我真的震惊,全球最大的AI开源社区Hugging Face,居然主动掏了自己的钱,给一个中国模型提供了6小时的全球免费算力?
如果你了解一点AI行业的背景,会发现这里面藏着一个很大的信号。
1先简单说一下发生了什么。
6月17日,智谱发布了他们最新的旗舰模型GLM-5.2,以MIT协议完全开源,允许免费商用。
Hugging Face看到之后,第一时间宣布为这个模型提供专属的免费算力通道。
要知道,这还是Hugging Face头一次给国产模型开这种绿灯。
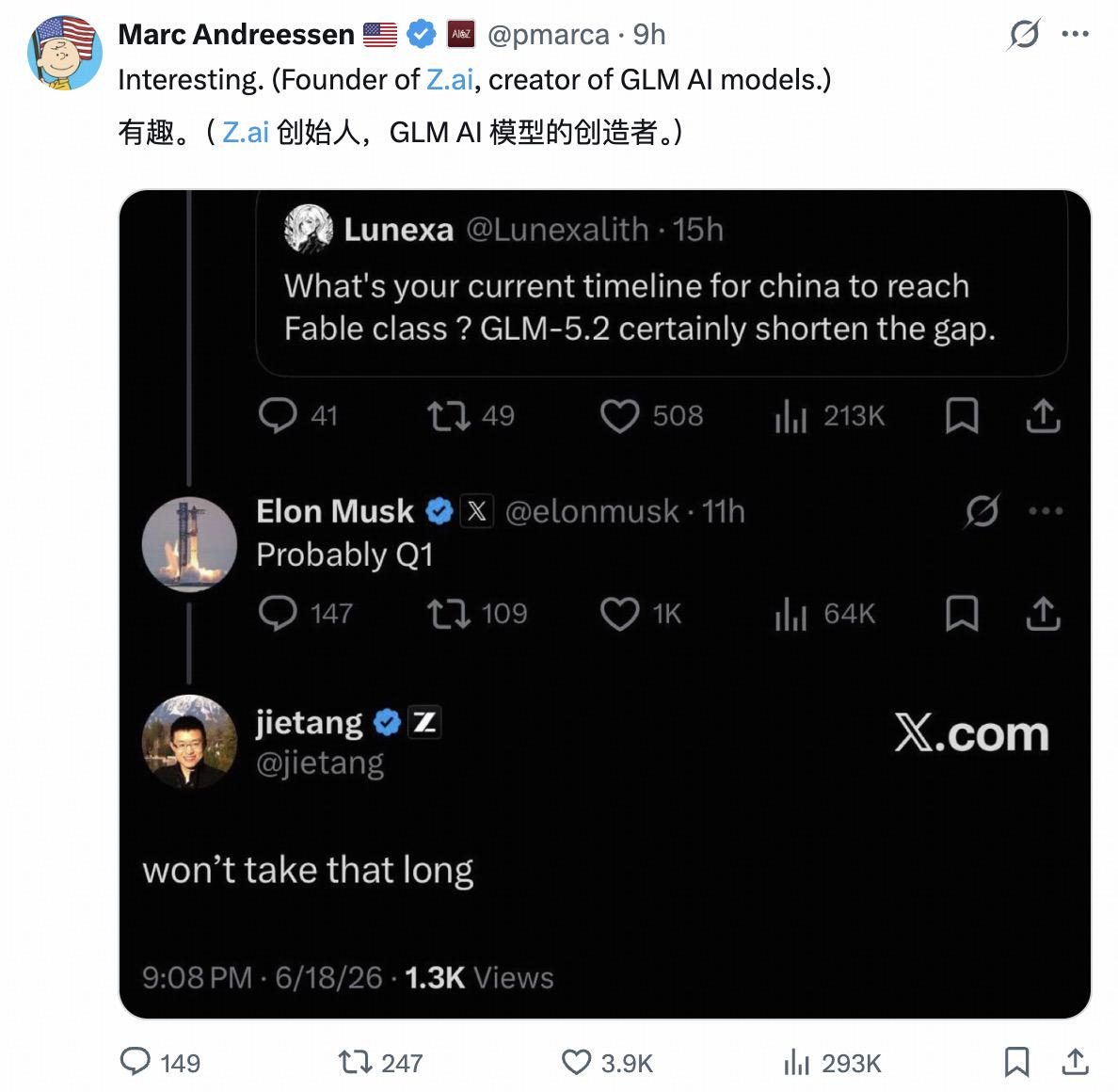
然后马斯克在社交平台上被人问到,中国模型什么时候能达到Fable那个水平。他回了一句,大概2027年一季度吧。
智谱创始人唐杰直接隔空回了一句:用不了那么久。
海外开发者社区里,不少人觉得马斯克这次判断太保守了。
看到这里你可能会问:GLM-5.2到底强在哪,为什么这么多人关注?
2之前编程模型这条赛道,长期就是海外几家大厂互相卷,Claude、GPT、Gemini,大家一般管这三位叫御三家。
国产模型虽然在追,但在最核心的coding能力上,尤其是大型工程级别的长任务,跟御三家始终有一道肉眼可见的距离。
但直到智谱发布了GLM-5.2,我第一时间拿手头的真实项目去跑了两轮测试。
跑完之后只有一个感受:御三家的席位,真的该重新排了。
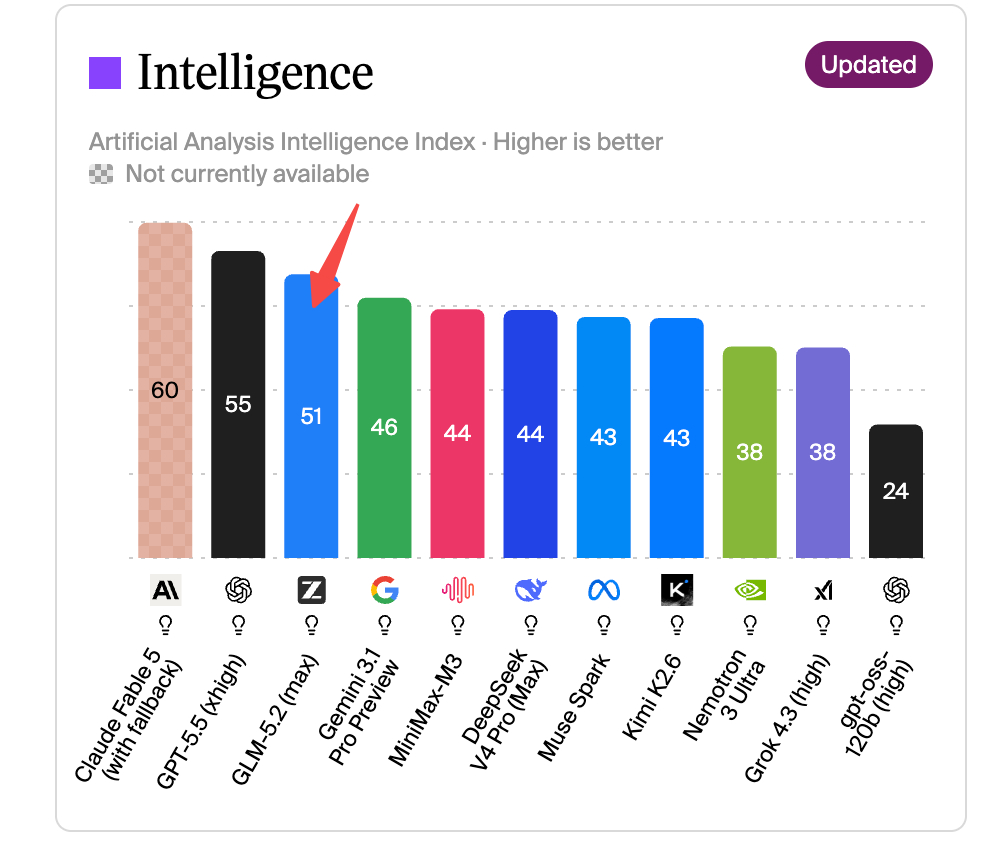
在Artificial Analysis综合榜单上,GLM-5.2拿了51分,跟Anthropic和OpenAI的旗舰模型并列全球前三,并位列开源模型 SOTA。
在Code Arena这个全球百万用户参与盲测的前端开发评估平台上,GLM-5.2排到了全球可用模型第一。
再看长任务能力。
FrontierSWE是专门考验AI在超长工程任务上能撑多久的评测,有些任务要求模型连续工作20小时。
GLM-5.2目前仅次于Claude Opus 4.8,差距大概在1%到4%之间。
但光看榜单没意思,咱们直接上手测。
3我以Ghostfolio这个代码库作为测试案例,拿它来试试GLM-5.2的1M上下文到底是不是真的能用。
我把整个代码库一次性投喂进去,然后给它下了下面几个任务👇
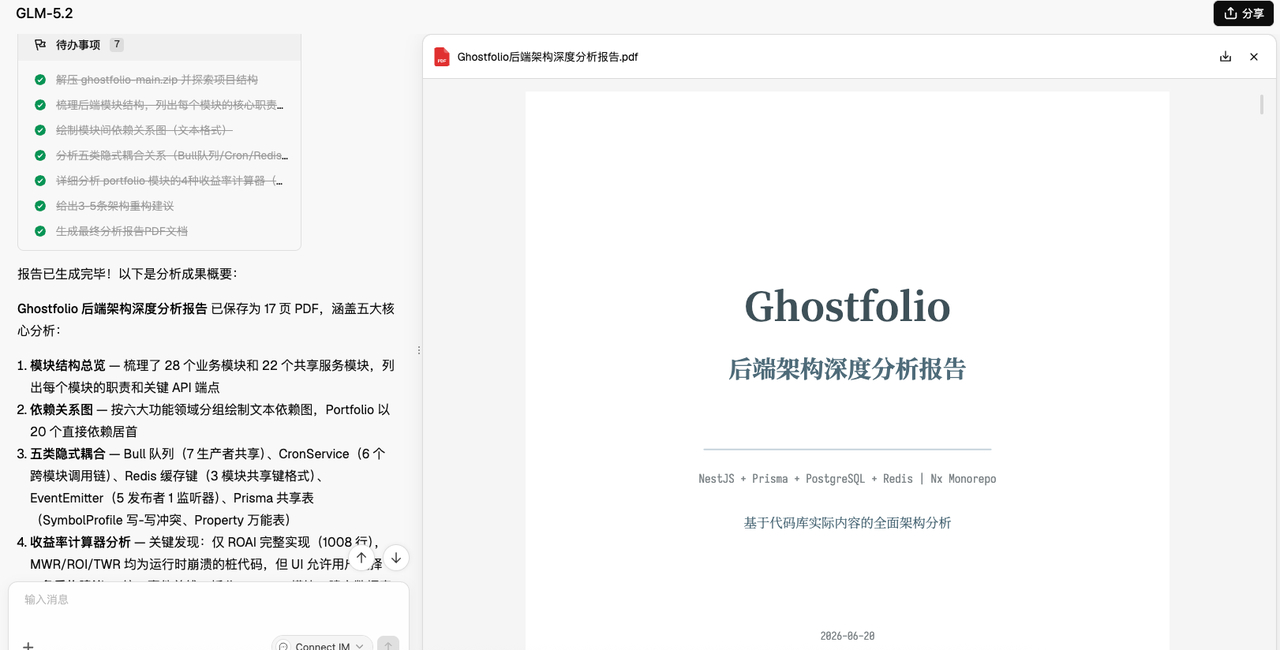
GLM-5.2这次的表现让我挺意外的,它给我输出了一份非常详细的17页的后端架构分析报告。
在模块结构总览部分,它梳理了 28 个业务模块和 22 个共享服务模块,列出每个模块的职责和关键 API 端点。
它生成的依赖关系图,按六大功能领域分组绘制文本依赖图,Portfolio 以 20 个直接依赖居首。五类隐式耦合 — Bull 队列(7 生产者共享)、CronService(6 个跨模块调用链)、Redis 缓存键(3 模块共享键格式)、EventEmitter(5 发布者 1 监听器)、Prisma 共享表(SymbolProfile 写-写冲突、Property 万能表)。
它最后还给了我五条详细的重构建议,统一事件总线、拆分 Portfolio 模块、建立数据表访问门控层、完善/移除未实现计算器、解耦 CronService。
如果只是改一个函数或者写个小脚本,1M跟200K真没什么体感差异。但整库级别的理解和分析,这不是快慢的问题,是能做和做不了的问题。
4第二个测试我想验证的是GLM-5.2的长任务自主执行能力。
我给它的需求就一句话:帮我做一个团队周报收集系统,支持成员提交周报、管理员查看汇总、按周归档,要有Web端和移动端适配。
没有产品文档,没有原型图,然后我就看着它自己干活。
它先拆解了需求,确定了技术栈,接着开始搭项目结构,然后就是一个模块一个模块地写:用户认证、周报提交表单、管理员面板、数据汇总、按周归档查询。
整个过程中间它经历了几百次工具调用和文件读写。
从需求输入到最终交付一个能跑的完整应用,总共花了大概两个半小时。
以前这种从零开始构建一个多端应用的活儿,一个小团队怎么也得干上一两周。
但现在模型能自主完成到这个程度,说实话超出了我的预期。
5可能有人会说,1M上下文不是很多模型都标了吗?
但标称1M和真正能用的1M,完全是两码事。
很多模型号称支持1M token的窗口,但你真塞个七八十万token进去,它到后半段就开始失忆。
原因很简单,上下文越长,注意力计算和KV缓存的开销越大。不少模型跑1M的时候又慢又贵,实际上根本没人这么用。
GLM-5.2这次从架构层面下了功夫,用了一套叫KV8加HiSparse的技术组合,把长序列下的计算量和内存占用同时压下来了。在MRCR这类专门测长文检索和推理的基准上,GLM-5.2到100万token长度的时候效果衰减依然很小。
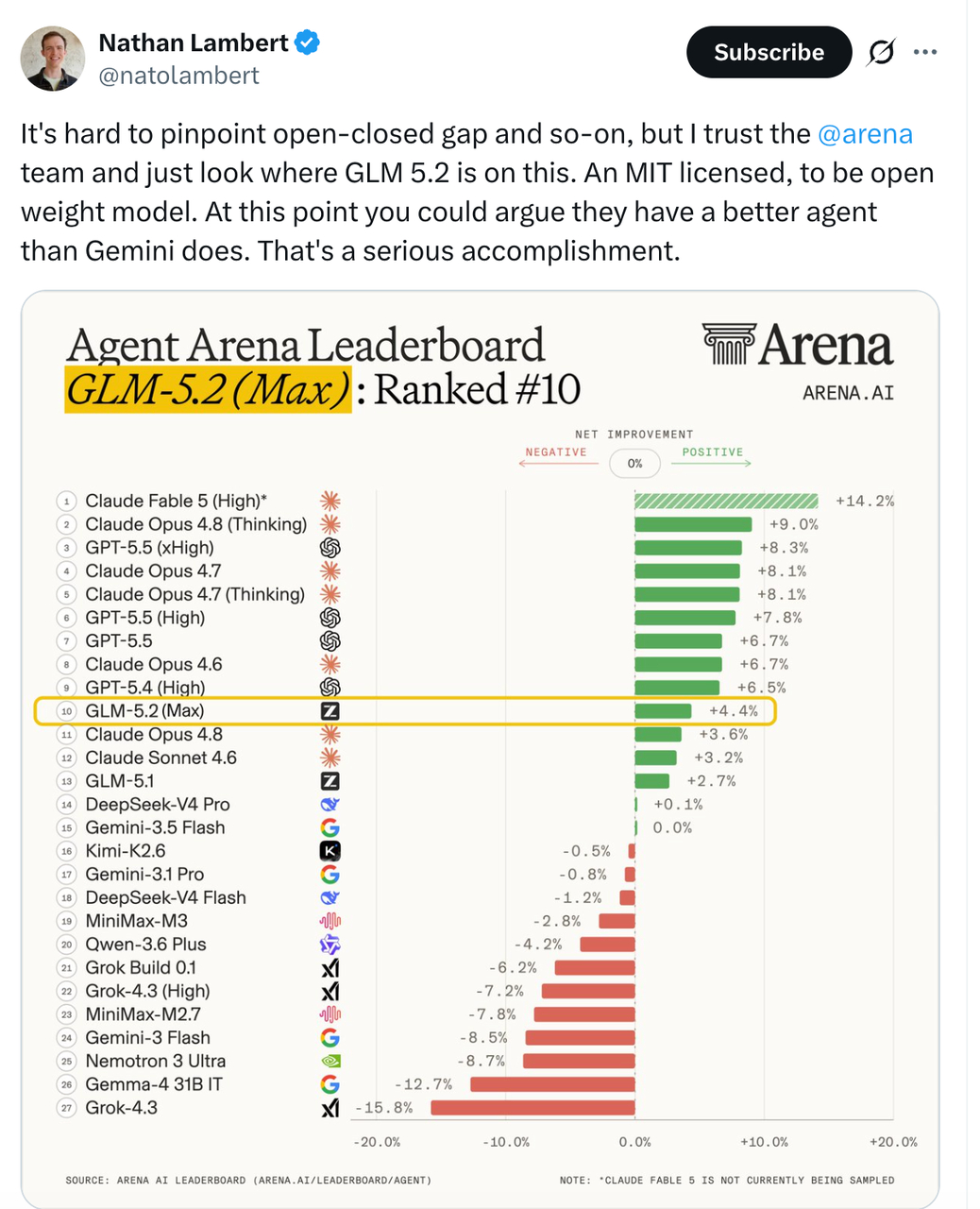
我去看了一下,海外开发者社区的反馈也挺有意思,Hermes Agent和OpenRouter发布当天就宣布支持。X上不少海外开发者实测后给出的评价是体感介于Opus 4.7和4.8之间。
从国产开源模型的角度看,已经是历史性的位置了。