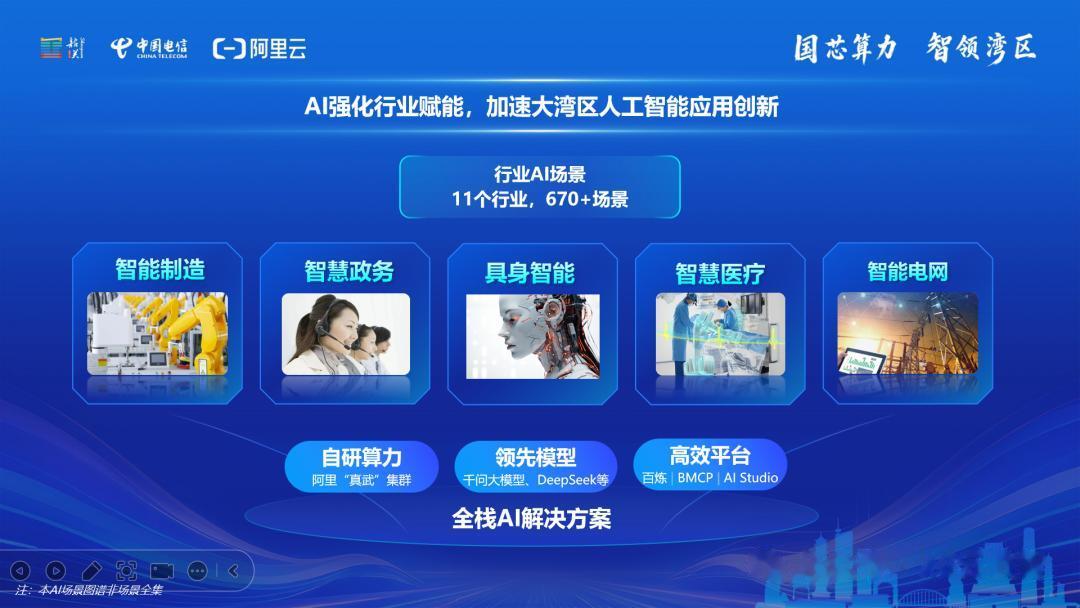
4月7日,中国电信粤港澳大湾区智能算力中心,正式上线了区域内首个阿里真武AI芯片万卡智算集群。

这不仅是技术突破,更是中国电信与阿里云强强联合的成果,中国电信提供韶关数据中心、算网调度与政企渠道,阿里云提供真武芯片与全栈AI云技术。
双方能力互补,一举破解了国产算力的三大核心痛点。
痛点一:万卡组网协同难
过去,国产AI芯片想要搞万卡集群,最大的拦路虎是大规模组网的协同能力。
一万张卡同时干活,就像一万个人同时在一个会议室里说话,谁都在讲,谁也听不清。结果是:通信延迟高、网络拥堵、算力利用率断崖式下跌。很多国产万卡集群,理论算力很高,实际跑起来连一半性能都发挥不出来。

真武万卡集群怎么破?
采用新一代高性能组网架构,端到端数据传输时延低至4微秒,网络峰值利用率超过95%。
这是什么概念?4微秒相当于人眨眼时间的五万分之一,数据卡与卡之间“对话”几乎零延迟。95%的网络利用率意味着几乎没有浪费,每张卡都在高效干活。
集群可以稳定承载千亿参数级大模型的训练与推理任务。过去只有NVIDIA的顶级集群才能做到的事,真武做到了。
痛点二:生态适配难
国产芯片的另一个“劝退”点是生态。
开发者习惯了PyTorch、TensorFlow,习惯了CUDA。换成国产芯片,往往要重新编译、重写算子、调试驱动,一个模型迁移过来,少则一周,多则一个月。很多团队直接放弃。

阿里云表示,真武AI芯片已全面适配主流AI框架与工具链,提供统一编程接口。开发者无需重写代码,即可平滑迁移业务。
味着你今天在NVIDIA上跑的模型,明天就能直接搬到真武集群上,而且性能不打折。生态兼容这道“天堑”,被填平了。
痛点三:性能与成本平衡难
过去国产芯片要么便宜但性能拉胯,要么性能勉强但价格不便宜。想要大规模商用复制,性价比始终算不过账。
真武万卡集群给出了一个漂亮的答案:既要性能,又要降本。

依托全栈技术协同优化,集群单卡吞吐性能较传统部署模式提升9.3倍,单机每秒Token生成量提升近10倍。同时,单位算力和电力成本大幅下降。
9.3倍的性能提升,意味着原来需要10张卡干的活,现在1张卡就够了。电力成本、机房空间、散热成本全部跟着降。
这正好契合了运营商和政企客户最核心的需求:规模化、高性价比、可复制。
目前,该集群算力已上架广东电信“算力超市”,面向中小企业提供按卡、按小时计费的零售服务。阿里云宣布预计扩容至10万卡规模,万卡是能力验证,10万卡则敲定大规模商用规划。
真武万卡集群的落地,标志着国产AI算力从“单点突破”走向“系统作战”。中国电信的基建与渠道能力,加上阿里的芯片与云技术,共同构建了自主可控、高性价比的算力底座。
当然,我们也要清醒:10万卡集群的长期稳定性、运维经验、与NVIDIA的全面对标,仍需时间检验。
欢迎关注~
洞见通信脉络,解码数字未来
数据图片来源网络侵删
【纵目新媒体矩阵】
头条号|百家号|微博
微信公众号|搜狐号|视频号