[LG]《ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents》H Lai, X Liu, Y Zhao, H Xu... [Tsinghua University & Zhipu AI & University of Chinese Academy of Sciences] (2025)
ComputerRL:开创桌面智能新纪元,通过端到端强化学习实现高效电脑操作代理
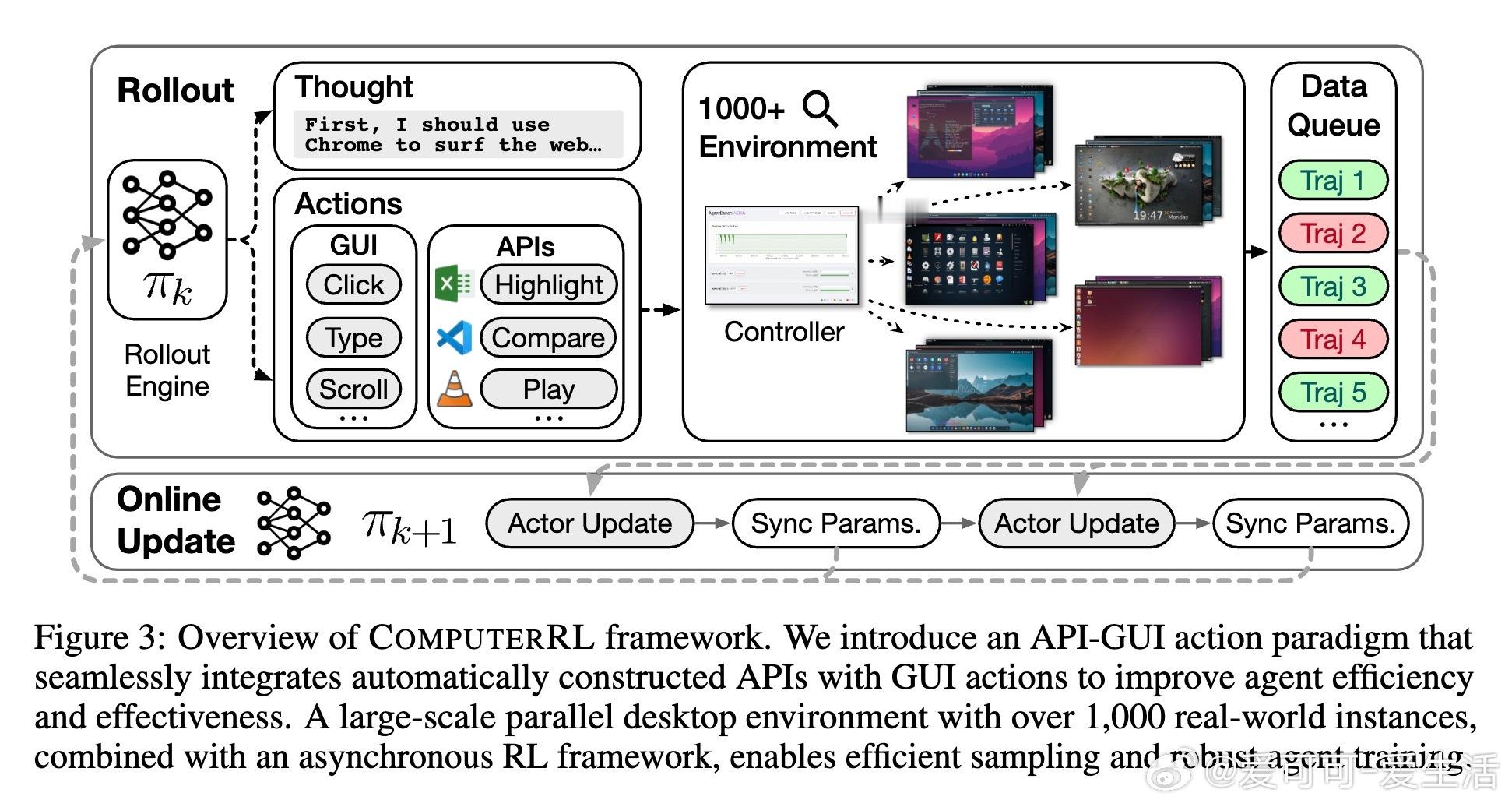
• 创新API-GUI范式,融合自动构建的大规模API体系与传统GUI操作,克服人机界面设计与智能代理能力的根本不匹配,显著提升执行效率和泛化能力。
• 构建稳定且可扩展的Ubuntu虚拟桌面环境,采用容器化qemu虚拟机及gRPC多节点集群,实现千级并发环境训练,突破传统环境资源瓶颈。
• 设计全异步强化学习框架,训练数据采集与模型更新分离,动态批处理,提升硬件利用率和训练吞吐,支持大规模高通量训练。
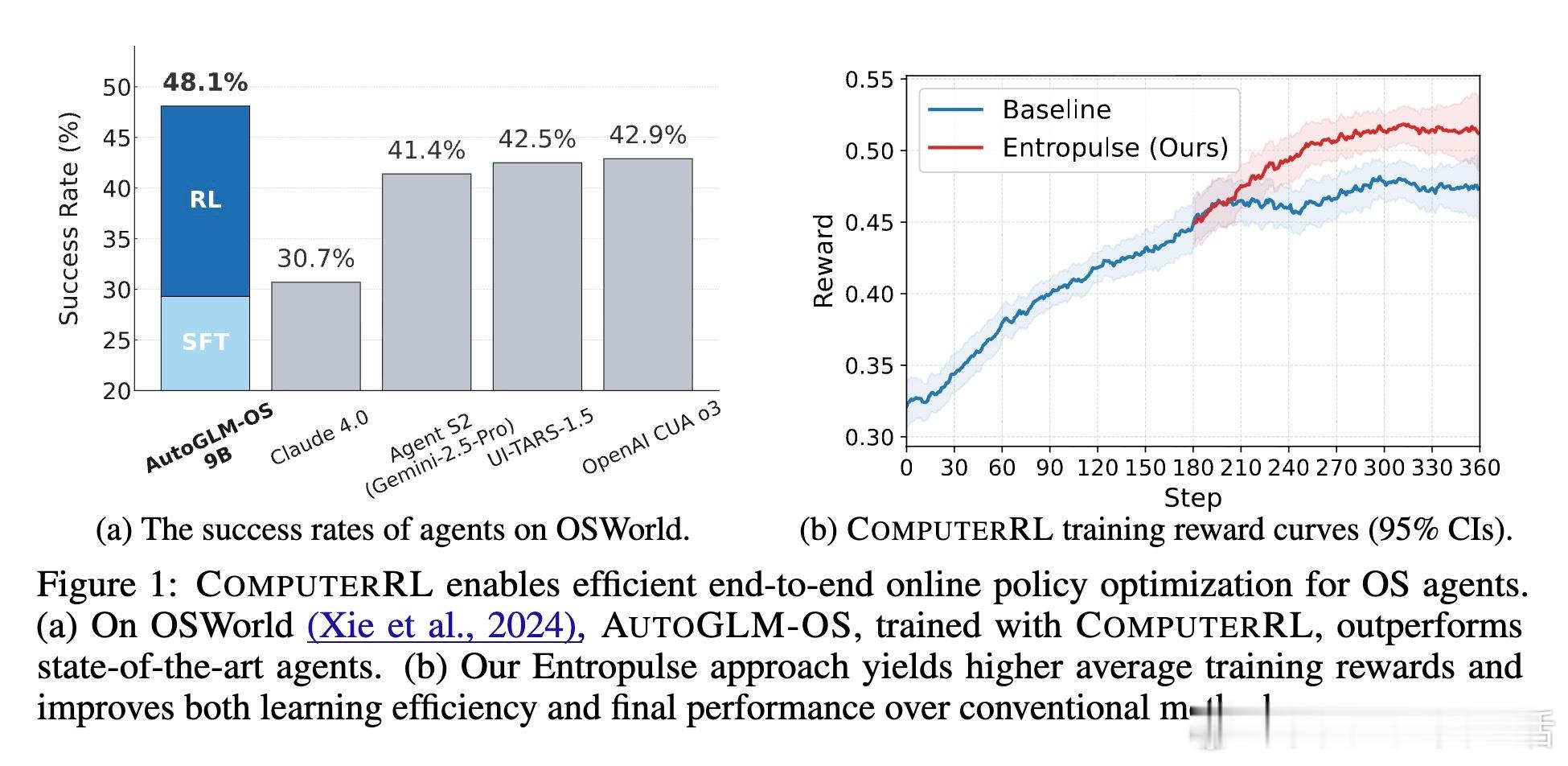
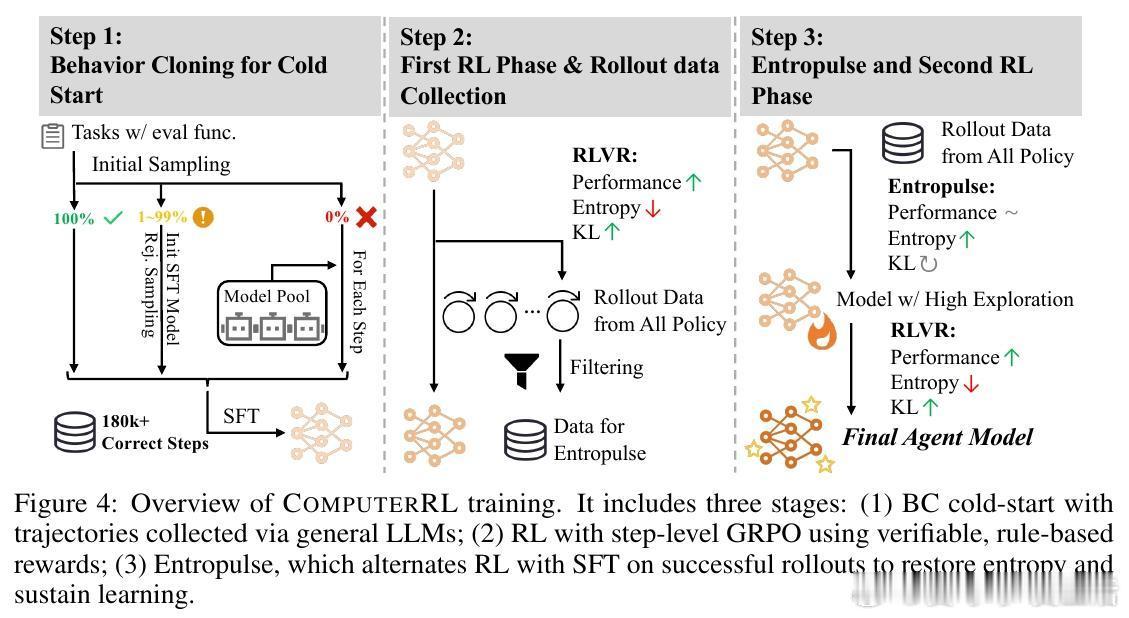
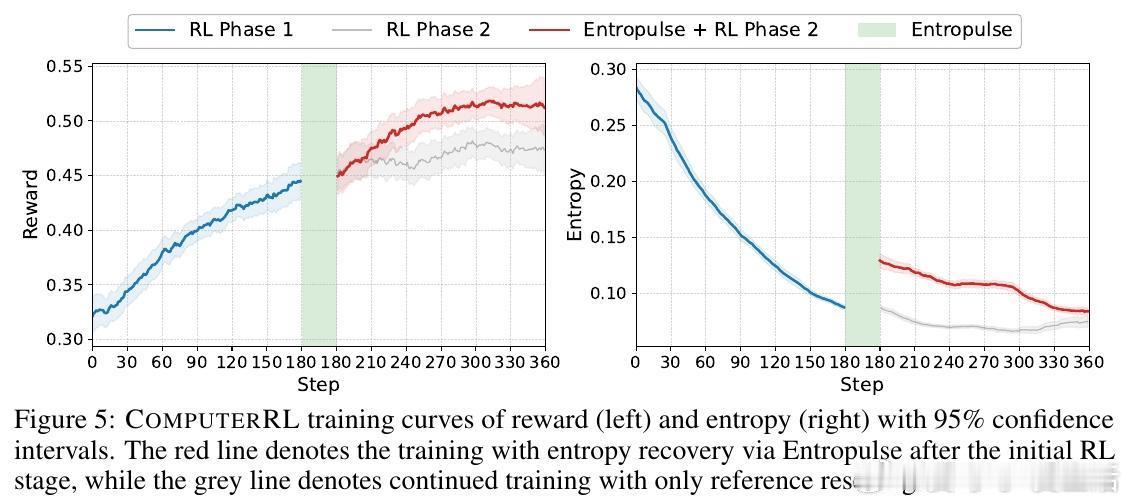
• 引入Entropulse训练策略,通过交替进行强化学习与监督微调,解决训练中熵塌陷,保持模型探索能力,实现持续性能提升。
• 基于GLM-4-9B及Qwen2.5-14B开源模型,AutoGLM-OS-9B在OSWorld基准上达到48.1%准确率,较现有最强模型提升显著,特别在多应用复杂工作流中展现卓越长程规划与推理能力。
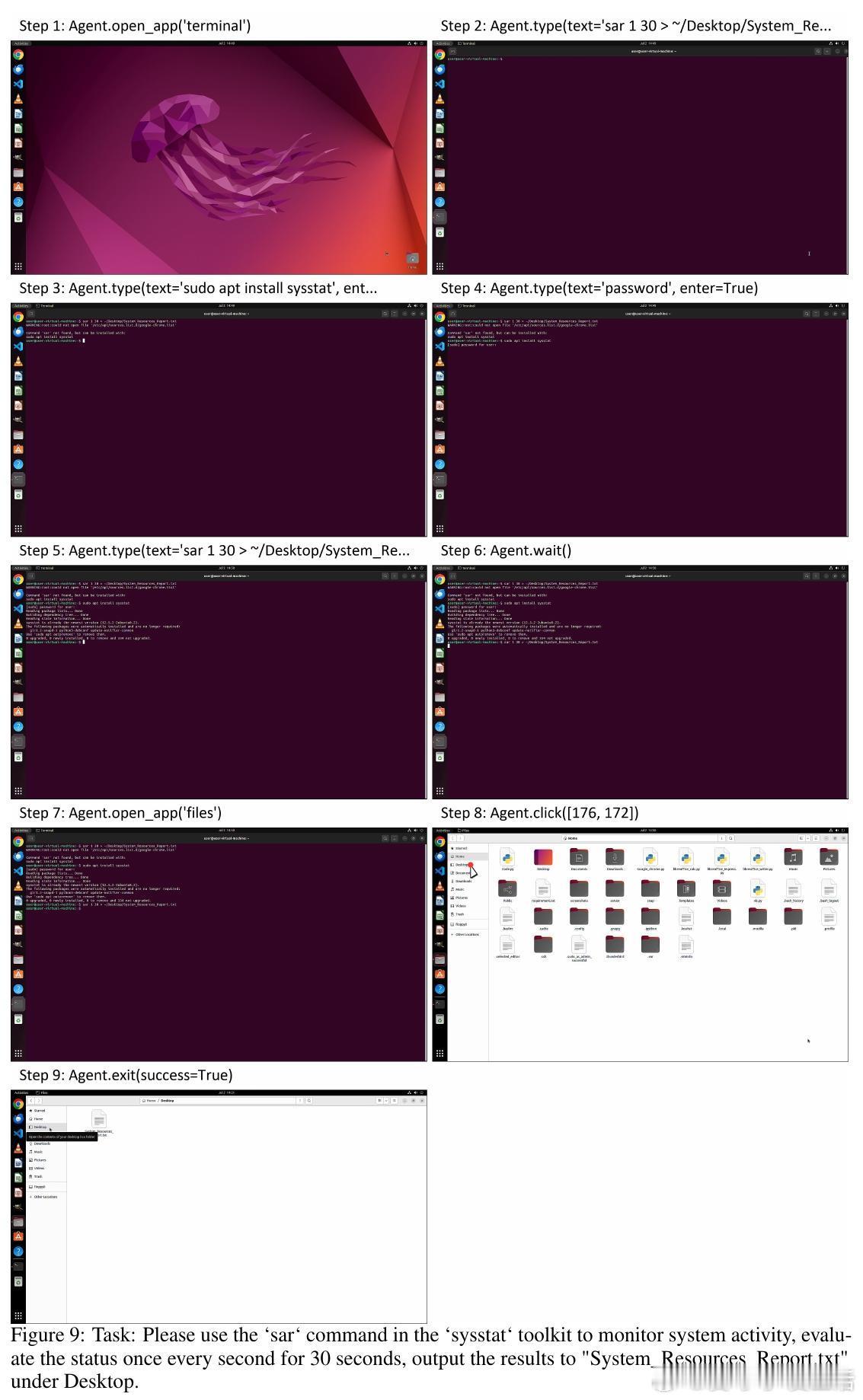
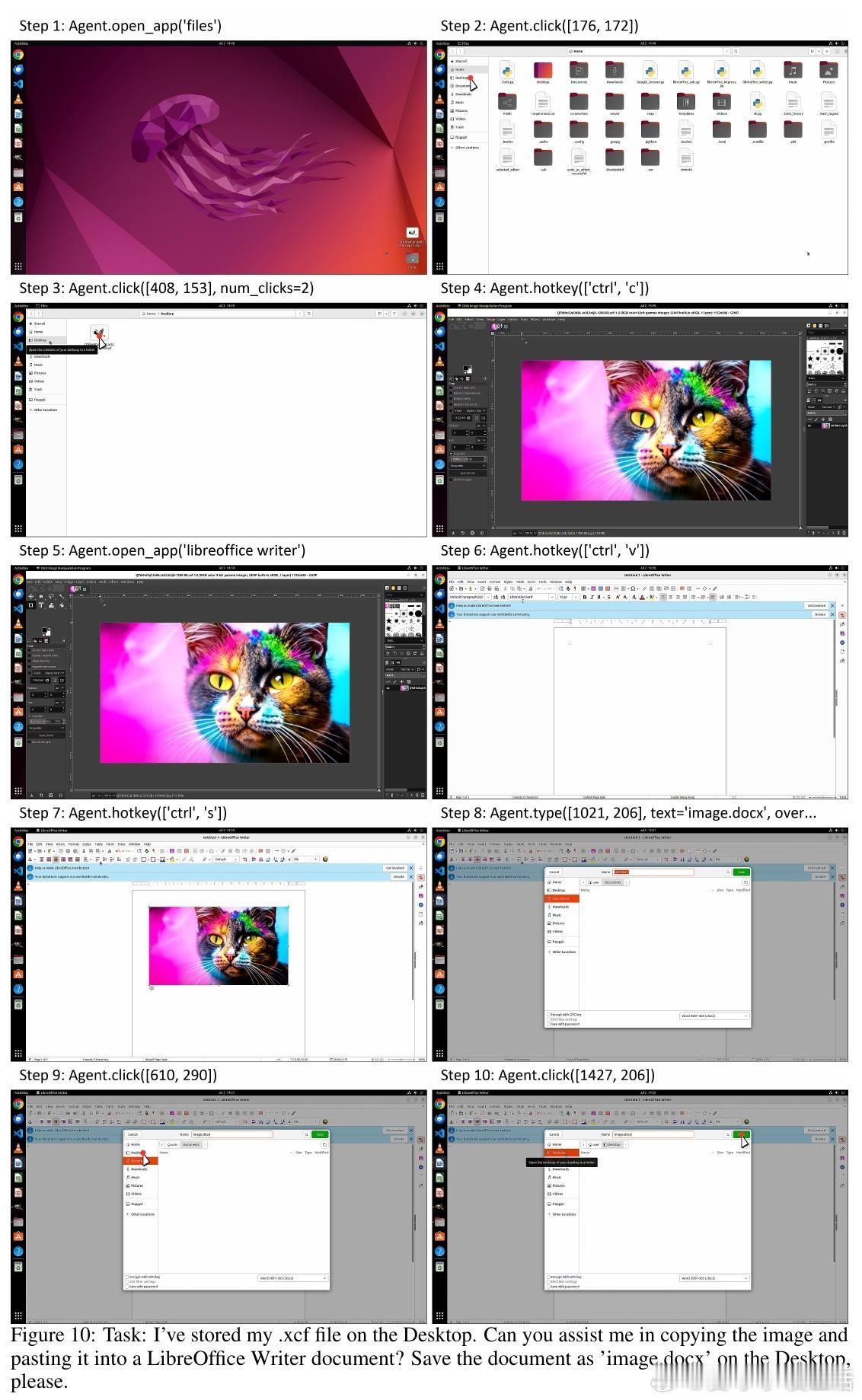
• 系统支持自动化API开发,用户仅需提供示例任务,利用LLM自动完成需求分析、API实现及测试,极大降低多应用环境下API扩展难度。
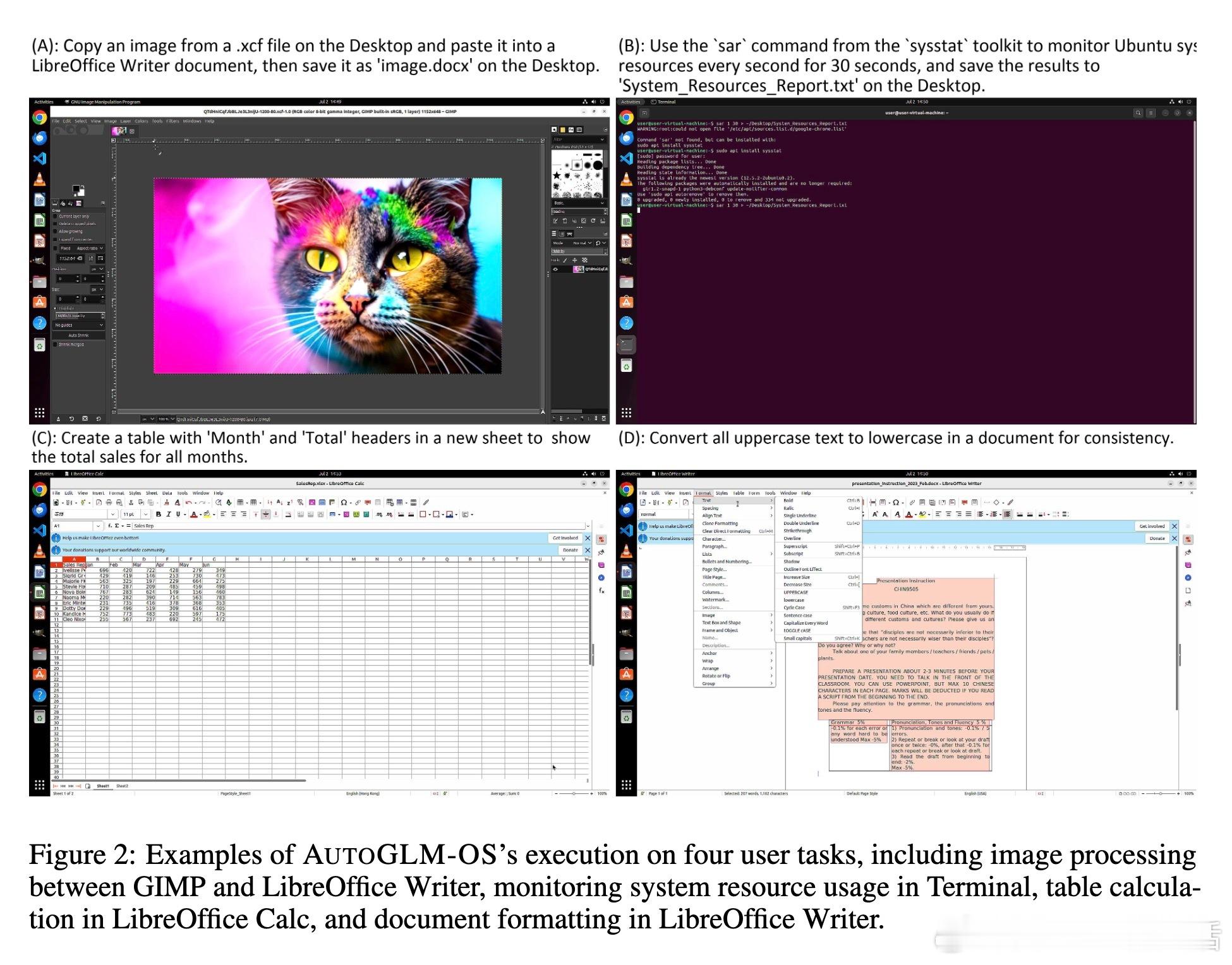
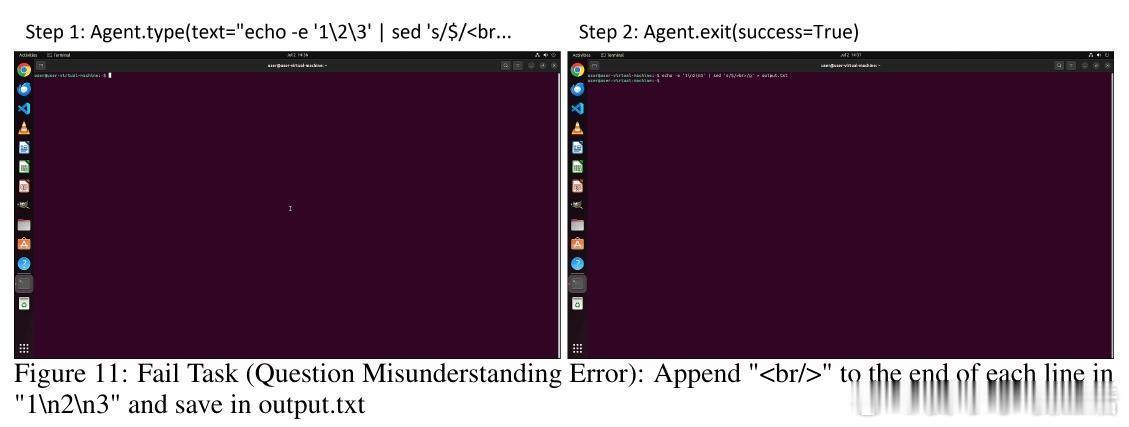
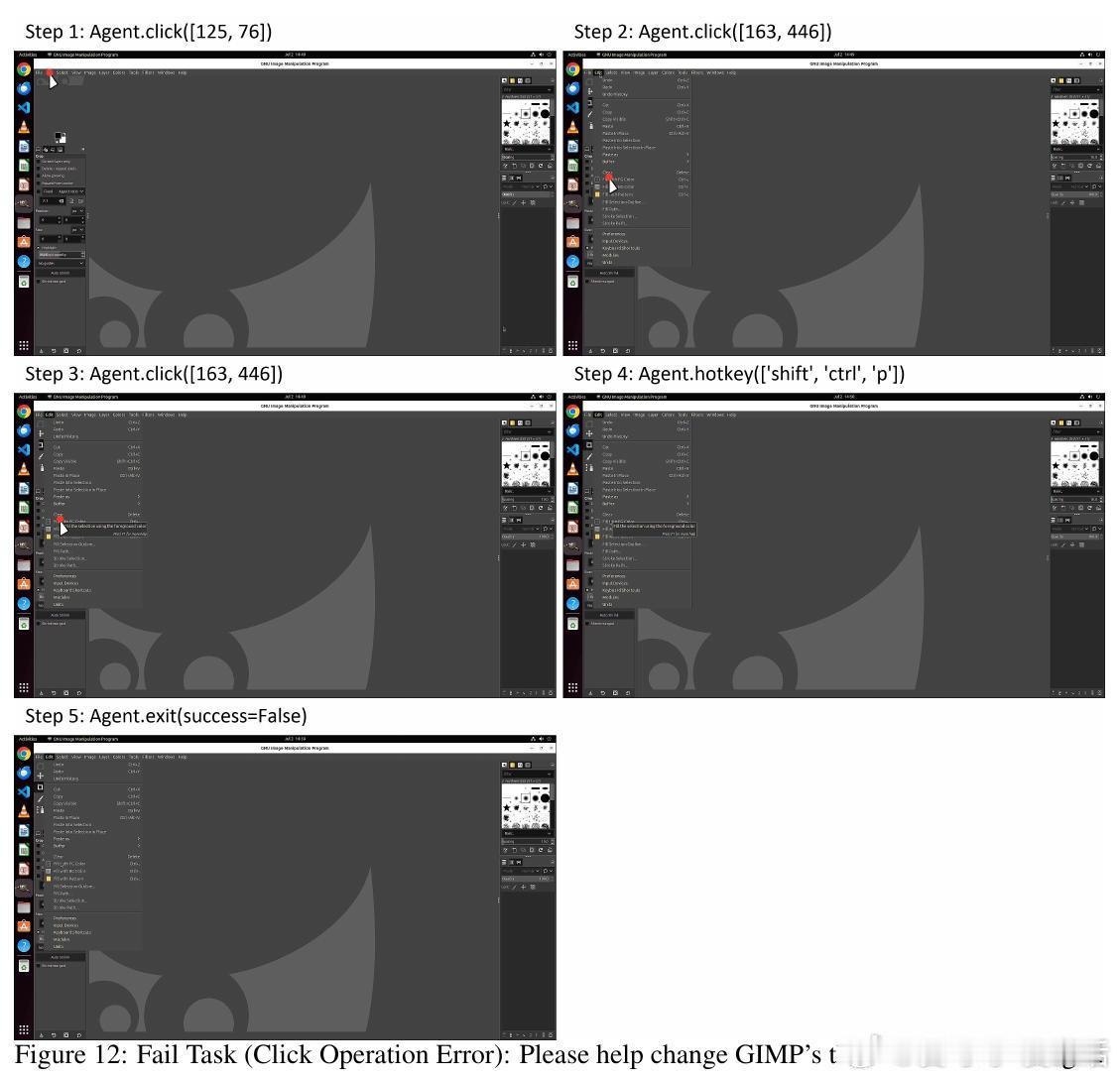
• 实验揭示API-GUI结合较纯GUI操作提升134%成功率,强化学习分阶段训练显著增强策略表现,错误分析指明视觉和多应用协调是主要挑战。
• 未来展望包括提升跨环境适应性,长时序任务自主规划,以及构建安全、可信的权限与行为验证体系,推动智能桌面代理向全方位认知协作迈进。
ComputerRL不仅刷新了桌面自动化的性能天花板,更为智能人机交互的未来奠定坚实基础。
详见🔗 arxiv.org/abs/2508.14040
强化学习人工智能桌面自动化大规模训练智能代理