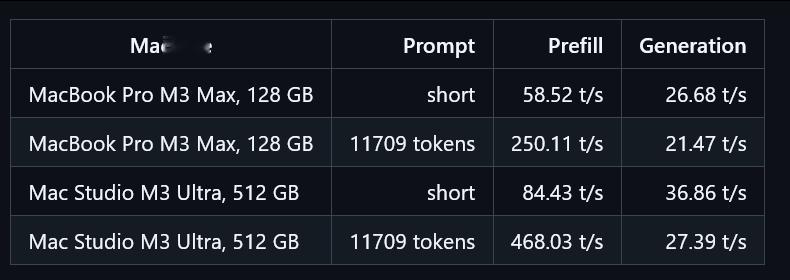
antirez发布了DeepSeek V4 Flash专用的推理引擎地址:github.com/antirez/ds4之前提过他在做这个工作。现在项目正式发布了--一个专门为DeepSeek V4 Flash定制的推理引擎。仅适用于苹果Metal芯片,跑项目特制的量化模型(有q2、q4两个版本),q2可以在128g内存上运行。速度如图。
antirez特别解释了下q2量化也运行良好:“这里提供的 2-bit 量化并不是开玩笑:它们表现良好,可以在编程智能体下工作,并且能够可靠地调用工具。2-bit 量化采用非常不对称的量化方式:只有 routed MoE experts 被量化,其中 up/gate 使用 IQ2_XXS,down 使用 Q2_K。这些部分占据了模型空间的大多数;其他组件,包括 shared experts、projections、routing,则保持不变,以保证质量。”
关于为什么要给DeepSeek V4 Flash定制一个引擎,antirez是这么说的:“因为在将它与一些强大的较小型稠密模型进行比较后,我们可以这样说:
🌟DeepSeek V4 Flash 更快,因为它的活跃参数更少。🌟在思考模式下,如果避免使用最大思考长度,它生成的思考部分会比其他模型短得多,在很多情况下甚至只有其他模型的五分之一。更关键的是,思考部分的长度与问题复杂度成正比。这使得 DeepSeek V4 Flash 在启用思考的情况下仍然可用,而在相同条件下,其他模型实际上几乎无法使用。🌟该模型拥有 100 万 token 的上下文窗口。由于模型规模很大,当你在知识边缘进行采样时,它知道的东西更多。例如,询问意大利问题时,很快就会发现,284B 参数确实比 27B 或 35B 参数多得多。🌟它的英语和意大利语写作要好得多。🌟它给人的感觉近似于前沿模型。🌟KV 缓存压缩得非常厉害,使得本地计算机上的长上下文推理以及磁盘上的 KV 缓存持久化成为可能。🌟如果以特殊方式量化,它在 2-bit 量化下表现良好(后文会说明)。这使得它可以在配备 128GB 内存的 MacBook 上运行。🌟我们预计 DeepSeek 未来会发布更新版本的 V4 Flash,表现甚至会比当前版本更好。”AI创造营How I AI