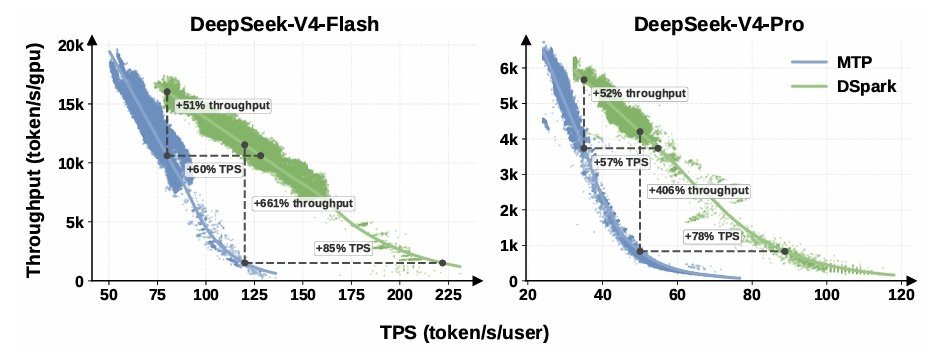
DeepSeek发布DSparkDeepSeek 今日联合北京大学正式发布 DSpark 推理加速框架,针对性解决大语言模型在高并发生产环境中的『推理效率瓶颈』。该框架已部署于 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 预览版,同等吞吐量水平下可将单用户生成速度提升 60% 至 85%。
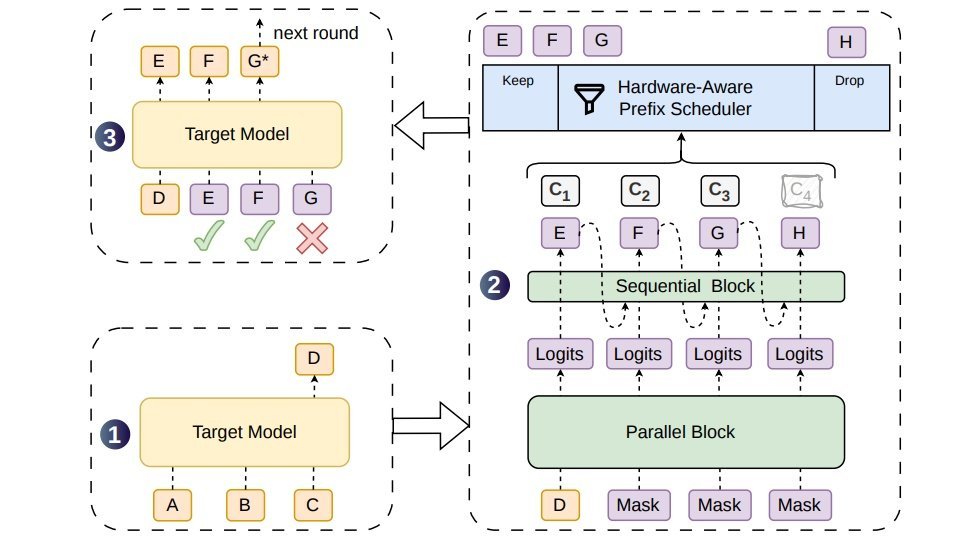
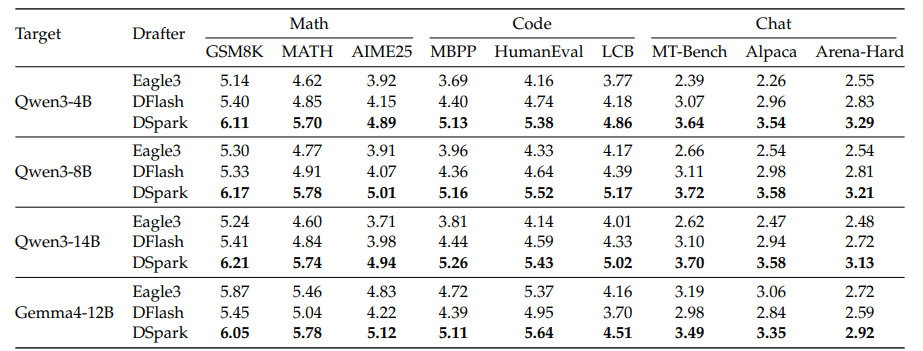
据官方介绍,大语言模型自回归生成的特性决定了每生成一个新 token 都需要一次完整前向传播,推理延迟随输出长度线性增长,是当前 AI 对话响应偏慢的核心原因之一。推测解码技术通过小模型生成候选 token、大模型单次并行验证的路径,可在无损生成质量的前提下提速,但实际加速效果受候选生成质量与验证阶段算力占用两大约束。当前主流方案分为两派,自回归式草稿模型如 Eagle3 逐 token 串行生成候选,接受率高但延迟随候选长度线性增长,实际部署只能采用短候选块与浅层网络;并行式草稿模型如 DFlash 单次前向传播产出全部候选,延迟几乎与候选长度无关,但后缀 token 接受率衰减明显,高并发场景下固定长度验证还会浪费批量处理能力,拉低整体吞吐量。DSpark 针对上述两个瓶颈设计了两项互补机制。候选生成阶段采用半自回归架构,由改进后的并行主干网络一次性产出全部候选位置的隐藏状态与基础 logits,再通过轻量级顺序模块逐 token 注入前缀依赖信息,提供马尔可夫头与 RNN 头两种实现方式,仅两层 Transformer 深度即可在测试领域超过五层 DFlash 的接受长度,参数效率优于单纯堆叠并行层。验证调度阶段引入置信度调度验证机制,先校准各位置 token 的存活概率置信度,再由硬件感知前缀调度器以全局吞吐量最大化为目标,为每个并发请求动态决定验证前缀长度,优先将算力分配给存活概率最高的 token。生产部署方面,DSpark 草稿模型并行主干包含三个 MoE 层与滑动窗口注意力,最大候选块长度设为 5,采用马尔可夫头作为顺序模块。训练与落地方面,团队做了多项针对性优化:训练阶段并行训练时仅传递目标模型的隐藏状态而非完整词表 logits,将通信复杂度从 O(V) 降至 O(d),同时采用锚点定长序列打包策略,避免传统填充带来的计算与内存开销;系统集成阶段针对 CUDA 图重放要求将调度器改为异步模式,通过历史置信度预测截断长度隐藏调度延迟,同时解耦物理执行与逻辑序列跟踪,将所有 token 展平为独立元素处理,解决动态变长验证的内核利用率问题。DSpark 也存在一定局限,对于接受率较低的复杂查询,并行主干生成完整候选块的草稿计算开销无法回收。
目前 DeepSeek 已在 GitHub 的 DeepSpec 项目中开源了 DSpark、DFlash、Eagle3 三种草稿模型的训练代码、评估脚本及模型检查点。