远离GPU边缘排列。这是Ayar Labs(与Intel合作)的TeraPHY路线,已在2024年实现单chiplet 2Tbps光I/O,且可3D堆叠于逻辑芯片下方。
方案B:CXL over Optics(推理情况不合适)将多个HBM堆栈聚合为独立的记忆体池模块,通过CXL协议与GPU通信。距离可达几厘米至数十厘米,直接接入背板。这不是HBM专属光互连,而是把HBM变成CXL记忆体节点。延迟代价:每次E→O→O→E转换约增加5–10ns,相对于DRAM本身的~150ns访问延迟,约增加3–7%,在大模型训练的流式访问模式下可接受,但推理场景(延迟敏感)会更在意。
方案C:3D光学垂直互连(最激进)将HBM置于GPU正下方,利用垂直光学通孔(Optical Through-Silicon Vias,OTSV) 实现Z轴方向的光互连。这在理论上消灭了岸线限制(HBM直接在GPU下方大面积铺展),同时保持极短传输距离。
方案D:光子织网把光子互连fabric做成一个独立的2D芯片层,像三明治一样插在GPU和HBM(或其他加速器)之间,所有芯片通过这层光子层通信。它并不限定是HBM,而是一个通用的光互连基板。—————————————————————————四、这个方案的难点:激光源这是目前工程界最头疼的问题。硅不能发光。硅光子可以导光、调制光、探测光,但无法产生光。今天所有硅光子方案的激光源都是III-V族化合物半导体(InP、GaAs基材料),需要外置激光器,通过fiber coupling耦合进硅波导。
这带来:可靠性问题:激光器是光互连系统中寿命最短的组件良率问题:光纤与波导的耦合对准精度要求亚微米级,大规模封装良率极低成本问题:III-V激光器目前仍比硅便宜不了多少,难以摊薄功耗问题:激光源本身的电光转换效率约30–40%,是额外的能耗来源————————————————————————五、解决路径:1️⃣直接在硅上外延生长III-V材料Intel、MIT林肯实验室、UCSB都在研究,但良率与可靠性尚未达到量产标准。2️⃣另一条路是量子点激光器直接长在硅上,理论上可行但仍是实验室阶段。AXT(AXTI)的潜在价值就在这里——其磷化铟(InP)基片是高性能光互连激光器的关键衬底材料,这条需求链条目前仍处于早期。————————————————————————六、时间线2026–2027:板级CPO(GPU与光引擎共封装)进入量产,主要用于scale-out网络,不直接涉及HBM2027–2029:光学Bridge方案开始进入高端AI加速器概念验证,HBM可能扩展至更远位置但仍在同一封装内2029–2032:CXL over Optics的记忆体池化开始规模部署,HBM功能性分离2032+:真正意义上GPU-HBM光互连作为标准封装方案,仍存在不确定性