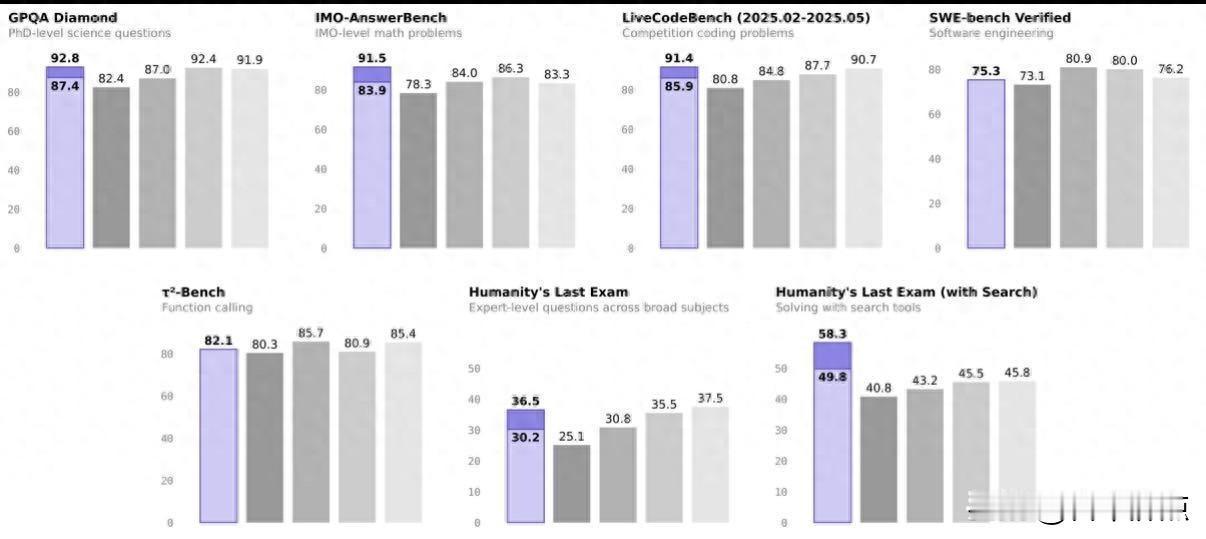
万亿参数模型上线了,它真能干实事还是光会吹牛?太空里都能跑的大模型到底有多猛。 今天早上刷到新闻,阿里昨天发布了新模型Qwen3-Max-Thinking。不是那种悄悄更新的小版本,是正儿八经开发布会、挂官网首页的旗舰款。参数超万亿,数据喂了36T tokens,听着就吓人。但最让我上头的是,它在“人类最后的测试”HLE里拿了58.3分,比GPT-5.2和Gemini 3 Pro高出一截。这分数不是闭门造车算出来的,是真拿搜索引擎、代码解释器、记忆模块自己动手干活测出来的。 以前总以为AI答得快就是强,现在发现它得知道啥时候该查、啥时候该算、啥时候该翻旧账。Qwen3-Max-Thinking自己会判断,比如你问“今年最新个税起征点”,它自动联网搜;你让它解个物理题,它顺手调出代码工具验算。不用你一步步点鼠标,也不用输一堆提示词。我在网页版Qwen Chat试了两次,一次查政策,一次跑了个小Python脚本,确实没卡,也没胡说。 它还有个叫Test-Time Scaling的新东西。简单说,就是模型在回答时会“想三遍”:第一遍试错,第二遍总结哪步错了,第三遍才给出答案。不像以前一堆答案同时冒出来,一堆重复又没用的思路占着算力。这个技术让IMO数学题直接冲到91.5分,预览版甚至拿过AIME和HMMT双满分——这两个考试,连很多清北数学系学生都跪。 开源这块更实在。Hugging Face上数据显示,千问模型下载量破10亿,衍生模型超20万个,早把Llama甩身后了。我朋友做智能硬件的,上周刚用千问的轻量版接进一款教育机器人,说调API比以前稳,本地跑也够快。 还有个冷知识:去年11月,Qwen3大模型已经飞上天,在国星宇航的卫星计算中心跑起来了。不是传个模型上去摆拍,是真能在轨道上处理遥感图像、响应地面指令。全程不到2分钟,断网也不慌。 普通人现在去qwen.ai就能免费用,网页、PC端都有,APP也快上了。企业用户走阿里云百炼平台,API接口开着,能私有部署。它没有喊“颠覆一切”,只是把工具塞进模型里,再把模型塞进更多地方。 它不靠吹,靠干。