[LG]《Rethinking Language Model Scaling under Transferable Hypersphere Optimization》L Ren, Y Liu, Y Shen, W Chen [Microsoft] (2026)
在大语言模型预训练中,超参数(尤其是学习率)如何随模型宽度、深度、训练数据量、MoE稀疏度协同迁移,至今没有统一的理论框架。已有方法受困于两重缺陷:一是针对一阶优化器设计,无法直接适配超球面优化器;二是即便超参数调好,随着训练算力放大,logit爆炸、激活值离群点、损失尖峰仍如幽灵般反复出现,根本原因在于权重范数无法被结构性约束。
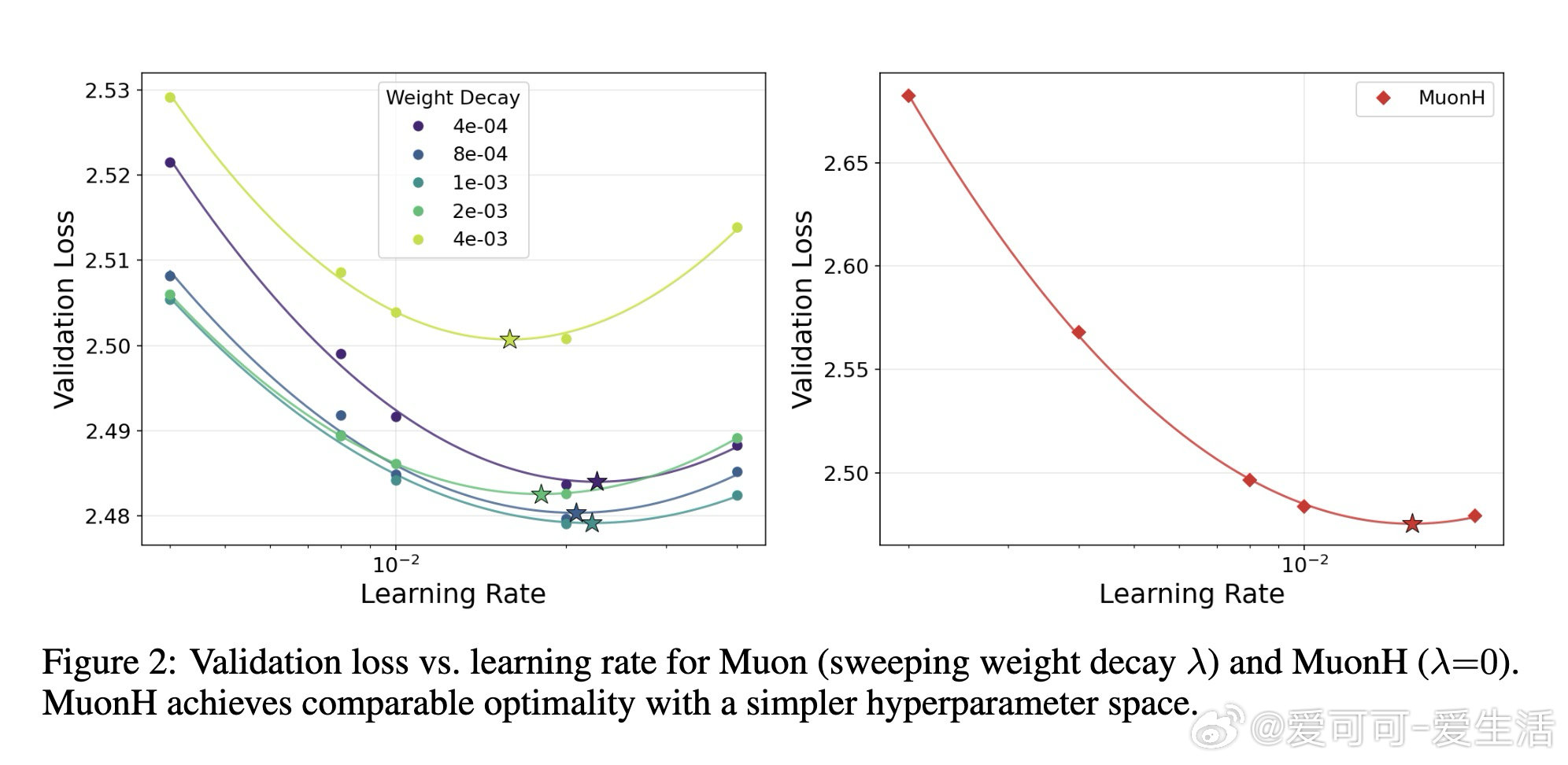
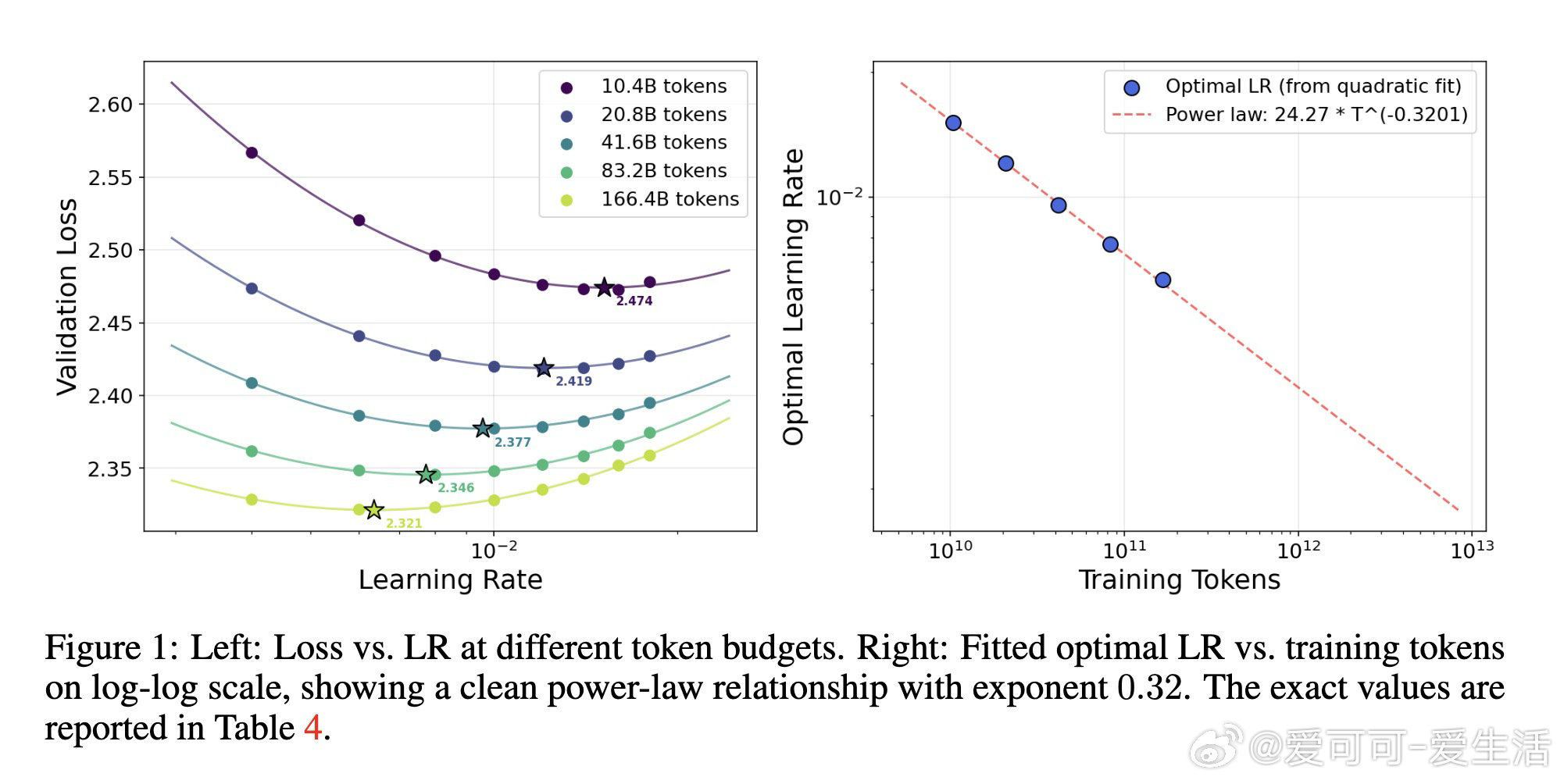
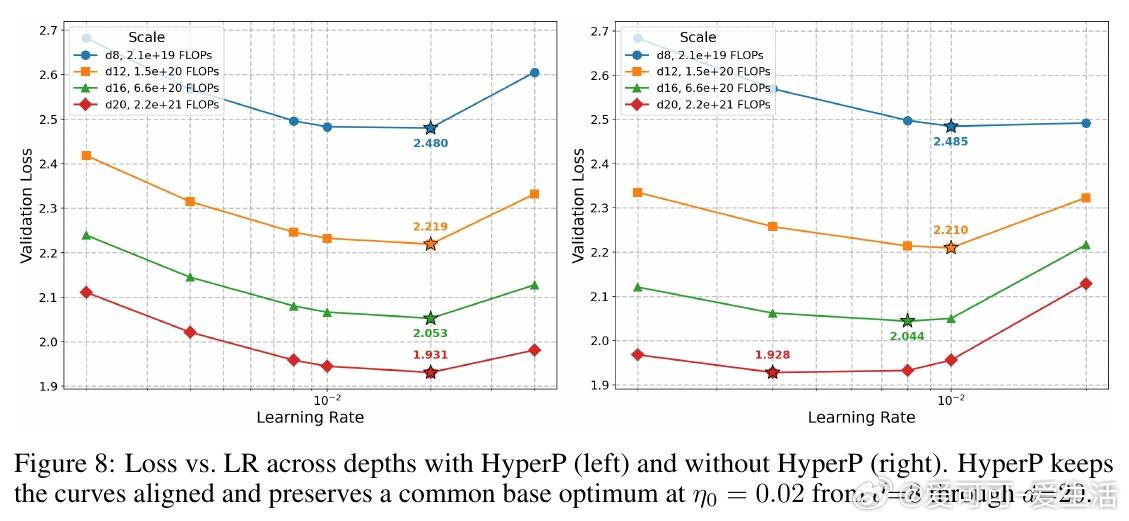
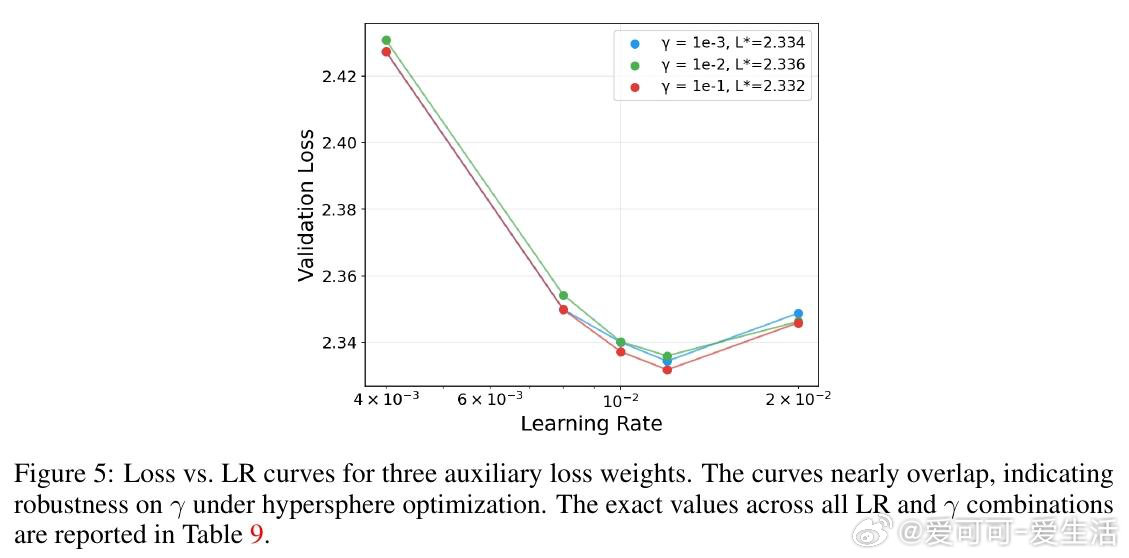
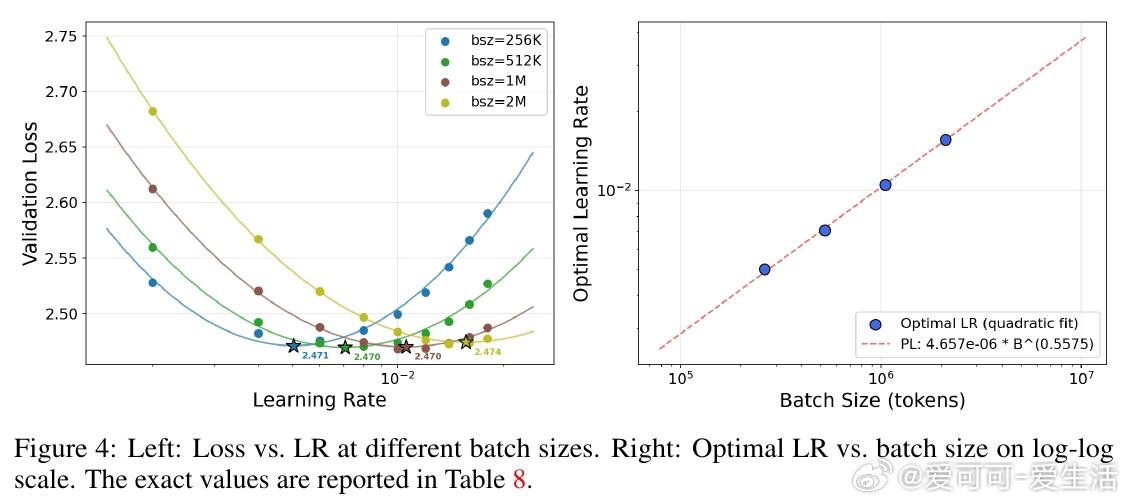
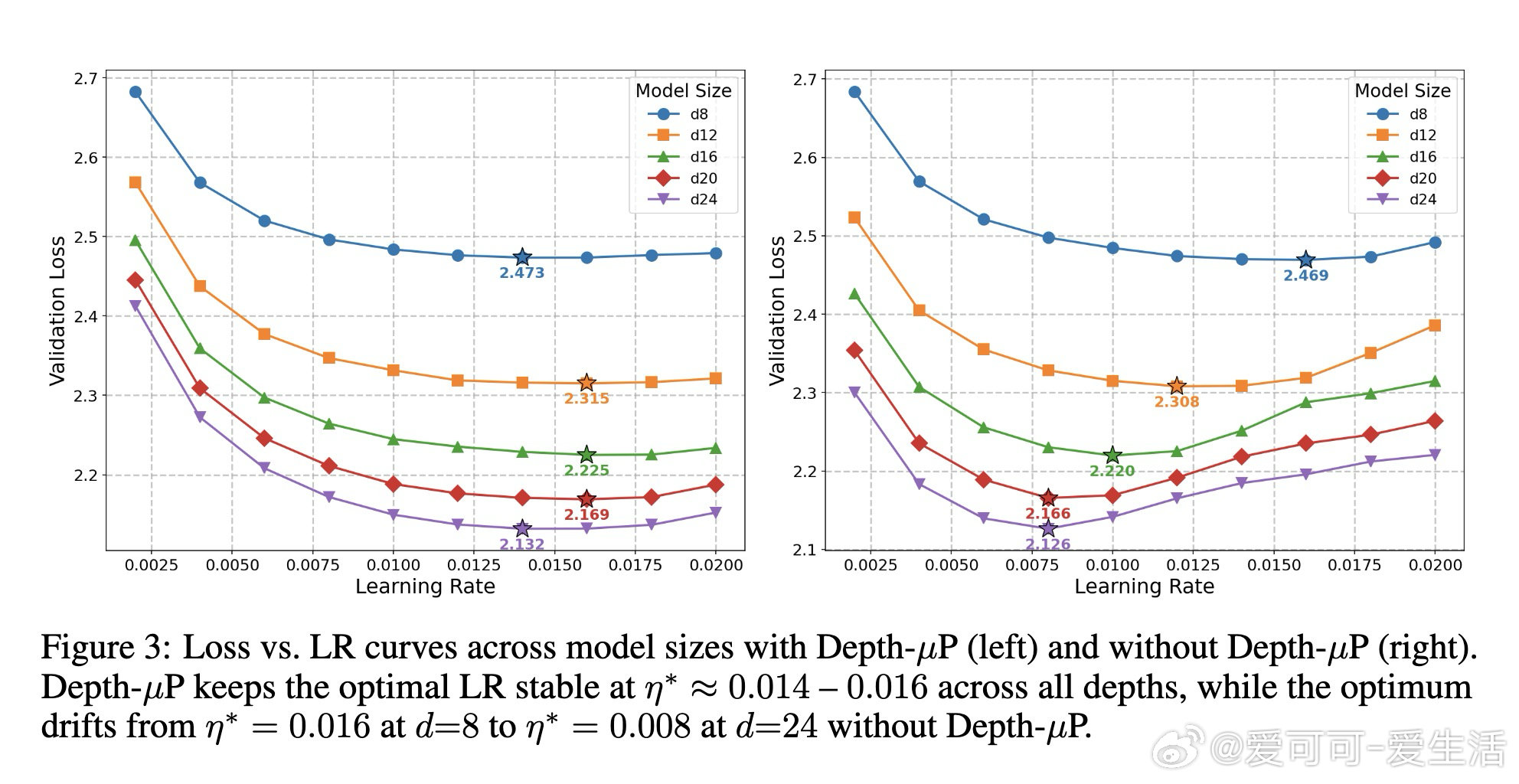
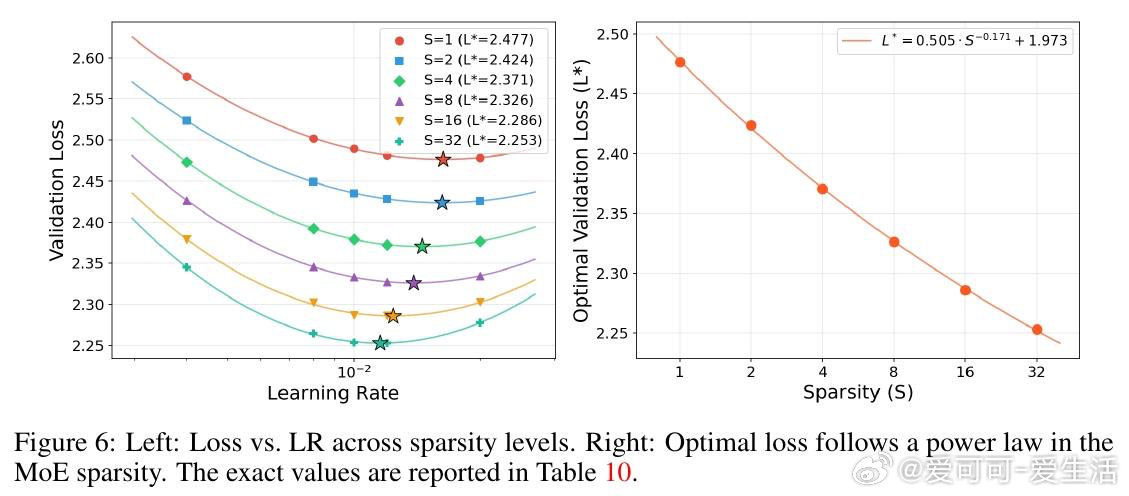
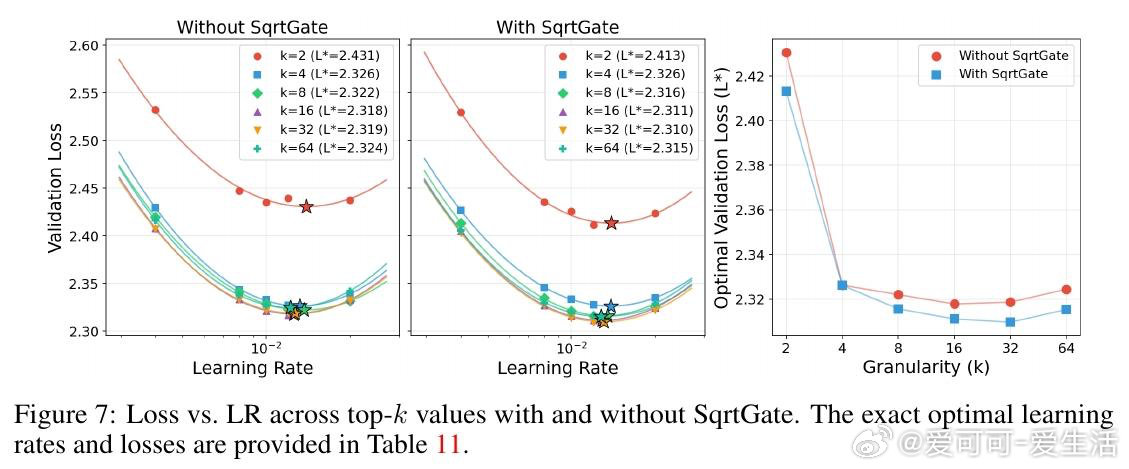
本文的核心洞见是:把"权重矩阵被约束在Frobenius球面上"这一几何事实重新看作超参数迁移的理论支点。由此推出三个互扣的结论:权重衰减在切平面投影下一阶消失(等价于把双变量搜索压缩为单变量);Depth-μP的深度缩放律在球面优化下依然必要(推翻了原作者"MuonH天然深度可迁移"的断言);最优学习率随训练token数呈幂律衰减,指数恰好是0.32——与AdamW的已知结果重合,暗示这是跨优化器的普遍常数。对MoE,用SqrtGate替换标准Softmax门控,将路由Z值峰值压低5倍,并实现跨粒度的输出RMS不变性。
这项工作真正留下的遗产是:首次为超球面优化建立了覆盖全部计算量维度的学习率迁移律,使"一次小规模调参、全轨迹复用"成为有理论保证的操作,并在6×10²¹ FLOPs处实现1.58倍计算效率杠杆。它为后来者打开的新门是:稳定性本身可以被"迁移"——更大模型的训练动态不比小模型更差,这为前沿算力下的可靠扩展提供了结构性保障。但尚未跨过的门槛是:0.32这一"魔法指数"缺乏理论推导,迁移律对混合架构、线性循环模型的适用性尚未验证,且Chinchilla最优假设本身依赖数据集需重新拟合。
arxiv.org/abs/2603.28743
机器学习 人工智能 论文 AI创造营