DeepSeek V4 双版本精简解读(适配研发AICoding降本)
一、两大版本定位
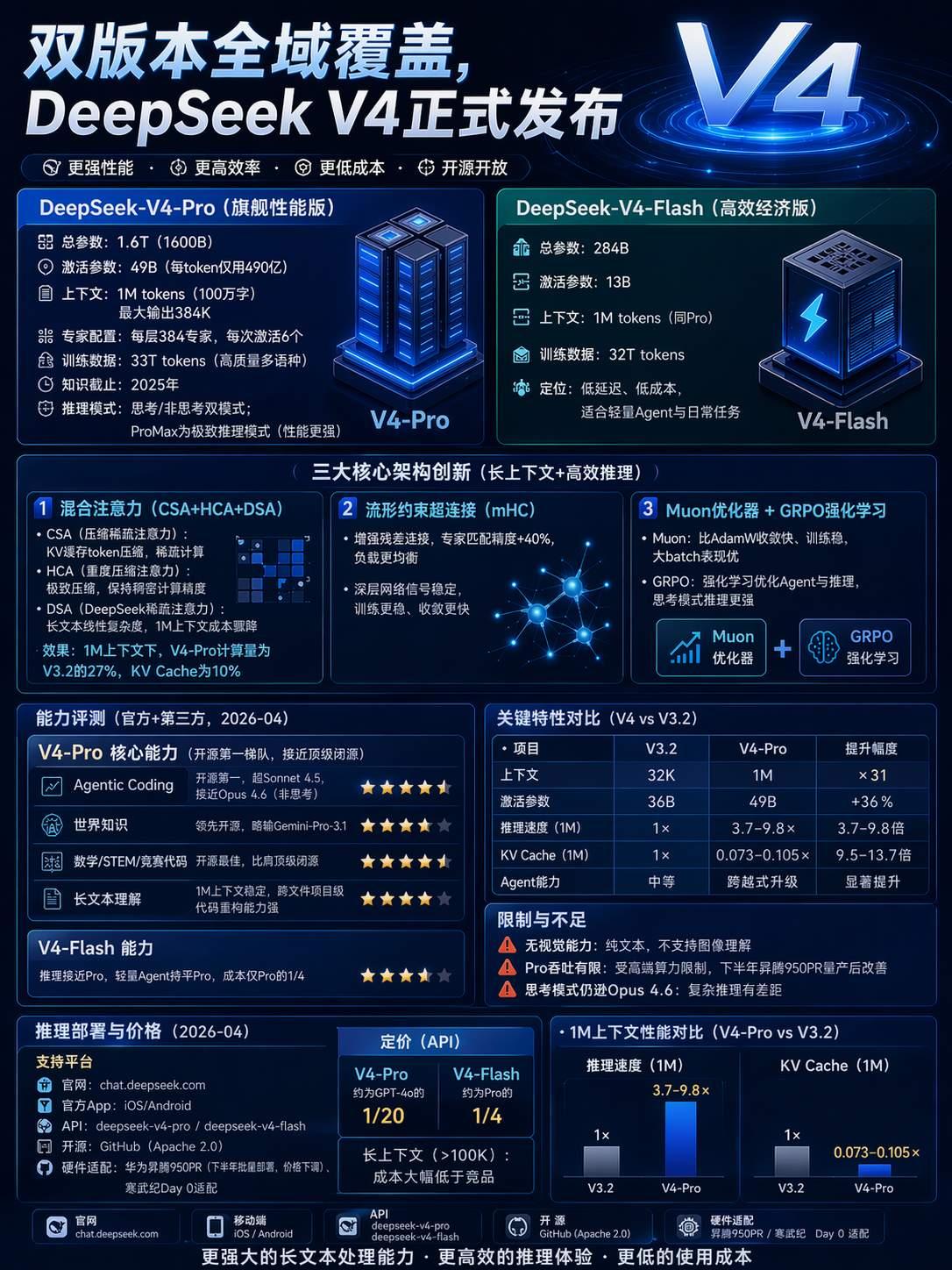
1. V4-Pro(旗舰高性能版)
- 参数:总1.6T,激活49B,原生1M上下文,单次最大输出384K
- 优势:Agent代码、数学竞赛、百万字长文档推理开源第一梯队,性能对标顶级闭源模型
- 定价:仅GPT-4o价格1/20,搭配DSpark推理加速,吞吐再提升60%-85%
2. V4-Flash(高效经济版)
- 参数:总284B,激活13B,同样支持1M上下文
- 优势:推理能力接近Pro,成本仅Pro的1/4;适合日常编码、批量Agent自动化任务
- 定位:中小研发团队主力日常算力选型
二、三大核心架构升级(直接降低Token消耗)
1. 混合注意力CSA+HCA+DSA
1M上下文算力仅V3.2的27%,KV缓存占用压缩至原先10%,长会话不会快速耗尽显存、减少重复计费
2. mHC流形约束连接
长任务匹配度提升40%,循环推理收敛更快,减少Agent无效重试轮次
3. Muon优化器+GRPO强化学习
Agent自主规划、代码调试稳定性大幅提升,搭配DSpark投机解码,同等代码任务算力开销大幅下降
三、核心对比优势(对标旧版V3.2)
1. 上下文从32K拉满至1M,扩容31倍,完整加载大型项目无需拆分会话
2. 1M长文本推理速度提升3.7~9.8倍,KV缓存效率提升9.5~13.7倍
3. Agent能力跨越式升级,代码基准超越Sonnet 4.5,接近Opus 4.6水平
四、成本落地价值(解决你们周5万算力、单日3万充值烧空痛点)
1. 价格碾压海外闭源
V4-Pro单价仅GPT-4o的1/20,Flash仅Pro的1/4,对比Opus 4.8成本差距可达1/10量级,远超GLM-5.2的1/6成本优势
2. DSpark推理加速叠加降价双重收益
同等代码开发量,算力支出直接压缩70%以上,6人研发团队周5万开支可压到万元以内
3. 原生1M上下文+极低KV开销
处理完整代码仓库不用频繁新建会话,消除长上下文Token雪球爆炸;动态置信度调度自动丢弃低可信度草稿,杜绝无效算力浪费
4. 开源可私有化部署
依托华为昇腾950/寒武纪硬件,脱离海外API按量充值模式,彻底规避单日大额透支失控
五、短板提醒
1. 纯文本模型,无原生多模态图文能力
2. 思考模式综合推理略弱于Opus 4.8,极致复杂架构设计可少量兜底搭配海外模型
3. Pro吞吐依赖昇腾950规模化产能,短期小批量部署成本偏高
DeepSeek V4 AI代码研发降本 1M上下文大模型 DSpark推理加速 国产平替Opus deepsip Deepa DeepPHY DeepPDF ai4cfd deeplab ai版crm