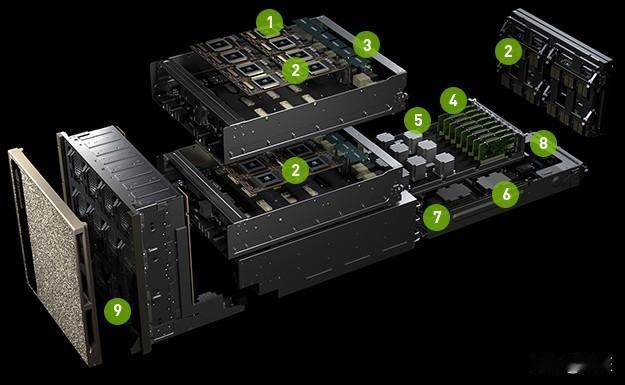
DeepSeek-R1是在2025年1月20日发布的开源推理大模型,它拥有6710亿参数、单Token激活参数为370亿,并采用了MoE架构,训练效率得到了显著提升。
R1在去年的推出震动了全球AI领域,其高效率的模型架构、训练方法、工程优化和蒸馏方法在之后成为了全行业的趋势。
没想到在不到一年之后的今天,R1模型的每token成本竟已降低了到了1/32!
今天,英伟达发表了一篇长文博客,展示了其如何在BlackwellGPU上通过软硬协同对DeepSeek-R1进一步降本增效。

随着AI模型智能程度的不断提升,人们开始依托AI处理日益复杂的任务。从普通消费者到大型企业,用户与AI交互的频率显著增加,这也意味着需要生成的Token数量呈指数级增长。为了以最低成本提供这些Token,AI平台必须实现极高的每瓦特Token吞吐量。
通过在GPU、CPU、网络、软件、供电及散热方案上的深度协同设计,英伟达持续提升每瓦特Token吞吐量,从而有效降低了每百万Token的成本。此外,英伟达不断优化其软件栈,从现有平台中挖掘更强的性能潜力。
那么,英伟达是怎样协同利用运行在Blackwell架构上的推理软件栈,以实现DeepSeek-R1在多种应用场景中的性能增益呢?我们接着往下看。
最新NVIDIATensorRT-LLM软件大幅提升推理性能
NVIDIAGB200NVL72是一个多节点液冷机架级扩展系统,适用于高度密集型的工作负载。该系统通过第五代NVIDIANVLink互连技术和NVLinkSwitch芯片连接了72个NVIDIABlackwellGPU,为机架内的所有芯片提供高达1800GB/s的双向带宽。
这种大规模的「扩展域」(Scale-upDomain)专为稀疏MoE架构优化,此类模型在生成Token时需要专家之间频繁的数据交换。
Blackwell架构还加入了对NVFP4数据格式的硬件加速。这是英伟达设计的一种4位浮点格式,相比其他FP4格式能更好地保持精度。此外,解耦服务(DisaggregatedServing)这类优化技术也充分利用了NVL72架构和NVLinkSwitch技术。简单来解释一下解耦服务,即在一组GPU上执行Prefill(预填充)操作,在另一组GPU上执行Decode(解码)操作。
这些架构创新使得NVIDIAGB200NVL72在运行DeepSeek-R1时,能够提供行业领先的性能。
得益于最新NVIDIATensorRT-LLM软件和GB200NVL72的协同,DeepSeek-R1在8K/1K输入/输出序列长度下的Token吞吐量大幅提升。
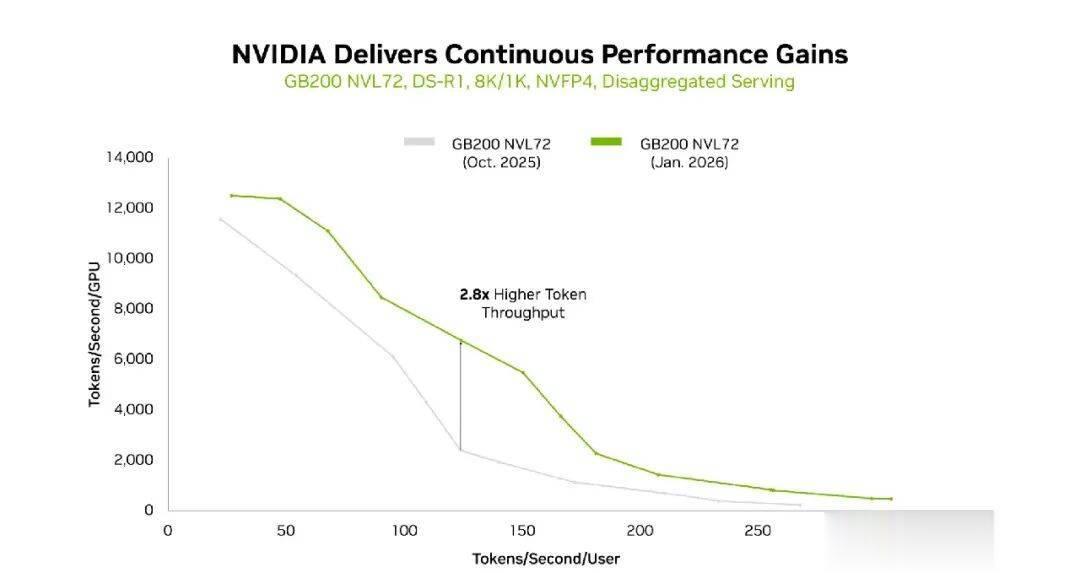
同样地,得益于最新NVIDIATensorRT-LLM软件与GB200NVL72的协同,在1K/1K序列长度下,DeepSeek-R1Token吞吐量同样大幅提升。
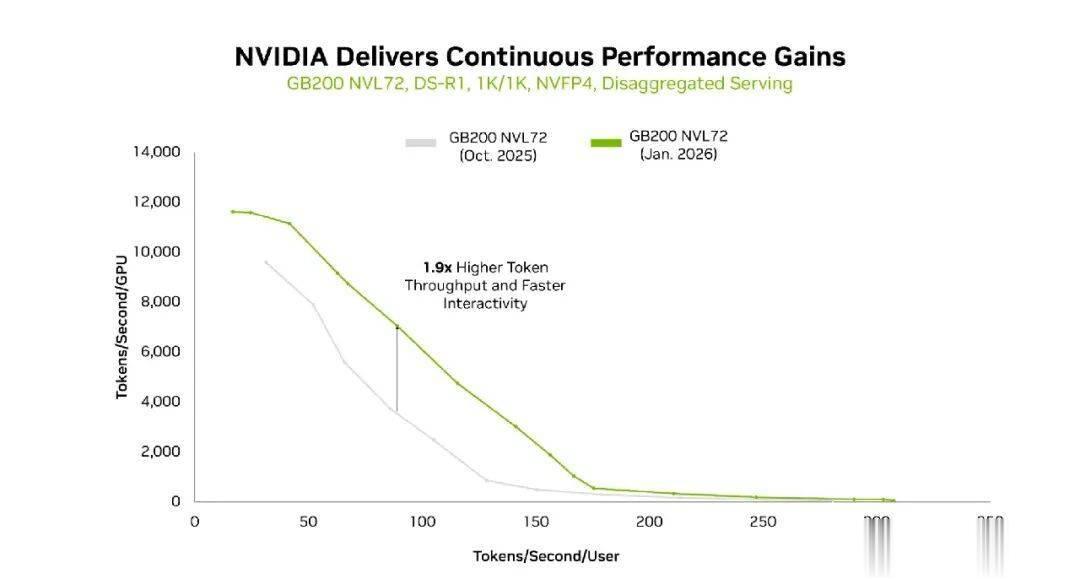
另外,在8K/1K、1K/1K两种输入/输出序列长度的吞吐量与交互性曲线上,GB200NVL72也展现出了领先的单GPU吞吐能力。
而TensorRT-LLM开源库(用于优化LLM推理)的最新增强功能,在同一平台上再次大幅增强了性能。在过去三个月中,每个BlackwellGPU的吞吐量提升高达2.8倍(这里指的是在8k/1k输入/输出序列长度下,去年10月到今年1月的Token吞吐量变化)。
这些优化背后的核心技术包括:
扩大NVIDIA程序化依赖启动(PDL)的应用:降低核函数启动延迟,有助于提升各种交互水平下的吞吐量;底层核函数优化:更高效地利用NVIDIABlackwellTensorCore;优化的All-to-all通信原语:消除了接收端的额外中间缓冲区。
有业内人士对英伟达放出的一系列图表进行了直观的解读,用一组数据来总结就是,「通过软硬件的深度协同,自2025年1月以来,英伟达已经将DeepSeek-R1(671B)的吞吐量提升了约36倍,这意味着单Token的推理成本降低到了约1/32。」

利用多token预测和NVFP4技术加速NVIDIAHGXB200性能
NVIDIAHGXB200平台由八个采用第五代NVLink互连和NVLinkSwitch连接的BlackwellGPU组成,在风冷环境下也能实现强大的DeepSeek-R1推理性能。
两项关键技术使HGXB200上的DeepSeek-R1推理性能大幅提升。第一项技术是使用多token预测(MTP),它可以显著提高各种交互级别下的吞吐量。在所有三种测试的输入/输出序列组合中都观察到了这一现象。
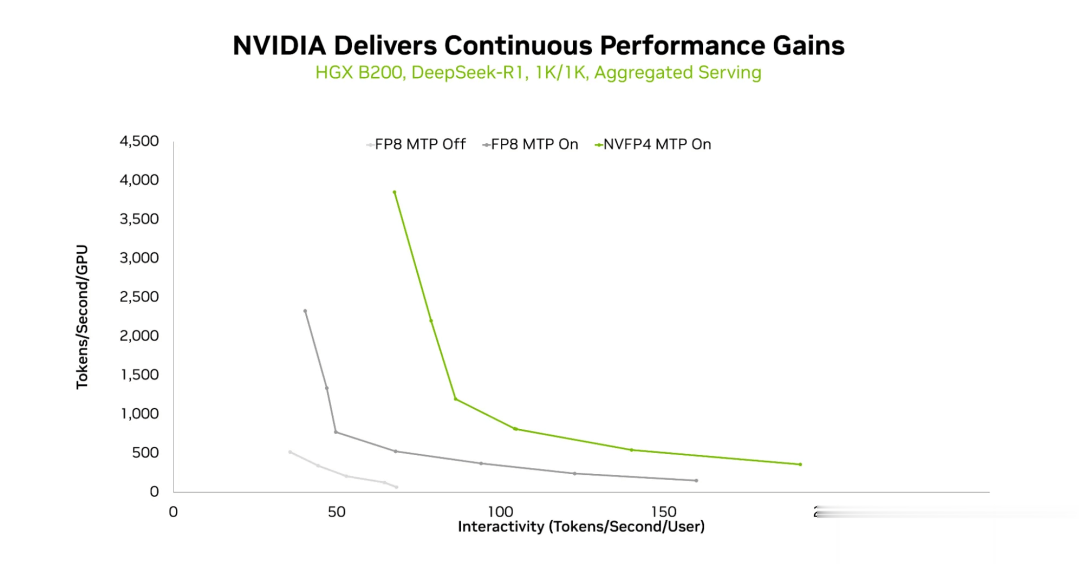
在HGXB200平台上,使用1K/1K序列长度和聚合服务模式下,FP8(不带MTP)、FP8(带MTP)和NVFP4(带MTP)的吞吐量与交互性曲线对比。
第二种方法是使用NVFP4,充分利用BlackwellGPU计算能力来提升性能,同时保持精度。
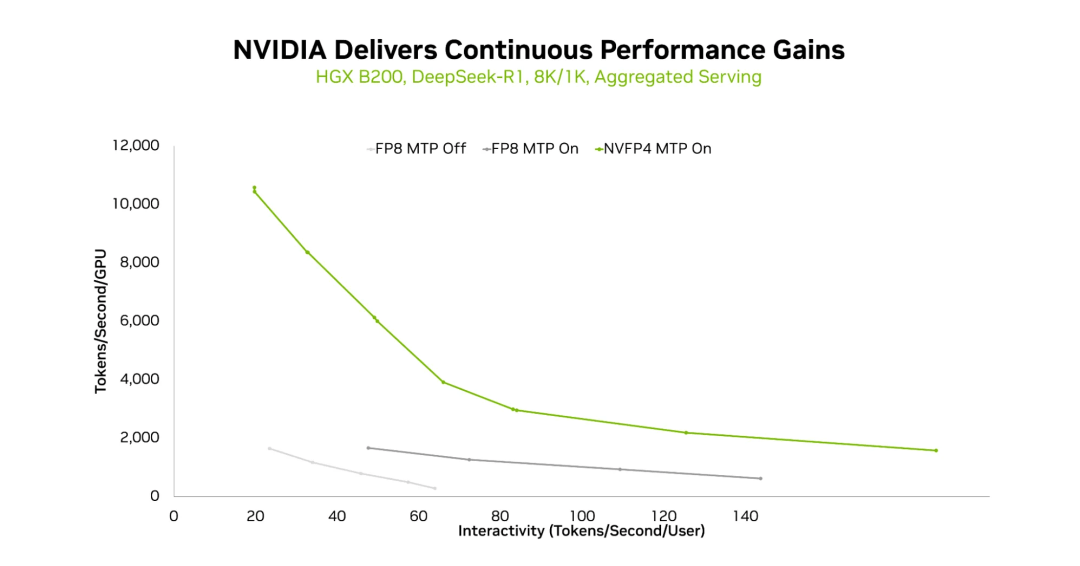
在HGXB200平台上,使用8K/1K序列长度和聚合服务模式下,FP8(不含MTP)、FP8(含MTP)和NVFP4(含MTP)的吞吐量与交互性曲线对比。
NVFP4使用在完整的NVIDIA软件栈上(包括TensorRT-LLM和NVIDIATensorRT模型优化器),以确保高性能并保持精度。这使得在给定交互级别下能够实现更高的吞吐量,并且在相同的HGXB200平台上,可以实现更高的交互级别。
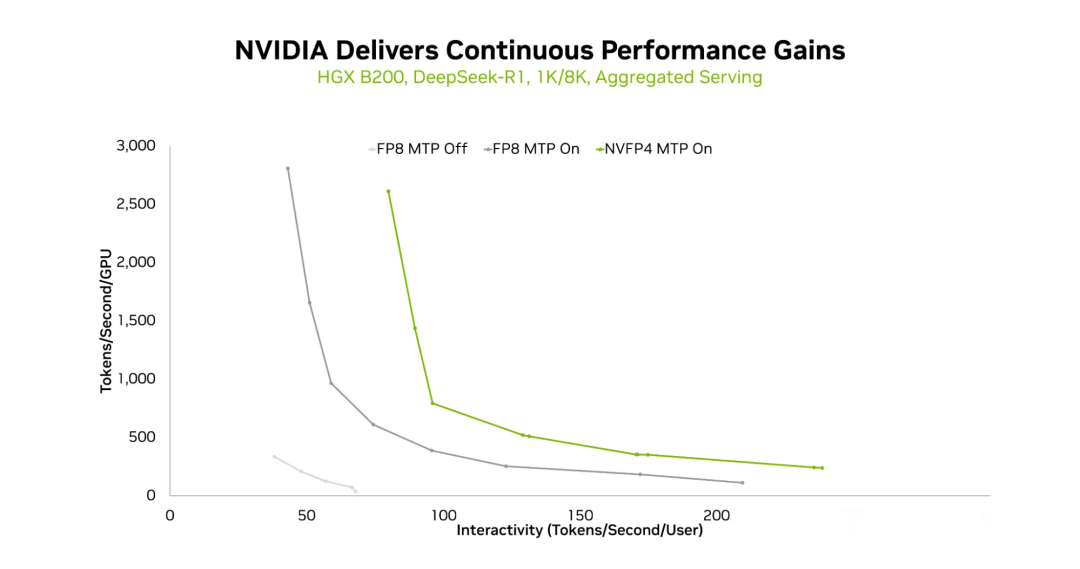
在HGXB200平台上,FP8(无MTP)、FP8(有MTP)和NVFP4(有MTP)的吞吐量与交互性曲线,序列长度分别为1K和8K,并采用聚合服务模式。
英伟达表示,其正在不断提升整个技术堆栈的性能,可以帮助用户基于现有硬件产品,持续提升大语言模型的工作负载效率,提升各种模型的token吞吐量。
博客地址:
https://developer.nvidia.com/blog/delivering-massive-performance-leaps-for-mixture-of-experts-inference-on-nvidia-blackwell/