以往的做法要么靠工程师拍脑袋决定一个固定的稀疏度(比如盲猜剪掉50%),要么靠极其昂贵的超参数搜索和逐层微调。来自佛罗里达大学和俄亥俄大学的研究人员提出了「有效模型剪枝」(EMP, Effective Model Pruning)。论文《Effective Model Pruning: Measure The Redundancy of Model Components》
解决了一个长期困扰大模型压缩的核心痛点:在给定了参数重要性评分后,到底该切掉多少参数才能既瘦身又不崩!
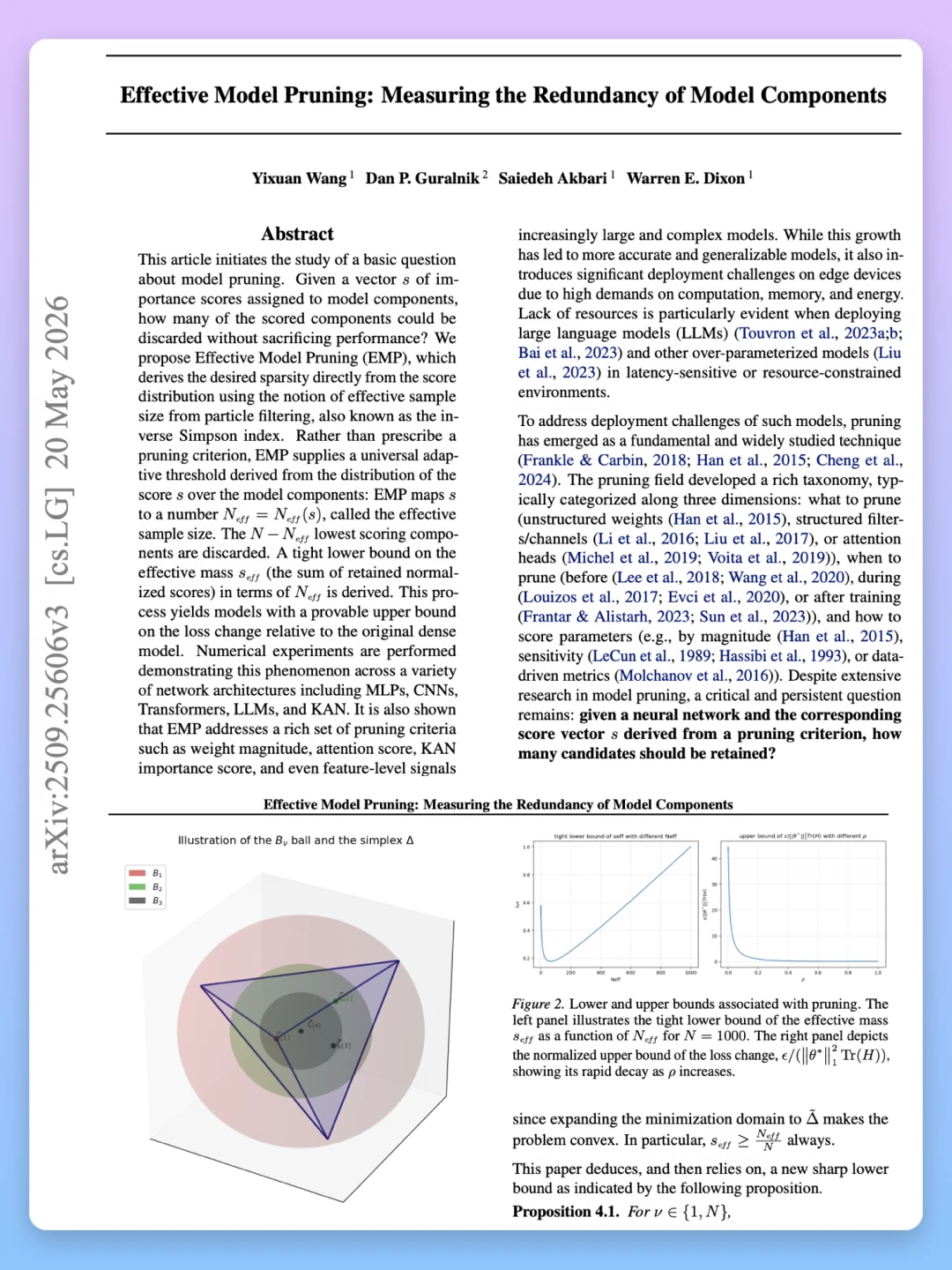
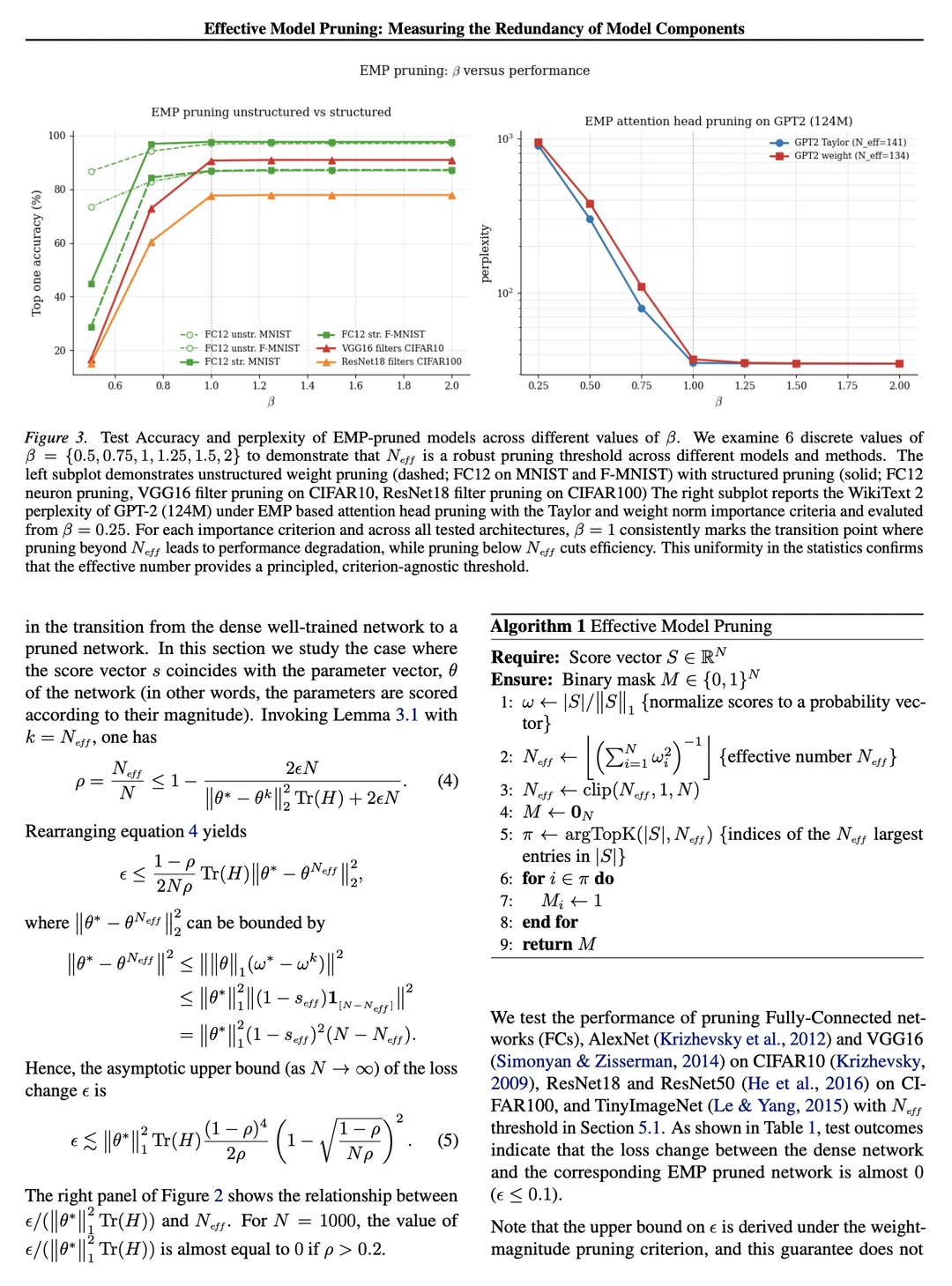
EMP 借用粒子滤波里的“有效样本大小”(effective sample size,也叫逆辛普森指数)概念。给模型各部分打重要性分数(score)后,直接从分数分布算出N_eff——代表真正有贡献的部分数量。只保留分数最高的N_eff个,其余直接丢掉。
它不依赖具体打分方法(magnitude、attention score、激活感知等都行),也不用手动调稀疏度预算或逐层调参。论文还给出理论保证:保留分数的总质量(effective mass)有紧下界,模型性能损失(loss change)有可证明的上界。
实验覆盖MLP、CNN、Transformer、LLM、KAN等多种架构,效果接近原始稠密模型。
亮点:
🔸通用自适应:任何重要性分数向量都能直接转成剪枝阈值,无需超参调优或迭代搜索。
🔸理论+实践结合:既有数学界限保障,又在实际网络上验证,剪枝后性能稳健。
🔸灵活适用:支持权重、注意力头、甚至像素级特征剪枝,适合边缘设备和大型模型压缩。
🔸实验显示,用EMP规则剪枝的模型,在各种标准下保持高准确率,同时大幅降低计算量。
总体来说,EMP把“该留多少”这个老难题变成一个基于分数分布的直观计算,让模型压缩更简单可靠,特别适合资源受限场景下的实际部署。
深度学习模型压缩与端侧部署工程师,以及KAN、Mamba等新型架构研究者,这篇工作值得列入你们的必读清单。