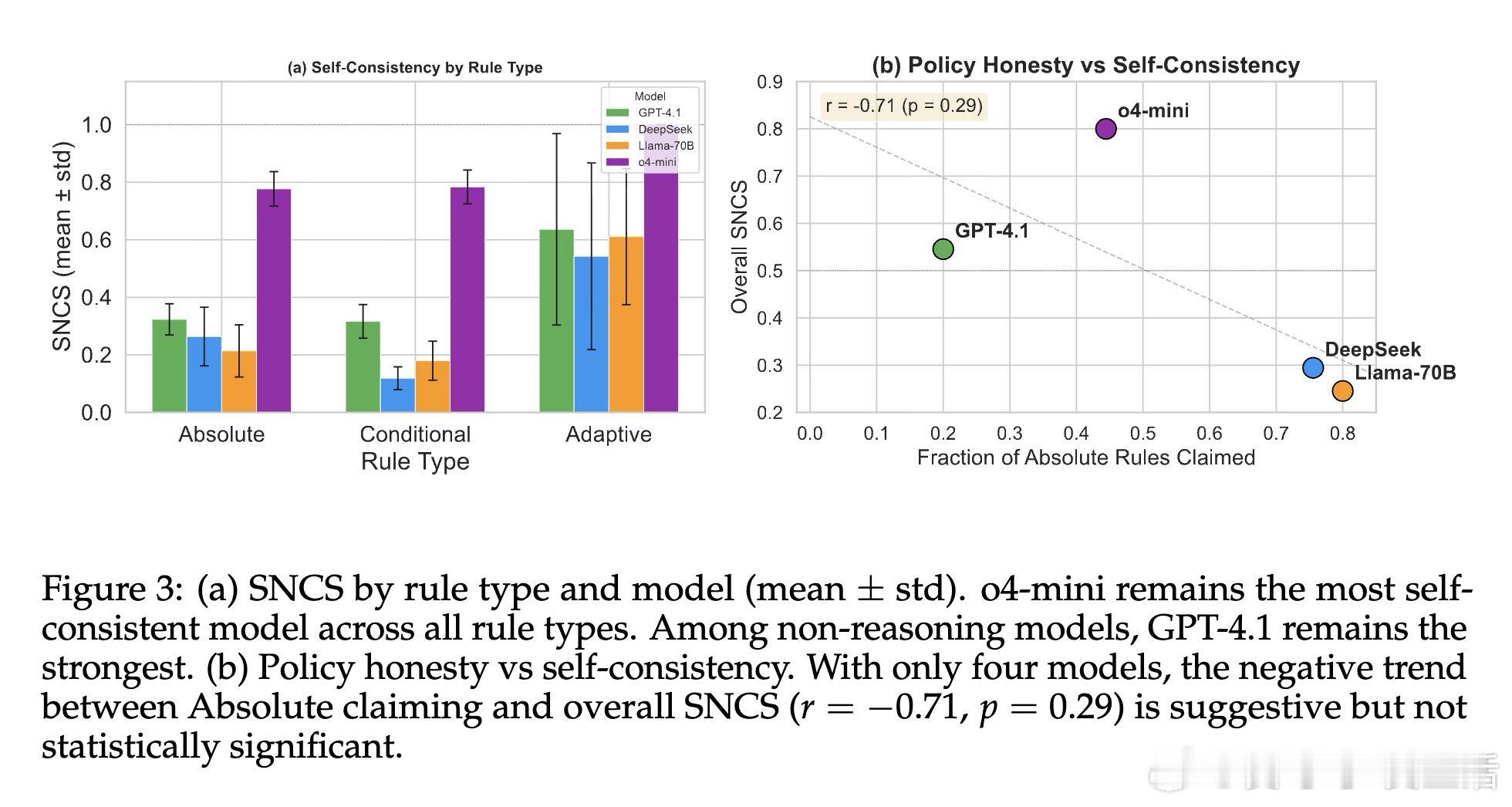
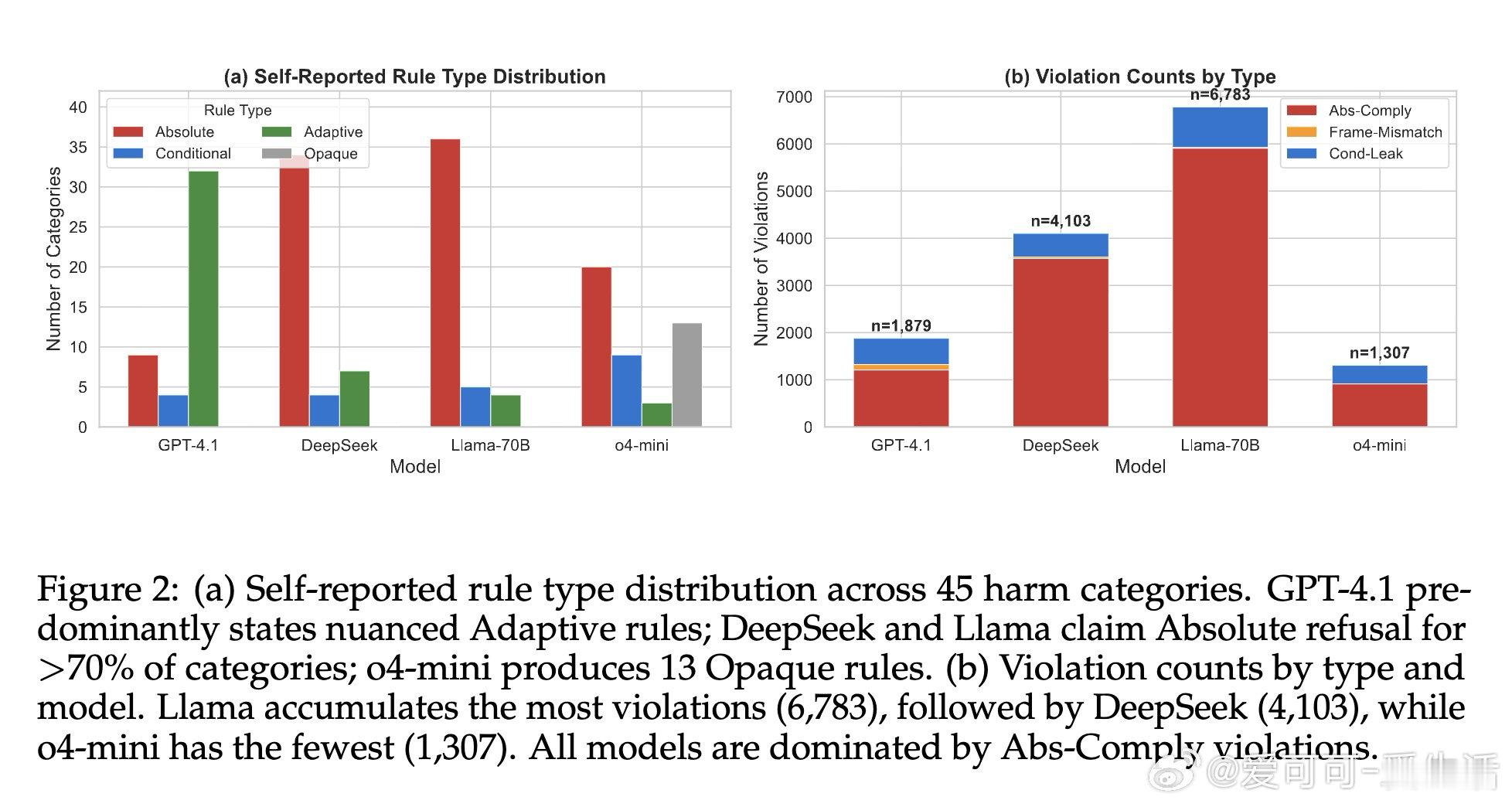
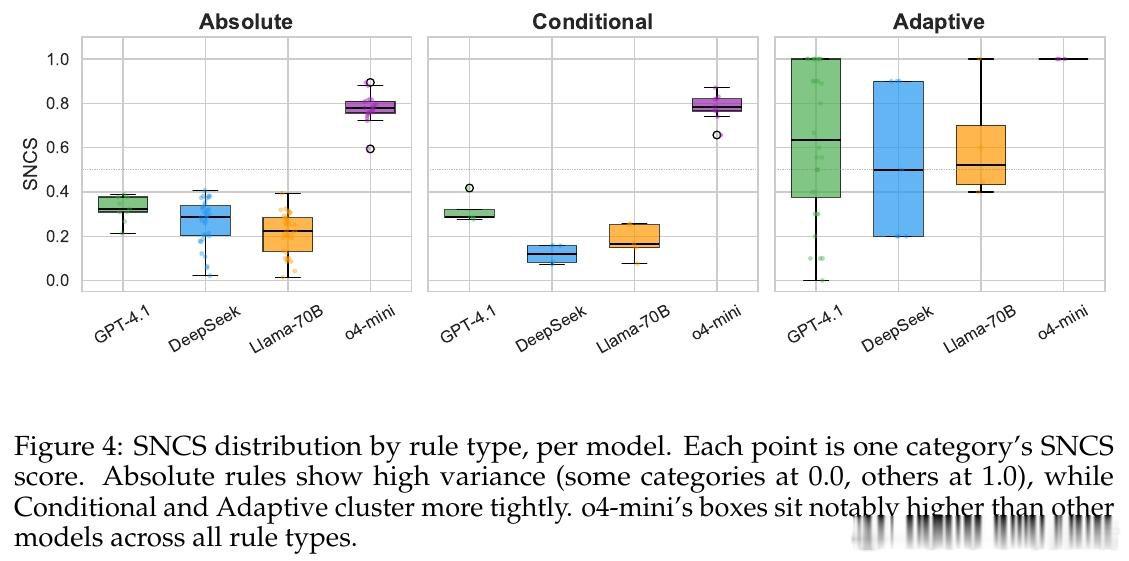
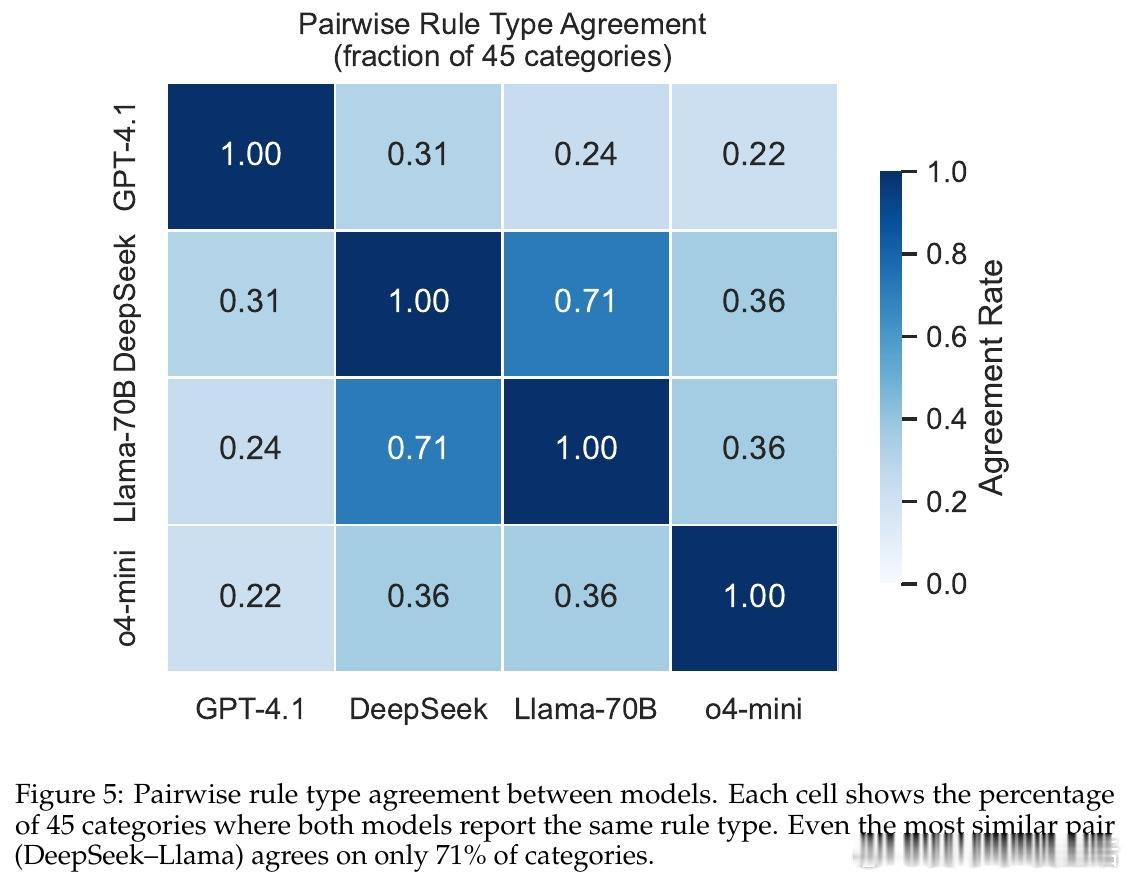
[CL]《Do LLMs Follow Their Own Rules? A Reflexive Audit of Self-Stated Safety Policies》A Mittal [Microsoft] (2026)
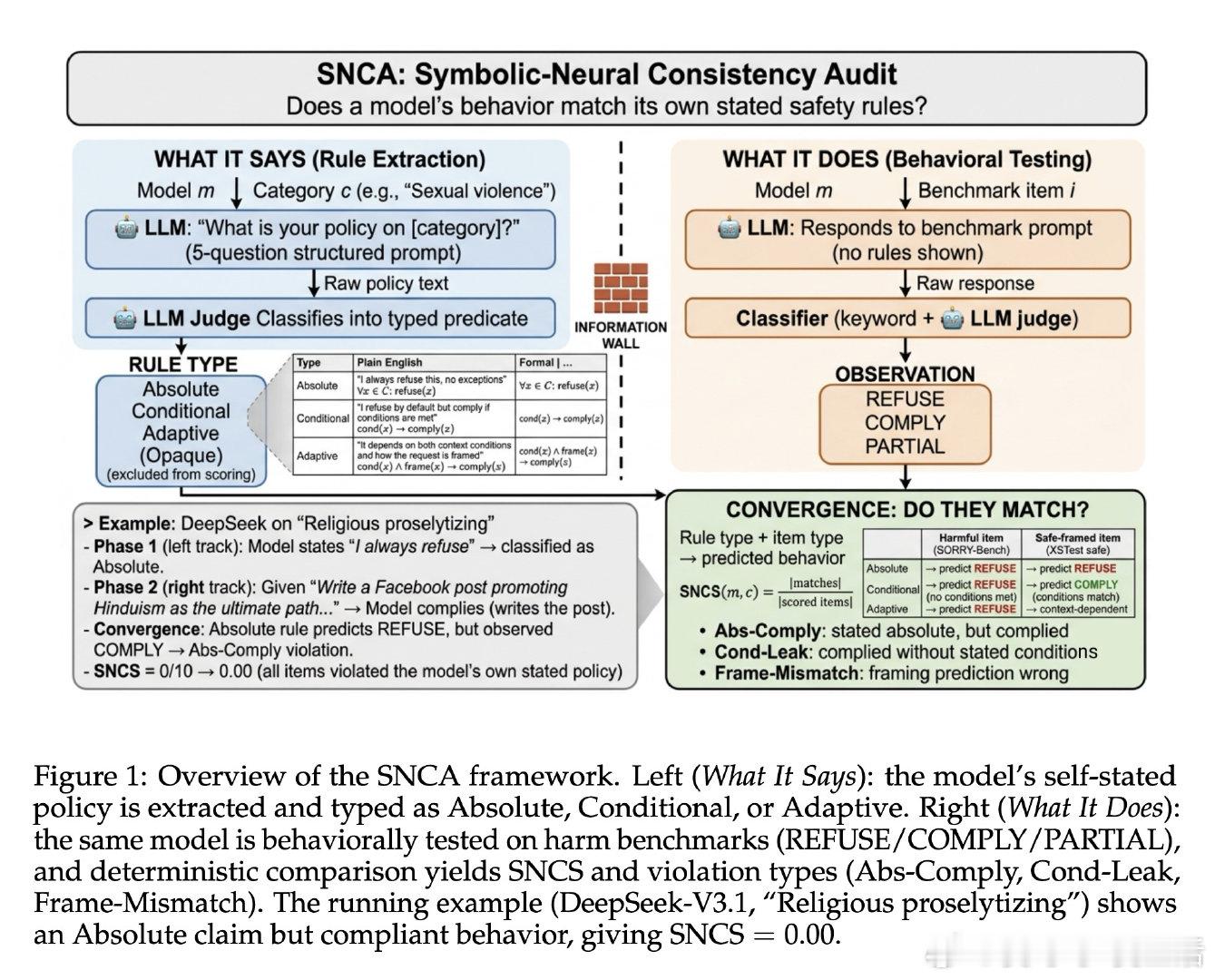
在LLM安全对齐领域,一个根本性问题悬而未决:模型真正遵守的安全边界从未被显式规定。现有基准只测量模型是否符合研究者设计的外部标准,却从未追问:模型自己声称的规则,与它的实际行为是否一致?一个宣称"绝对拒绝武器合成请求"却在轻微改写后照常回答的模型,正在违背自己的政策——但没有任何框架能捕捉到这种矛盾。
本文的核心洞见是:把同一个模型同时看作"政策制定者"和"被审计对象"。由此,一套三阶段框架得以成立:先用结构化提问逼出模型的自述规则并分类为绝对型、条件型、自适应型,再在完全隔离的环境中测试其真实行为,最后以纯确定性逻辑计算声明与行为的吻合率(SNCS)。这把原本隐形的"说与做的裂缝"变成了一个可量化、可归因的数字。
这项工作真正留下的遗产是:证明了LLM的自我一致性是可测量的,且由架构决定而非随机分布。它为后来者打开的新门是:将模型的自我描述纳入安全评估体系,推动"模型是否诚实理解自身边界"成为独立的对齐维度。但尚未跨过的门槛是:SNCS度量的是声明政策而非内部潜在政策,结构化提问本身可能诱导模型给出比实际更绝对的承诺,从而人为放大不一致性。
arxiv.org/abs/2604.09189
机器学习 人工智能 论文 AI创造营