【一文读懂】端到端、VLA、强化学习、世界模型怎么理解?
香港大学 Hongyang Li 在 CVPR 2025 WAD 上这篇报告,我觉得算是讲清楚了:《End-to-end Autonomous Driving: Past, Current and Onwards》。
翻译过来就是《端到端自动驾驶技术的前世今生》。
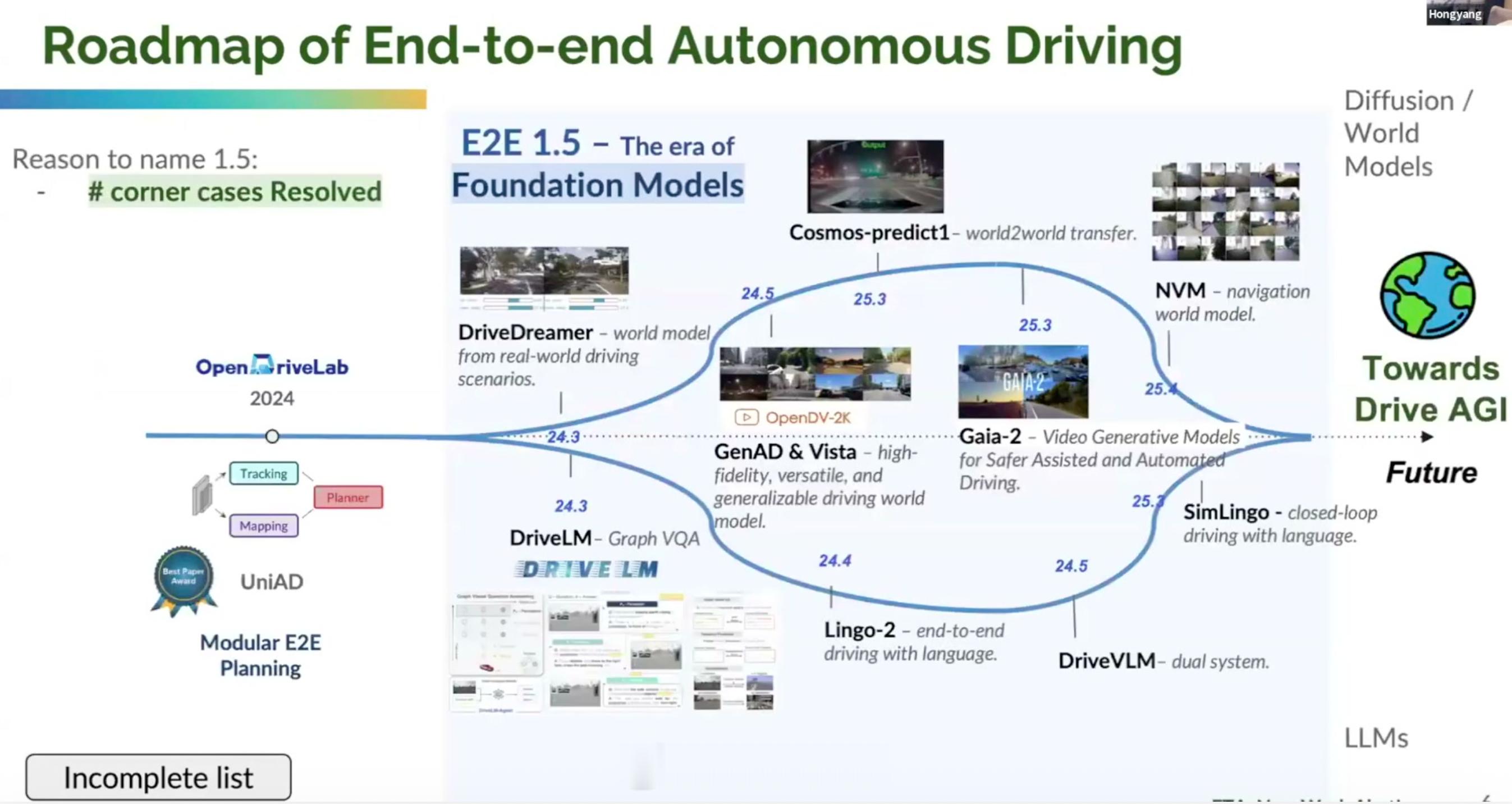
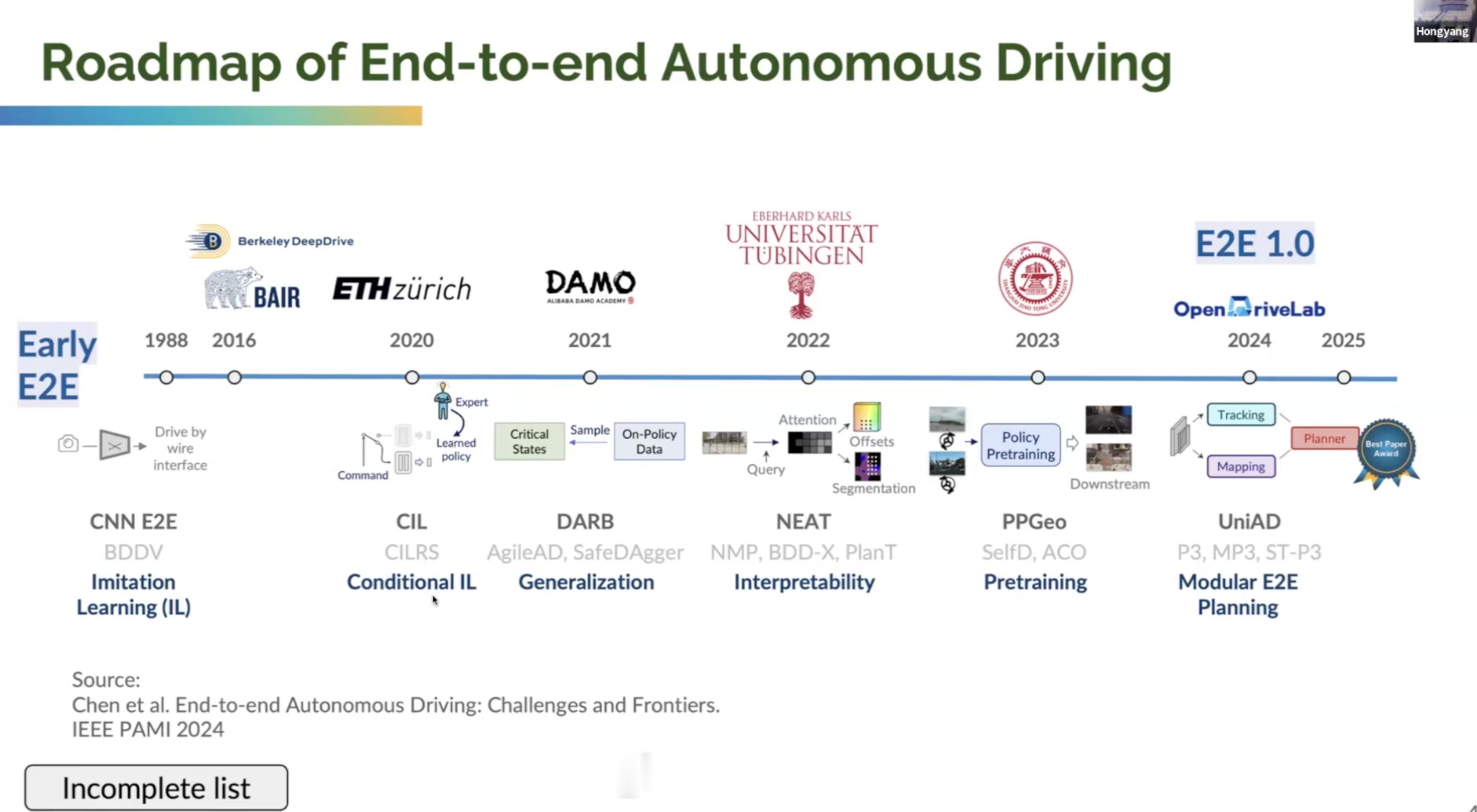
重点在于第3张图: 他把 UniAD 这一类工作放在端到端早期阶段,也就是 Modular E2E Planning;再往前,是面向 Drive AGI 的 World Engine,也可以理解为端到端自动驾驶 2.0。
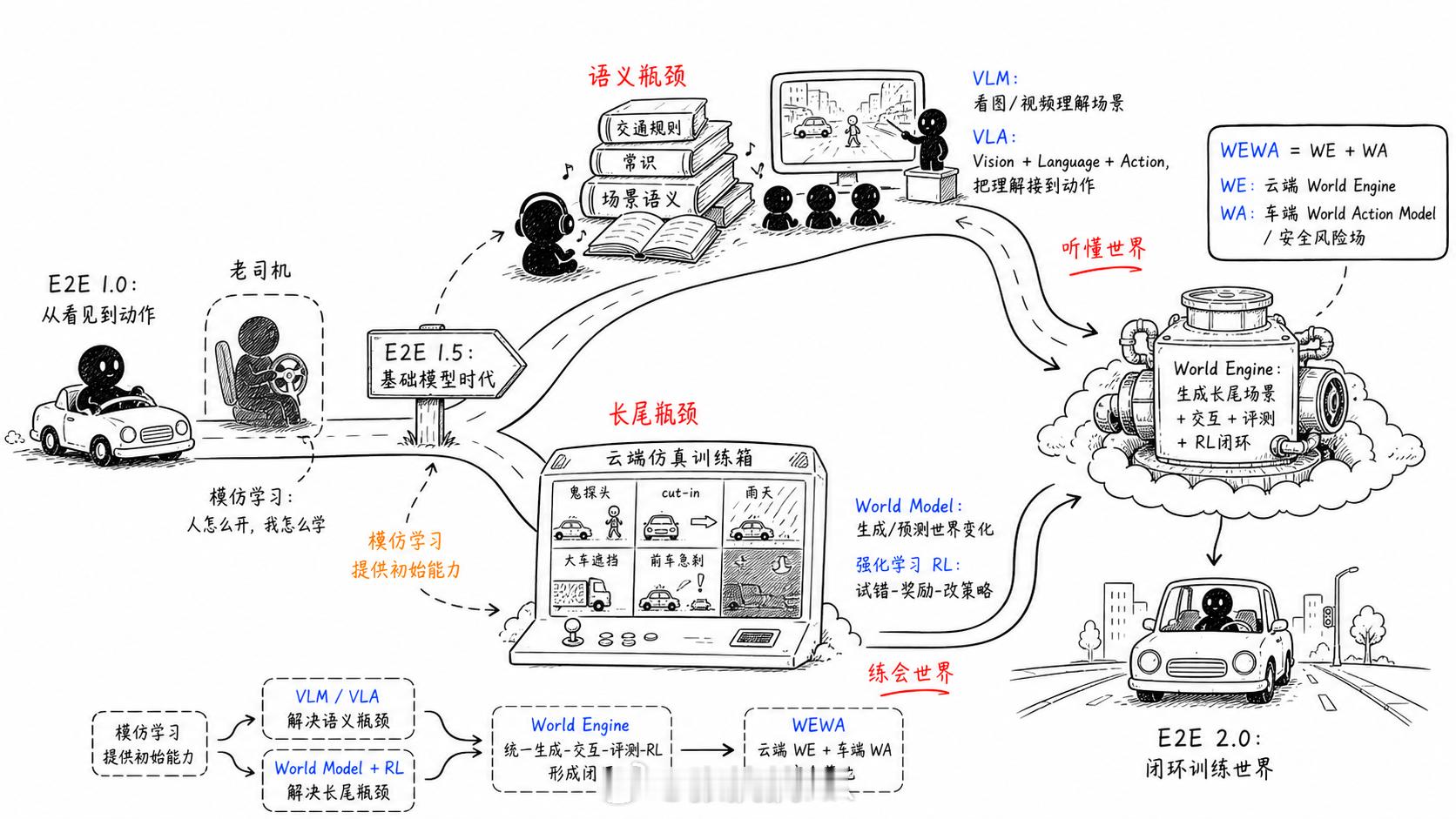
早期端到端1.0主要靠什么训练:模仿学习。简单说,就是人类司机在这个场景下怎么开,模型就学着怎么开。它解决了从“看见世界”到“做出动作”的映射问题,但也留下两个麻烦:第一,人类司机未必总是最优;第二,真实数据里低频高危场景太少。
那么我们必须往前走,也就到了现在的1.5 阶段:Foundation Models 基础模型时代。
1.5时代面临两个技术难题,分别是语义瓶颈和长尾瓶颈。
两个技术难题都需要解决,但各家着手的重点不同,于是就衍生出不同技术路线。这也是为什么现在行业里术语特别多:VLA、VLM、世界模型、强化学习、端到端、World Engine……如果大家都一样,那就相安无事,也懒得天天讲;正因为各不相同,才需要反复讲,讲自己的优势在哪里。
这让我想起量子力学的故事:海森堡搞矩阵力学,薛定谔搞波动力学,两套理论创立初期语言、思路完全割裂,两派还激烈争论。1926 年薛定谔率先从数学上论证二者可以互相推导、观测结果完全一致。那篇论文的名字很霸气,我还记得:《论海森堡-玻恩-约尔丹量子力学与我的量子力学之间的关系》。
回到智能驾驶,也是这样:
第一条路线,是先解决语义瓶颈,也就是 LLM / VLM / VLA 这一支。
它试图把语言、常识和高层语义接进驾驶模型。如此一来,车就能“听老司机讲”、“上网刷事故视频”、读交通规则,从人类积累下来的经验里补课。
它自己也许从没经历过某个 corner case,但听说过、看过、理解过,下次真遇到时,总归会好一些。也就是说,以前端到端都是在数据中自己练,现在让他识字允许他上网听老司机讲安全驾驶了,那理论上进步是快不少。
就我个人体验来说,学完车之后前10000公里主要就是自己练,后来意识到自己的一些驾驶行为多么危险,惊出一身冷汗,就主动去刷视频学学防御性驾驶技巧。某种意义上来说,这就是我本人从模仿/强化学习阶段进入了VLA阶段。
第二条路线,是先解决长尾瓶颈,也就是世界模型与强化学习这一支,并进一步走向 World Engine。
这里要注意,World Model 和 World Engine 不是同一个词。前者更像后者的一个组件。比如蔚来 NWM 说的是 Nio World Model;华为乾崑 WEWA 里的 WE,则是 World Engine,完整架构是 World Engine / World Action Model。
这条路线的思路是:先别让我识字,也别急着让我听老司机讲课,而是给我构建一个极为逼真的极品飞车游戏,让我天天在里面练。练 10 万公里、100 万公里,效果未必比上网刷题差。
既然是练,就有成功、有失败。正确的动作强化一下,错误的动作下次别犯,这就是强化学习(Reinforcement Learning,RL)
回想那些 80 年代就拿驾照的老司机,他们哪有条件上网刷题?没办法,纯靠自己练,也能练成老司机,甚至经验更老道。毕竟很多时候,听来的不如练出来的。
但这种练法有两个问题:一是,练出事故了怎么办?二是,现实世界练 10 年太慢了怎么办?
这就是 World Model / World Engine 要解决的事:让你进入一个虚拟世界,在里面撞车也不伤现实肉身,就像《明日边缘》里的汤姆克鲁斯一样;让你进入一个“一秒万年”的训练场,在里面练了一万年,回到现实世界也只是1秒。
VLA 通过学习老司机来提升水平,World Engine 通过更安全、更高效的强化学习试错来提升水平。一个补语义,一个补经验;一个像读书听课,一个像下场训练。端到端 1.5 之所以必然分岔,就是因为它同时被这两个瓶颈拉扯:既要更懂世界,又要更会处理没见过的危险。
根据Hongyang Li教授的观点,真正的 2.0可能不是二选一。所以你会看到现在搞VLA的,也开始提到强化学习、世界模型这些概念了。
这次讲的,大家能看懂吗? 可以评论区指出讲得不好的地方,我继续展开。按原计划,下期就讲“世界模型”的差异 —— 都是世界模型,水平可能差距很大!世界模型WEWAVLA