【搭建长效AI记忆体系的四层逻辑】
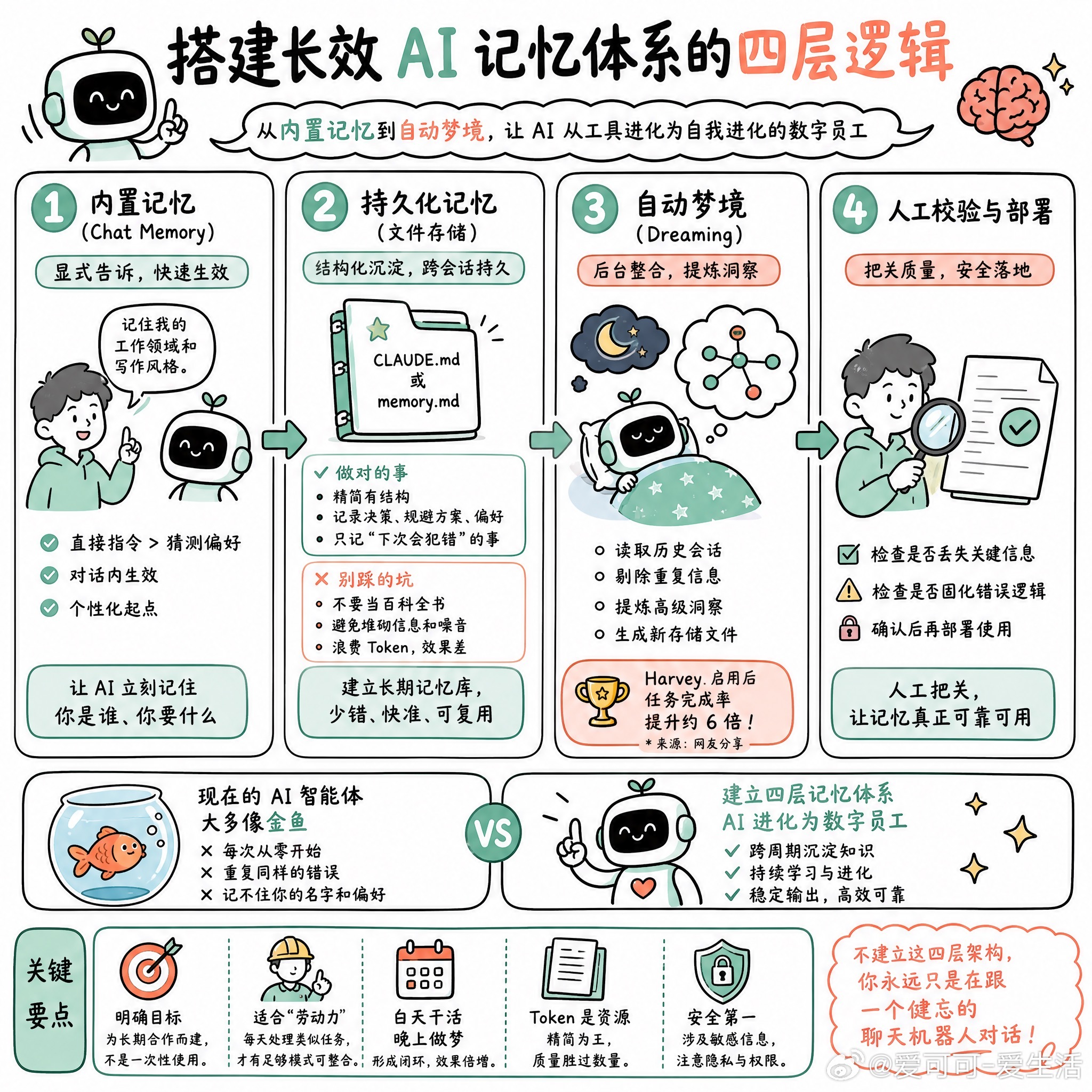
快速阅读:目前的 AI 智能体大多像金鱼,每次对话都是从零开始。通过构建从“内置记忆”到“自动梦境(Dreaming)”的四层架构,可以让 Claude 实现跨周期的知识沉淀,从一个只会听指令的工具,进化为能自我进化的数字员工。
现在的智能体大多像金鱼,每次开启新对话都在重复同样的错误,甚至连你的名字和偏好都记不住。这并非模型缺陷,而是语言模型的基础特性:除非你显式地把上下文喂回去,否则它们永远处于“出厂设置”状态。
想要打破这种性能停滞,得给它装上记忆层。
最简单的做法是利用 Claude 2026 年推出的内置 Chat Memory。别等它自己去学习,直接在对话里明确告诉它:“记住我的工作领域和写作风格”。这种显式指令比让它通过历史记录去猜要快得多。
如果你是开发者,得学会用文件来做“持久化存储”。比如在项目里维护一个 `CLAUDE.md` 或 `memory.md`。但有个坑得避开:千万别把它当成百科全书去堆砌信息,那样会浪费大量 Token 且充满噪音。好的记忆应该是精简且有结构的,只记录那些“如果我不记下来,下次还会犯错”的决策、规避方案和偏好。
更高级的玩法是 Anthropic 推出的 Dreaming 技术。这有点像人类睡觉时的记忆整合:它会在后台读取过去的会话记录,剔除重复信息,把零散的经验提炼成更高级的洞察。
有网友提到,法律 AI 公司 Harvey 在启用 Dreaming 后,任务完成率提升了大约 6 倍。这说明对于重复性极高的工作,这种“白天干活,晚上做梦”的闭环非常有效。
不过,Dreaming 并不是万灵药。如果你的智能体只是偶尔用一次的“游客”,它根本没有足够的模式可以整合。它更适合那些每天都在处理类似任务的“劳动力”。
最后有个细节:Dreaming 生成的是全新的存储文件,千万别直接自动化部署。一定要人工检查一下,看看它有没有把有用的信息弄丢,或者把错误的逻辑固化下来。
如果不建立这四层架构,你永远只是在跟一个健忘的聊天机器人对话。
x.com/0xCodez/status/2058156429559636069