[LG]《SIEVE: Sample-Efficient Parametric Learning from Natural Language》P Asawa, A G. Dimakis, M Zaharia [UC Berkeley] (2026)
在自然语言上下文适配领域,如何将指令、规则或领域知识持久化入模型权重是一个悬而未决的难题。过去的上下文蒸馏方法受困于数据饥渴——需要大量查询样本或昂贵的专家标注轨迹,本质原因是训练时将全量上下文粗暴堆入所有样本,导致信噪比低、蒸馏质量差。
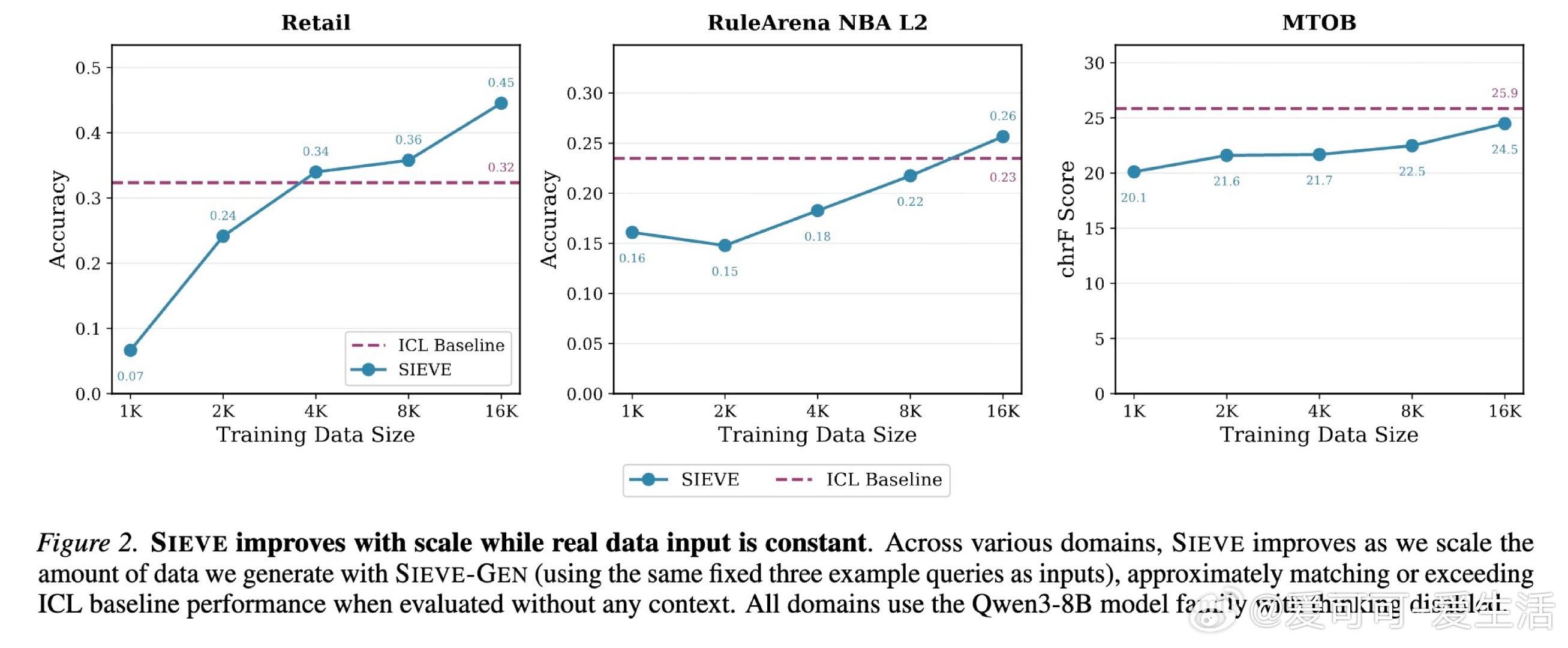
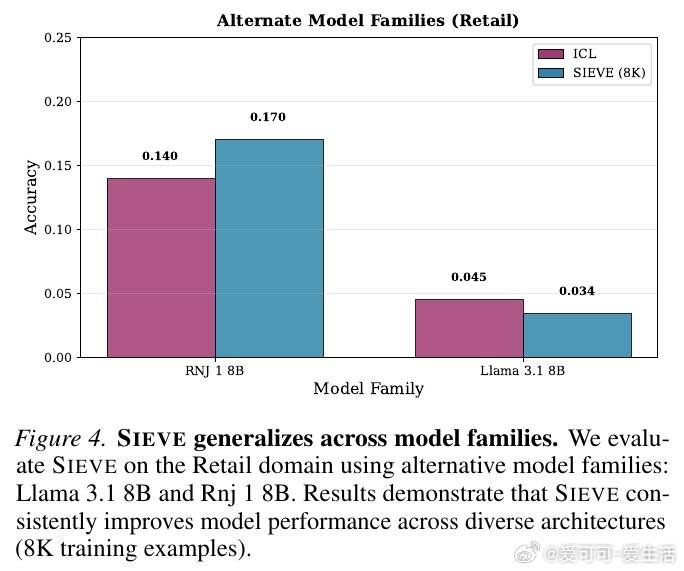
本文的核心洞见是:把自然语言上下文重新看作可分解的原子单元集合,而非不可分割的整体。由此,"按需配对"这一关键操作使问题得以解开——SIEVE-GEN 先将上下文拆解为独立规则单元,再用基础模型生成多样化查询,最后验证并筛选出每条查询真正适用的子集,让训练数据中每个样本只携带与其直接相关的上下文,从而以仅3个种子样本撬动高质量合成训练数据的生成。
这项工作真正留下的遗产是:证明了参数化学习可以与上下文学习的样本效率并存,无需大规模标注数据即可将复杂推理规则烧入权重。它为后来者打开的新门是研究"上下文可分解性"作为数据工程通用原则的更广泛适用性。但尚未跨过的门槛是:该方法依赖底座模型本身具备足够的推理能力——对于在上下文辅助下仍表现欠佳的弱模型,SIEVE 亦无能为力。
arxiv.org/abs/2604.02339 机器学习 人工智能 论文 AI创造营