[LG]《RLP: Reinforcement as a Pretraining Objective》A Hatamizadeh, S N Akter, S Prabhumoye, J Kautz... [NVIDIA & CMU] (2025)
RLP:将强化学习引入预训练,模型“先思考”再预测,显著提升推理能力
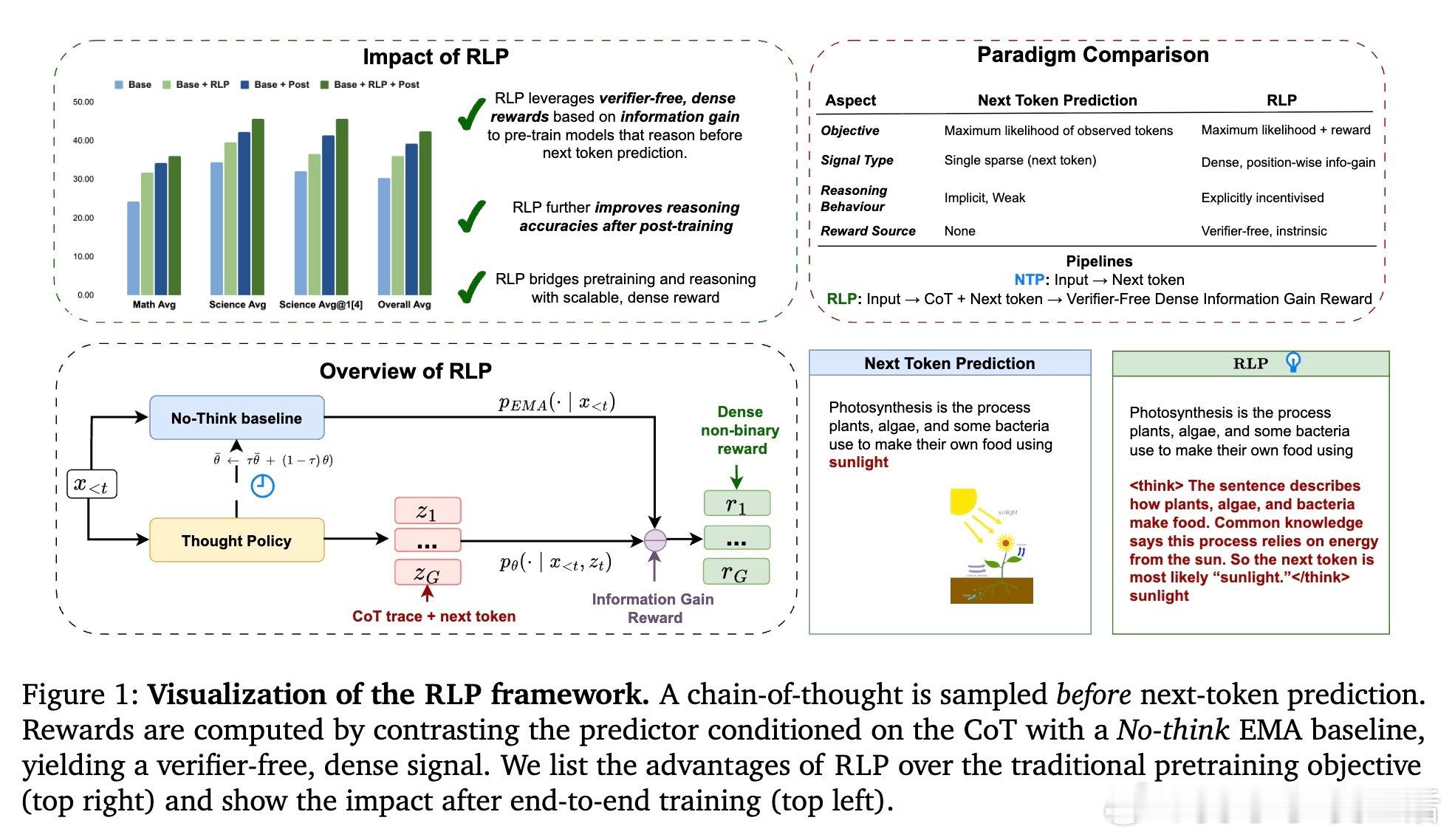
• 传统大语言模型预训练仅用下一词预测,忽略了推理思维的培养。RLP创新性地将“思路链(chain-of-thought)”视为一种探索行为,在预测每个词前先生成推理过程,再根据推理对下一个词预测信息增益给予奖励。
• 采用基于信息增益的密集、无需人工验证的奖励信号,利用模型自身的对比(带思考vs不带思考的预测概率差)实现训练,适用于通用文本数据,无需专门的验证器或标注数据。
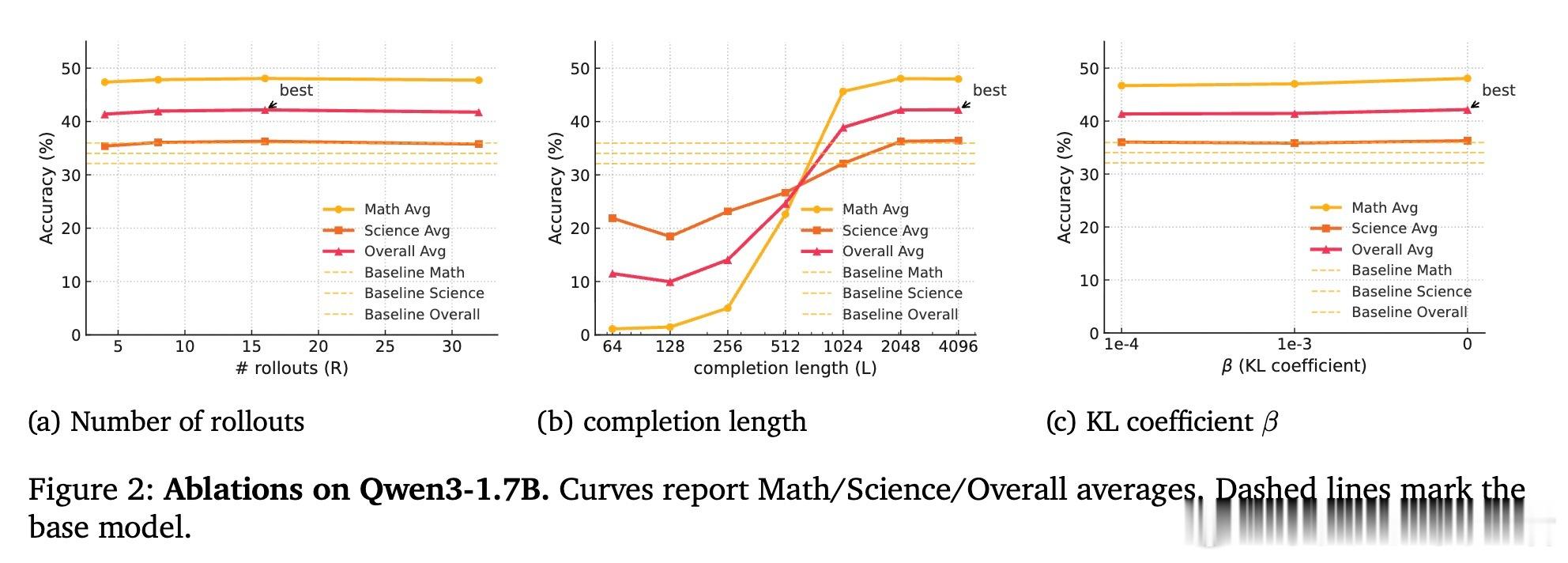
• 设计了稳定高效的训练算法,包括EMA(指数滑动平均)教师模型作为动态无思考基线、多思路采样的组内相对优势估计和裁剪重要性比率,保证算法稳定收敛。
• 大规模实验验证:在qwen3-1.7b-base模型上,RLP预训练相比传统方法提升整体数学与科学推理能力19%;在Nemotron-Nano-12B-v2大模型上,RLP用更少数据实现35%性能跃升,尤其科学推理提速23%。
• RLP的优势在多领域、多数据源均能保持,且与后续微调及强化学习反馈训练协同增益,确保推理能力稳固且可持续提升。
• 消除以往强化学习仅作为后期微调手段的局限,RLP证明强化学习可以且应当成为预训练核心目标之一,促进模型在预训练阶段就学会“思考”,打下更坚实的推理基础。
心得:
1. 让模型在预训练阶段“先思考后预测”,而非仅盲目模仿数据,是提升复杂推理能力的根本路径。
2. 利用模型自身对比构造奖励信号,无需额外人工验证,极大拓展了强化学习在大规模预训练中的实用性。
3. 多思路采样与动态EMA基线设计有效解决了强化学习中奖励稀疏和训练不稳定的问题,提升了训练效率和效果。
阅读详情🔗arxiv.org/abs/2510.01265
代码开源🔗github.com/NVlabs/RLP
大语言模型强化学习预训练推理能力人工智能