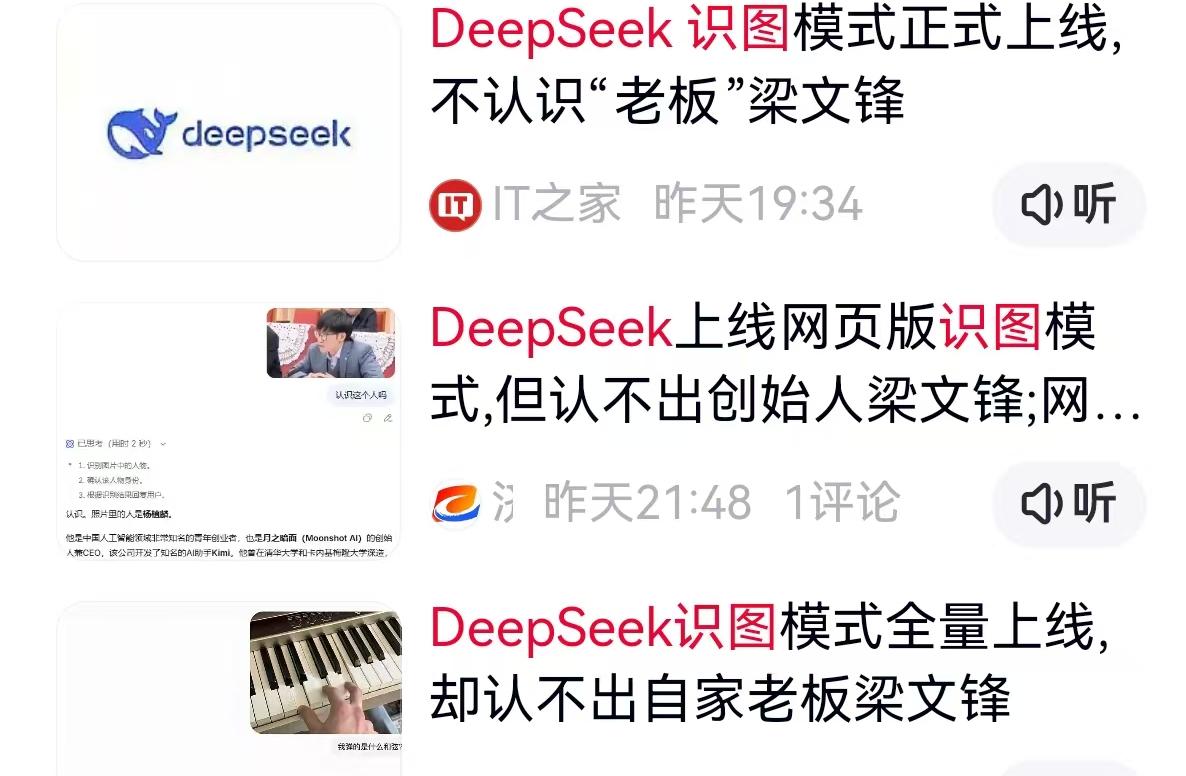
6月18日,国内AI圈爆出一个让人啼笑皆非的乌龙事件。国产大模型新锐DeepSeek的网页端及APP端悄然上新了“识图模式”,界面赫然标注着“图片理解功能内测中”。就在科技爱好者们纷纷涌入尝鲜时,记者在实测过程中却意外捕捉到了极为尴尬的一幕:系统表现极不稳定,多次将DeepSeek自家创始人梁文锋的照片,精准识别为字节跳动创始人张一鸣。
一张照片把两家头部科技公司的掌舵人张冠李戴,这事儿迅速在各大社交平台炸开了锅。网友们纷纷调侃,字节跳动没花一分钱,就在DeepSeek的桌面端刷了一波存在感。有人打趣说这AI怕不是字节派来的卧底,识图认错老板,一测把自家老板给测没了。还有人脑补了梁文锋连夜带着键盘去后台调教模型的画面,戏称合着老板白干这么多年,AI觉得做AI的都长一个样。玩笑归玩笑,这场乌龙背后,其实折射出当前国产大模型在多模态赛道上狂奔时的真实技术窘境。
仔细翻阅这两位被AI搞混的科技大佬的履历,会发现他们的人生轨迹确实存在某种微妙的平行线。张一鸣,1983年4月出生于福建省龙岩市永定区,南开大学软件工程专业毕业。他自2005年毕业后,经历过酷讯网、王兴团队饭否网的历练,在2012年1月29日开启第五次创业之旅,成立了字节跳动。从内涵段子到今日头条,再到2016年9月上线的抖音,张一鸣用算法重塑了内容分发格局。另一边的梁文锋,1985年出生在广东省湛江市吴川市覃巴镇米历岭村,浙江大学信息与电子工程学系本硕连读。2008年起,他带领团队用机器学习探索全自动量化交易,并在2015年正式成立幻方量化。2016年幻方推出首个AI模型,2020年AI超级计算机“萤火一号”投入运作,次年“萤火二号”跟上,资产管理规模突破千亿大关。2023年7月,梁文锋成立DeepSeek正式进军通用人工智能。
两人都是技术出身,都在各自领域取得了千亿级别的惊人成绩。面部特征上,戴眼镜、理工男气质的他们或许在特征向量上确有相似之处,但对于一个标榜具备图片理解能力的AI大模型来说,连自家老板都认不出,这显然不仅是长相相似就能解释的技术硬伤。
大模型的图像识别,并非像人类那样单纯依靠肉眼观察。它依靠的是海量图像数据的训练和特征提取。AI认错人,最直接的原因通常是训练数据集中缺乏梁文锋的高清图像样本,或者这些样本的权重标注不够,导致系统在遇到稍有特征的亚洲男性面孔时,自动滑向了数据量更为庞大、曝光度极高的张一鸣的特征库。这也是当前所有处于内测阶段的多模态模型常踩的坑。图像理解不仅仅是对像素的简单分类,还需要结合面部拓扑结构、上下文逻辑进行综合推理。连老板的脸都识别错,说明模型在特征细粒度抓取上还有很长的路要走。
回顾DeepSeek的发展史,这家脱胎于量化投资巨头的AI公司,在业界一直以技术极客的形象示人。2024年5月发布DeepSeek-V2,同年12月27日性能强劲的DeepSeek-V3面世。其在纯文本大模型领域的迭代速度和开源策略,赢得了极高的行业口碑。这次推出“识图模式”,显然是DeepSeek试图从单一的文本处理向多模态视觉领域迈出的关键一步。
然而,多模态领域的坑远比纯文本深得多。文本数据可以通过爬虫和开源语料库快速积累,清洗也相对容易。但图像数据需要极高的人工标注成本,涉及隐私、版权、长尾场景等复杂问题。DeepSeek在文本生成上可以靠算力和算法架构的优化实现弯道超车,但在视觉理解这条赛道上,面临的对手不仅有深耕多年的字节跳动,还有国内外众多早已积累海量视觉数据的科技巨头。
这场认错老板的乌龙,给狂热的AI行业浇了一盆理性的冷水。对于普通用户而言,这也算是一次极好的科普机会:无论发布会上的演示多么酷炫,大模型的能力边界依然存在。AI的进化不是变魔术,而是靠无数次试错、数据喂养和参数调整堆出来的。内测阶段的功能不稳定是常态,我们既要包容技术的成长性,也要保持审慎的目光,不盲从、不迷信。
对于DeepSeek来说,这次事件虽然尴尬,但也提供了一次难得的真实压力测试。用户的群嘲恰恰是对产品最直接的反馈。补齐数据短板,优化视觉算法,把老板的脸认准,只是万里长征的第一步。如何在保证文本优势的同时,打通视觉与语言的壁垒,实现真正的多模态理解,才是决定其能否在下一轮AI洗牌中存活下来的关键。技术的道路从来没有捷径,连夜调教键盘的段子背后,注定是研发团队无数个不眠之夜的硬核攻坚。
以上内容仅供参考和借鉴