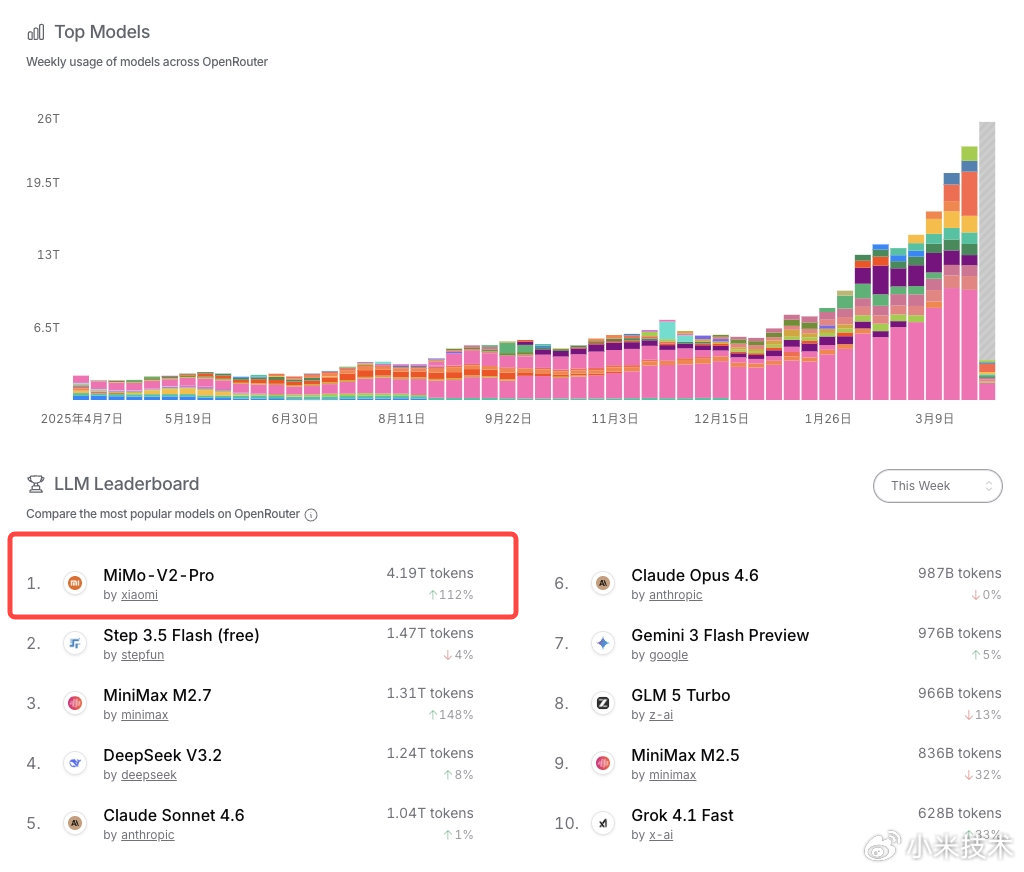
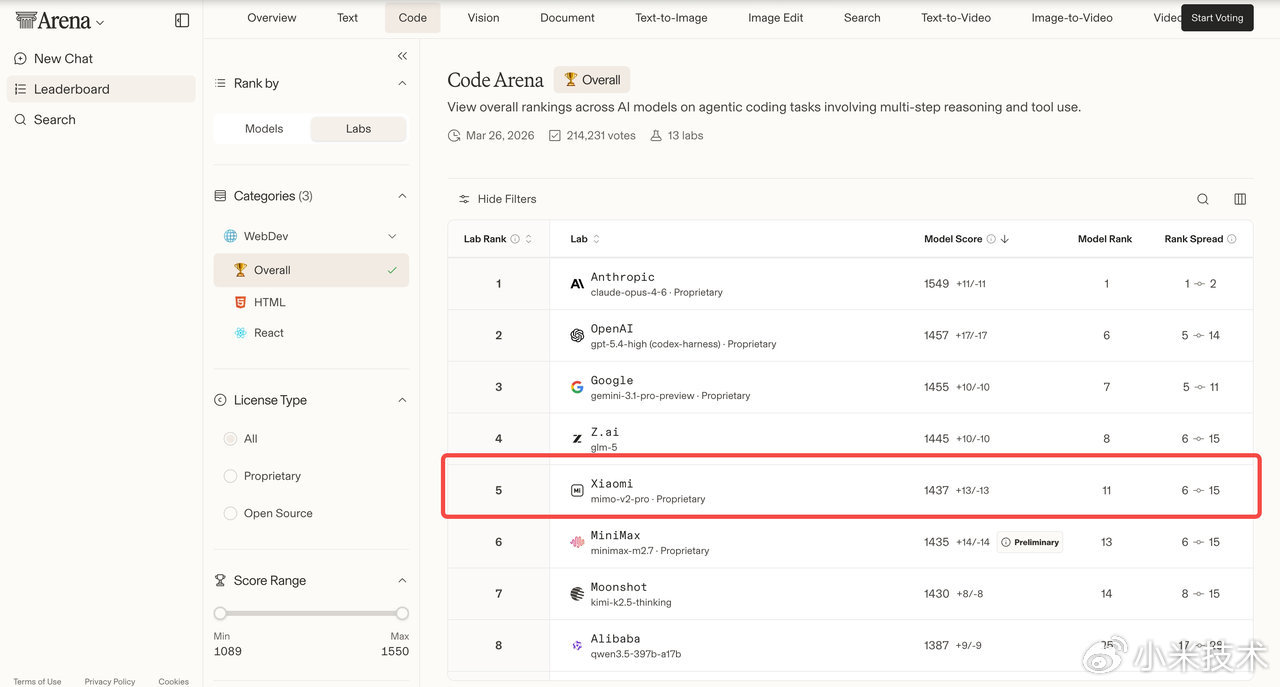
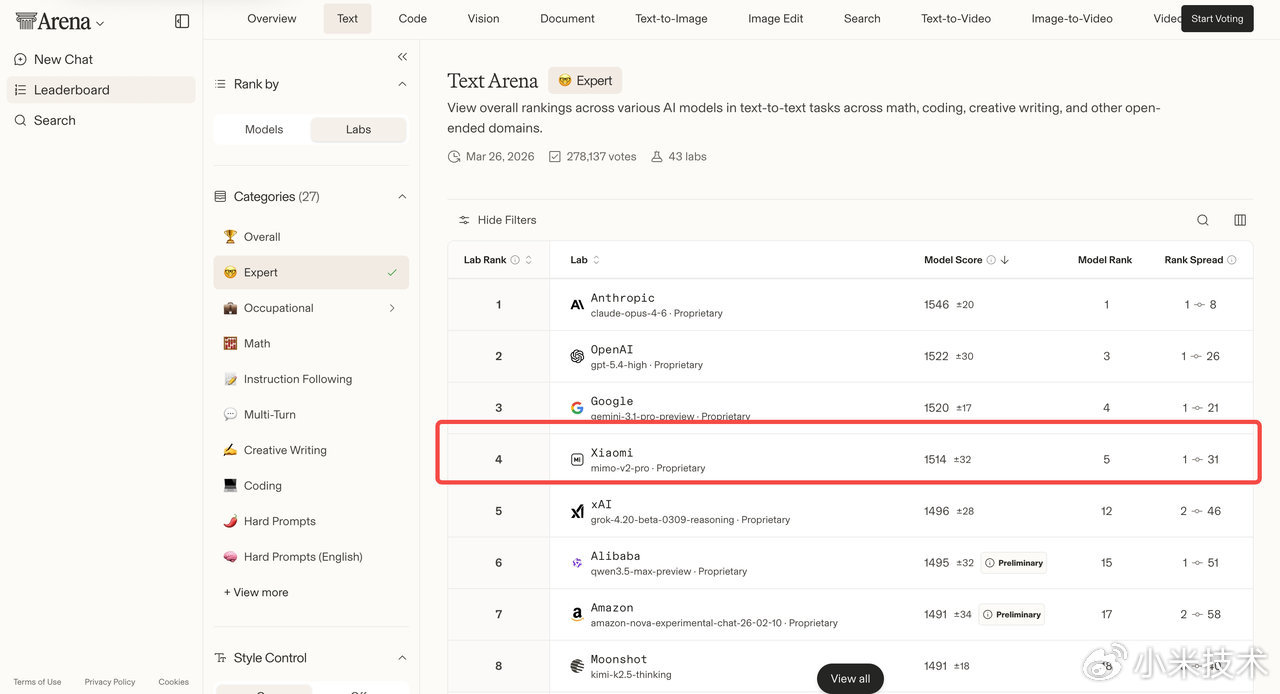
OpenRouter不是普通的评测榜单,它是全球开发者圈最主流的大模型聚合调用平台,相当于全球顶级大模型的“公用应用商店”,上面聚集了GPT、Claude、Gemini、Llama等几乎所有全球头部模型。而token消耗量,是全球开发者用真实业务需求投出来的票,是比任何付费评测榜都硬的市场认可度指标——毕竟没有开发者会浪费算力和时间,去持续调用一个不好用的模型,哪怕它免费。这次小米MiMo-V2-Pro的成绩,放在全球大模型行业里看,都是现象级的:- 上线首周token消耗直接破3万亿,创下OpenRouter平台历史记录;- 上线不到半个月,累计token消耗超6万亿,直接包揽平台日榜、周榜、月榜三榜第一,把常年霸榜的GPT、Claude、Gemini全部甩在身后;- 最新周榜数据,单周token消耗突破4万亿,和第二名拉开了近3倍的差距,这个领先幅度在OpenRouter的历史上极其罕见。很多人会简单归因于“免费所以数据高”,但必须明确:OpenRouter上的免费模型不止小米一家,免费只是降低了试用门槛,真正支撑token指数级增长的,是模型本身的能力匹配了开发者的真实需求,是全球开发者圈子里的口碑扩散——这也是这次事件最核心的价值:它不是一次营销造势,是市场用脚投票投出来的结果。再看技术端的硬实力,这是打消“刷数据”质疑的核心铁证。这次通报里提到的Text Arena,是目前全球公认的、最能衡量大模型真实通用能力的评测体系之一,它的核心规则是双盲匿名投票:测试时完全隐藏模型身份,由全球真实用户针对回答质量即时投票,从根源上杜绝了传统评测里“针对数据集刷分”的行业通病。而其中的Arena Expert榜,更是以高难度专业任务著称,是衡量大模型“核心智力”的关键标尺。MiMo-V2-Pro在这个榜单上冲进全球前五,仅次于Anthropic、OpenAI、Google三家全球顶级AI大厂,是国内大模型在这个高难度榜单上拿到的最好成绩之一。同时在实验室综合排名上,小米拿下了Text Arena全球第四、Code Arena全球第五,这直接证明:小米的大模型不是靠堆参数、刷特定任务拿分的偏科生,而是文本理解、专业复杂任务处理、代码生成三大核心能力,全部进入了全球第一梯队,真正摸到了通用人工智能的顶级门槛。