【当大模型开始 “睡觉”,AI的记忆逻辑彻底变了】
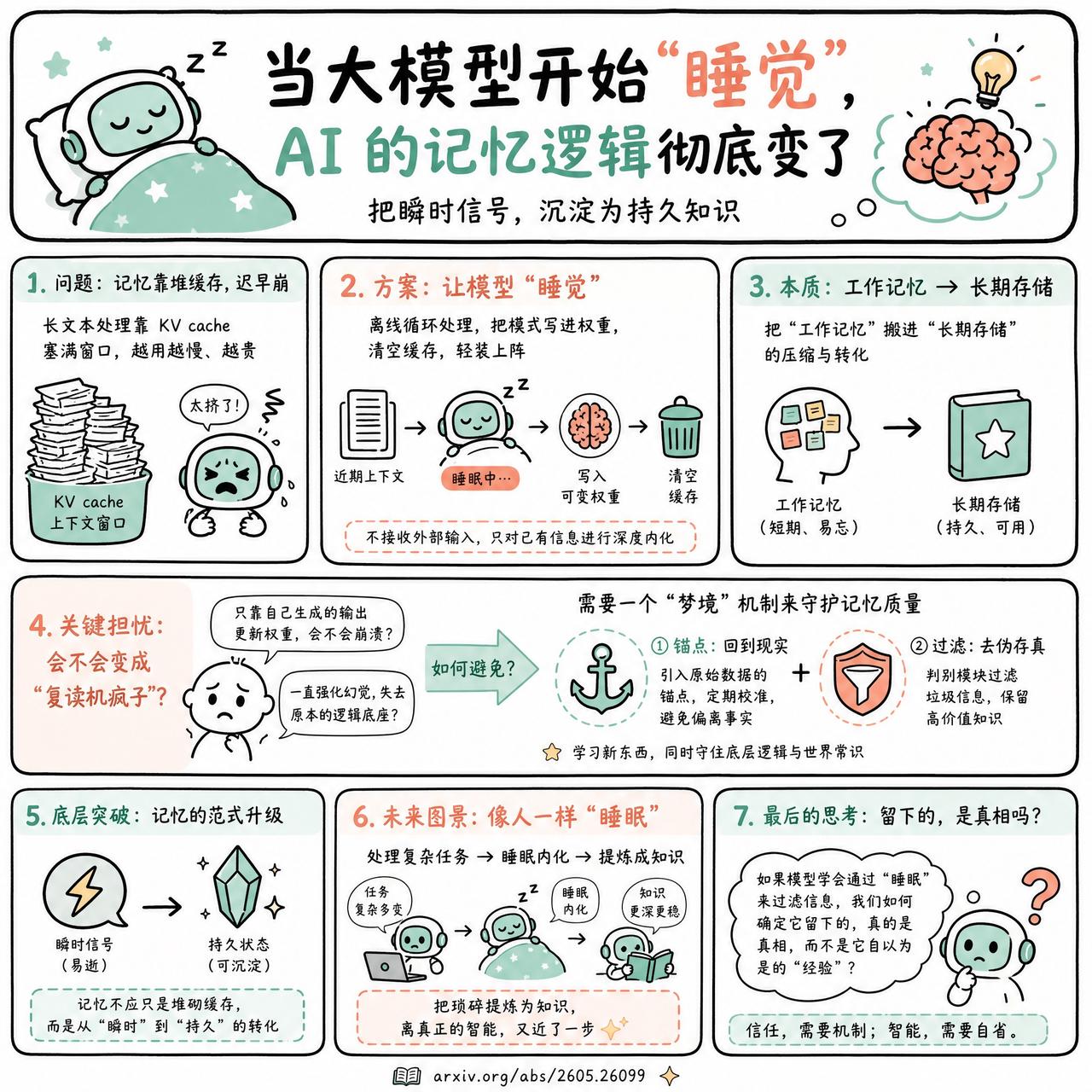
快速阅读:这篇文章讨论了一种让大模型“睡觉”的新技术:通过在离线状态下将近期上下文转化为持久的权重,来解决长文本处理的成本与记忆问题。这种机制试图模仿生物的记忆巩固过程,让模型在不增加推理延迟的情况下,实现更深层的理解。
最近看到关于“模型需要睡眠”的研究,挺有意思。
本质上,这是一种把“工作记忆”搬进“长期存储”的压缩技术。现在的模型处理长文本,全靠把 KV cache 塞进那个越来越臃肿的上下文窗口。这就像是在一个越来越挤的房间里翻找东西,效率迟早会崩掉。
这个方案的做法是:当上下文快满时,让模型进入“睡眠”模式。它不再接收外部输入,而是对着刚才攒下的这些信息进行多次离线循环处理,把有价值的模式直接写进一部分可变的权重里,然后清空缓存,重新开始。
有网友觉得这只是换了个好听的名字,说白了就是上下文压缩或离线微调。甚至有人担心,如果模型只靠自己生成的输出去更新权重,会不会导致模型崩溃,最后变成一个只会复读自己幻觉的疯子?
这种担心有道理。如果要把这个过程做成真正的“记忆系统”,大概需要一个类似“梦境”的机制:通过引入一部分原始数据的锚点,或者用一个专门的判别模块去过滤垃圾信息,才能保证模型在学习新东西的同时,不至于把原本的逻辑底座给搞丢了。
与其纠结“睡眠”这个词是不是在过度拟人化,不如看看它解决的底层问题:记忆不应该只是堆砌缓存,它需要一种从“瞬时信号”到“持久状态”的转化。
如果未来的 AI 真的能像人类一样,在处理完一天的复杂任务后,通过“睡眠”把琐碎的信息提炼成知识,那我们离真正的智能可能又近了一步。
只是,如果模型真的学会了通过“睡眠”来过滤信息,我们该如何确定它留下的,真的是真相,而不是它自以为是的“经验”?
arxiv.org/abs/2605.26099