SWE-Bench 2026.5 全球大模型代码能力榜解读
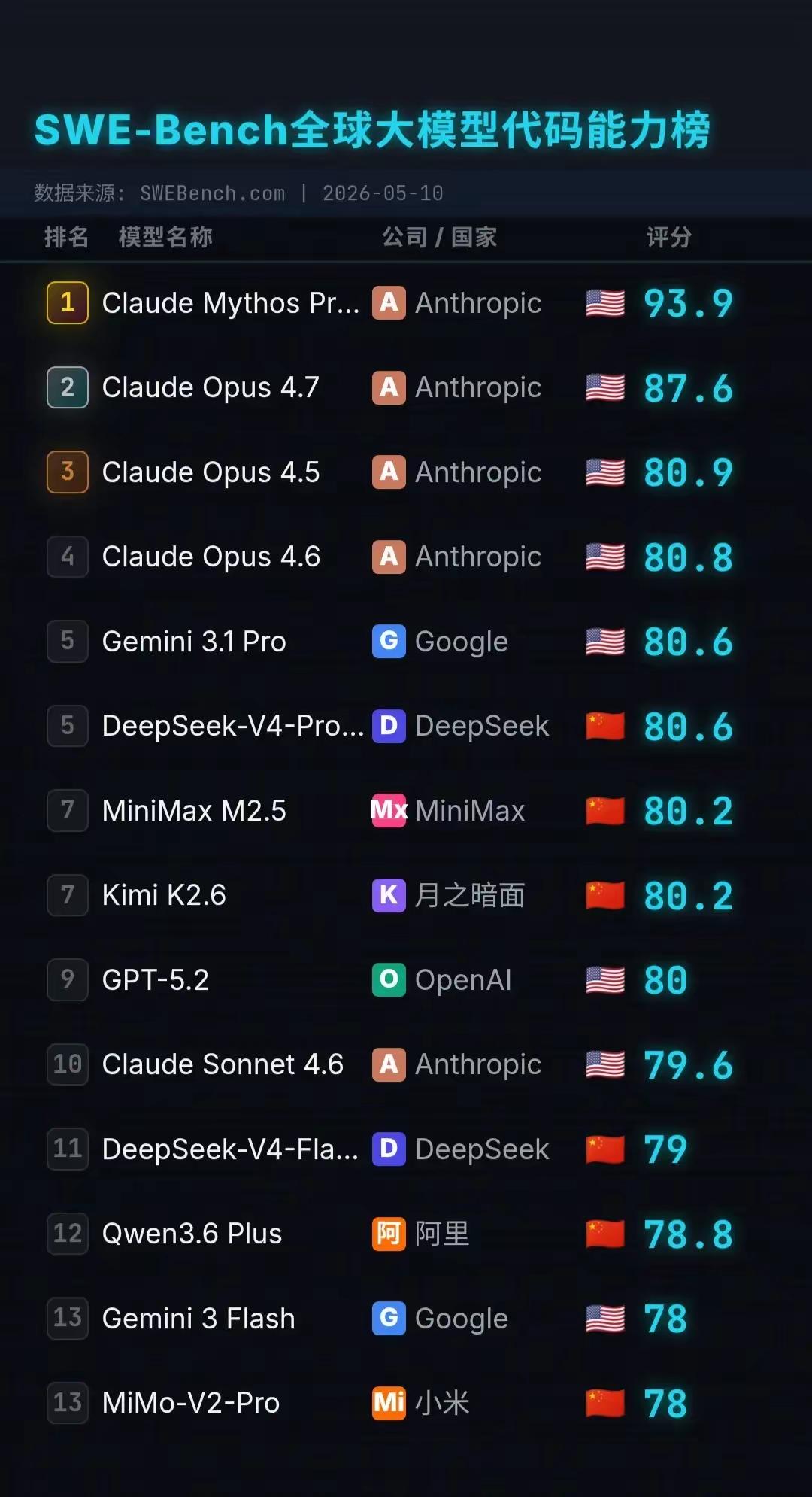
这份榜单是衡量AI编程能力的权威参考,核心结论可以概括为:Anthropic断层领跑,国产大模型已跻身全球第一梯队。
核心格局概览
- 绝对霸主:Anthropic的Claude系列包揽前四名,新版本 Claude Mythos Preview 以93.9分的成绩大幅刷新纪录,展现出解决复杂代码问题的顶尖能力。
- 国际巨头:Google的 Gemini 3.1 Pro (80.6分)、OpenAI的 GPT-5.2 (80分)紧随其后,表现稳定。
- 国产高光:DeepSeek、MiniMax、Kimi、阿里通义千问、小米MiMo等模型全部进入前15名,头部国产模型的分数已与国际顶尖模型持平,如DeepSeek-V4-Pro与Gemini 3.1 Pro同分。
关键排名与分数
- 第1名:Claude Mythos Preview (Anthropic),93.9分,断层第一,代码能力标杆
- 第2名:Claude Opus 4.7 (Anthropic),87.6分,稳定输出,企业级首选
- 第5名:Gemini 3.1 Pro (Google),80.6分,谷歌生态下的强力选手
- 第5名:DeepSeek-V4-Pro (中国),80.6分,国产之光,与Gemini同分
- 第7名:MiniMax M2.5 (中国),80.2分,多模态与代码能力均衡
- 第7名:Kimi K2.6 (中国),80.2分,超长上下文+强代码理解
- 第9名:GPT-5.2 (OpenAI),80.0分,老牌王者,实力依旧
深度洞察
1. Claude的统治力:Anthropic的模型在代码领域展现出压倒性优势,尤其是新版本,几乎可以处理SWE-Bench中的绝大多数真实世界编程问题,这也是它被视为最适合做复杂开发和Agent任务的原因。
2. 国产模型的追赶:DeepSeek、MiniMax、Kimi等国产模型的分数已经追平甚至超越了部分国际知名模型,证明在代码能力上,中国大模型的实力不容小觑。
3. 能力与应用场景:- 如果你需要解决极其复杂、难度极高的编程难题,Claude系列是目前公认的最优解。
- 对于大多数日常开发、脚本编写、代码调试场景,DeepSeek、GPT、Gemini、MiniMax等模型都能提供足够优秀的支持。
AI代码理解 AI测评体系 AI能力分级 AI大模型竞赛 ai公司排名 AI模型排行榜 ai代码索引