很多人问我MiniMax价格的事儿,我说两句 | MiniMax 今天发了 M3,你刷到了吧。我直接说重点:
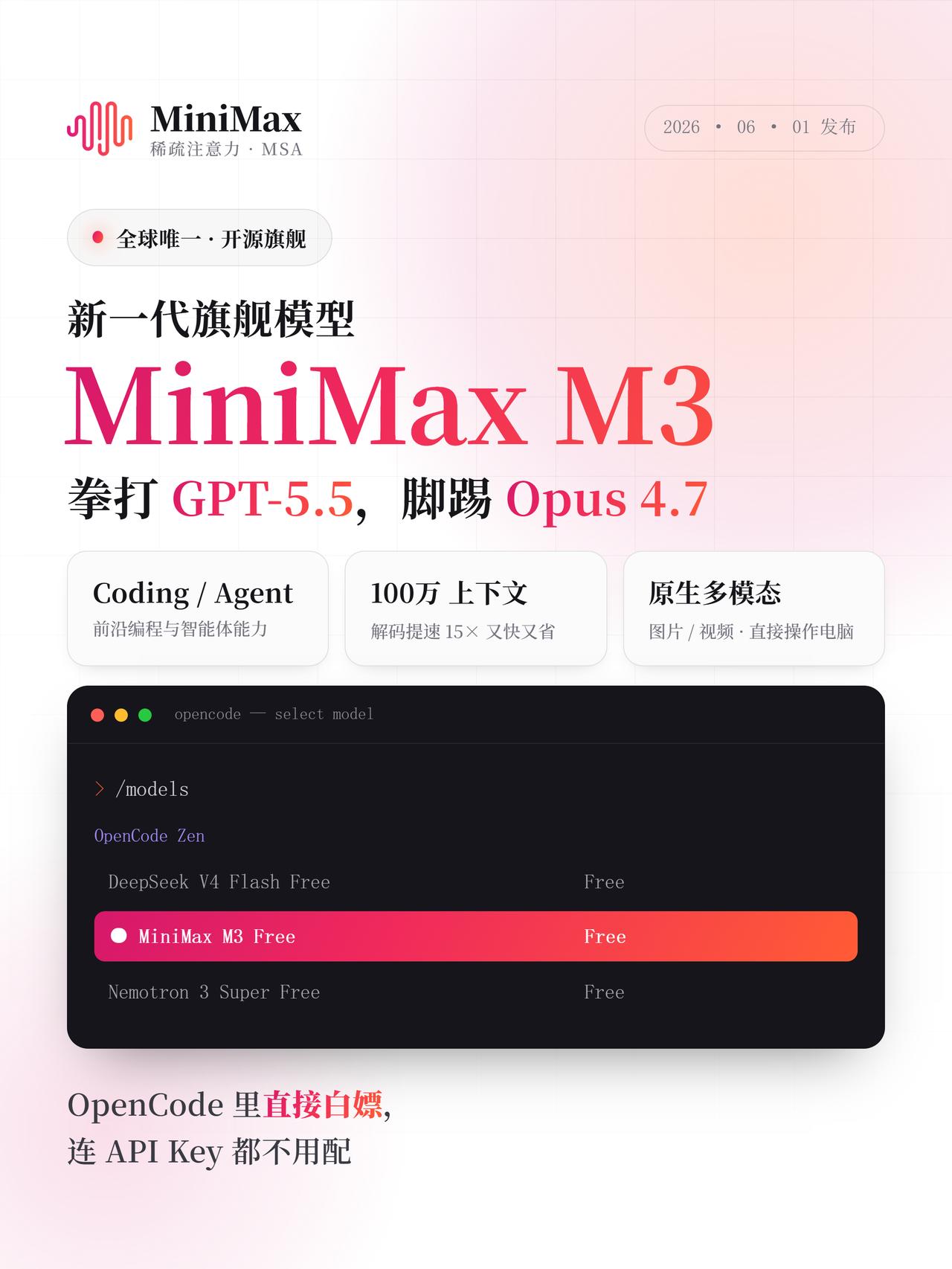
这是国产模型里,第一个同时集齐三样的开源模型:编程能力达到最顶尖那一档、100 万上下文窗口、以及原生多模态。
在这之前,能把这三样同时做到的只有 Opus 4.8、Gemini 3.1 和 GPT 5.5,它们全都是闭源的,实测下来的感受是,它超过了 Sonnet 4.6。
Sonnet 4.6 是现在全球开发者用得比较多的模型之一,写代码、跑 Agent、处理文档,大部分人吃的就是这碗饭,M3已经到了能上生产环境的水平。
100 万上下文窗口意味着什么?
一次性吃下一整个项目的代码库,连带文档、测试用例、历史记录一起读进去,边读边改。
我研究了下背后的技术:
MiniMax自研了一个叫MSA的稀疏注意力架构,100 万 token 上下文的计算量只有上一代模型的二十分之一,推理时,模型理解问题的阶段快了 9 倍,生成答案的阶段快了 15 倍。
说白了,100 万上下文以前谁都能做,就是算不起这笔账,MSA 把成本打下来了。
看了几个例子:
一个是让 M3 去优化 CUDA 算子,24 小时跑了 147 次提交,把性能从 cuBLAS 基准的 7.6% 拉到了 71.3%,全程自主迭代。
另一个是拿一篇 ICLR 获奖论文扔给它,12 小时独立复现,跑通训练流程出结果;这些场景是真正的工程活,能干这种活的模型,全球数得过来。
MiniMax还同步发了 MiniMax Code,一个编程 Agent 工具,对标 Claude Code 和 Codex。这个工具跟 M3 一起训练出来的,模型加工具一起上,卖一套完整的开发者工作流。
另外,M3 是即将开源的。对很多中大型公司来说,这是排在能力前面的硬门槛;能力到了,价格低了,还开源,三样凑齐,企业才真的会从闭源切过来。
再来说价格。我算了笔账。
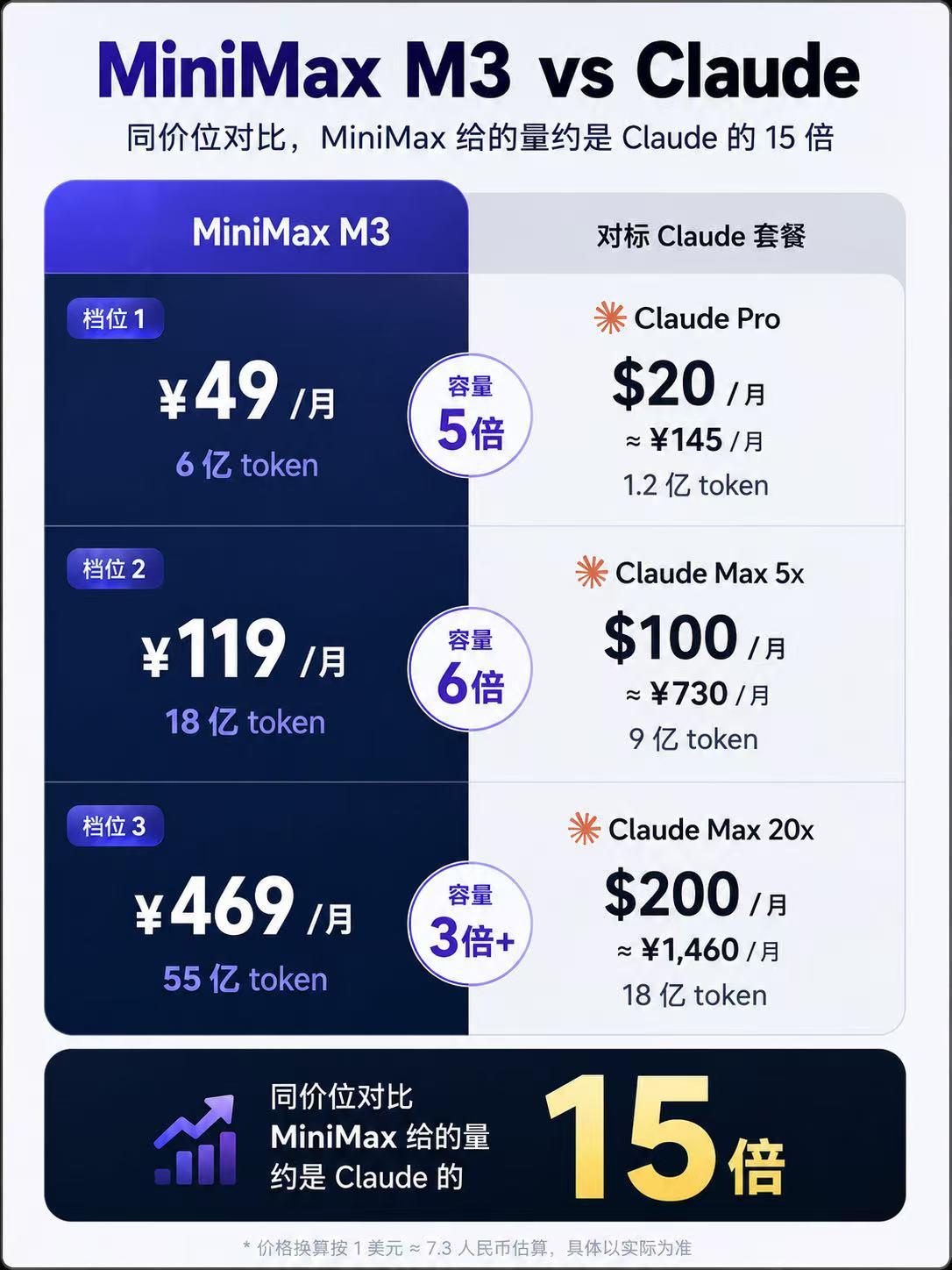
MiniMax 这次同步更新了 Token Plan,分三档。
每个月 49 块,给 6 亿 token;对比一下,Claude Pro一个月 145 块,量只有 MiniMax五分之一。
每个月119块,给18亿 token;Claude Max 5x 一个月 730 块,量只有 MiniMax 的一半,价格贵了 6 倍。
每个月469块,给 55 亿 token;对标 Claude Max 20x套餐,量还多出 3 倍。同价位拉平算,MiniMax 给的量大概是 Claude 的 15 倍。
别人把前沿能力当高端品卖,MiniMax选择把门槛降到最低,让更多开发者用上。
我认为,模型层战争不会停,各家还会继续卷能力。MiniMax M3 押的是另一个逻辑:用顶级能力配上普惠定价,先把开发者生态用起来。