[CL]《Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets》D Tran, D Kiela [Stanford University] (2026)
在多智能体系统(MAS)的比较研究中,"更强的性能"长期混淆于"更多的计算消耗"——多个智能体的协作本质上消耗了更多推理 token,使得架构优势与算力优势难以分离。现有评测方法缺乏对计算量的严格控制,令 MAS 的真实价值悬而未决。
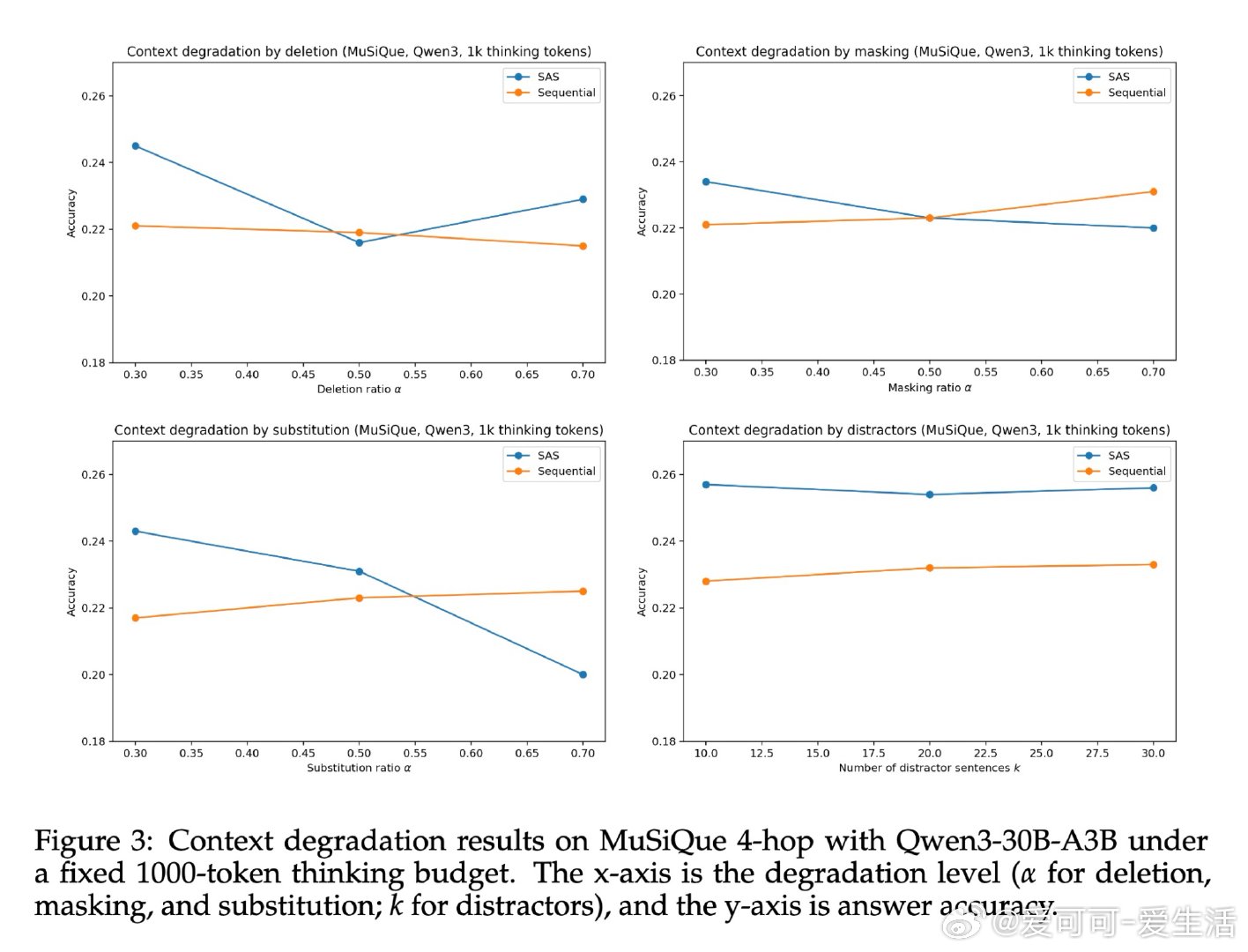
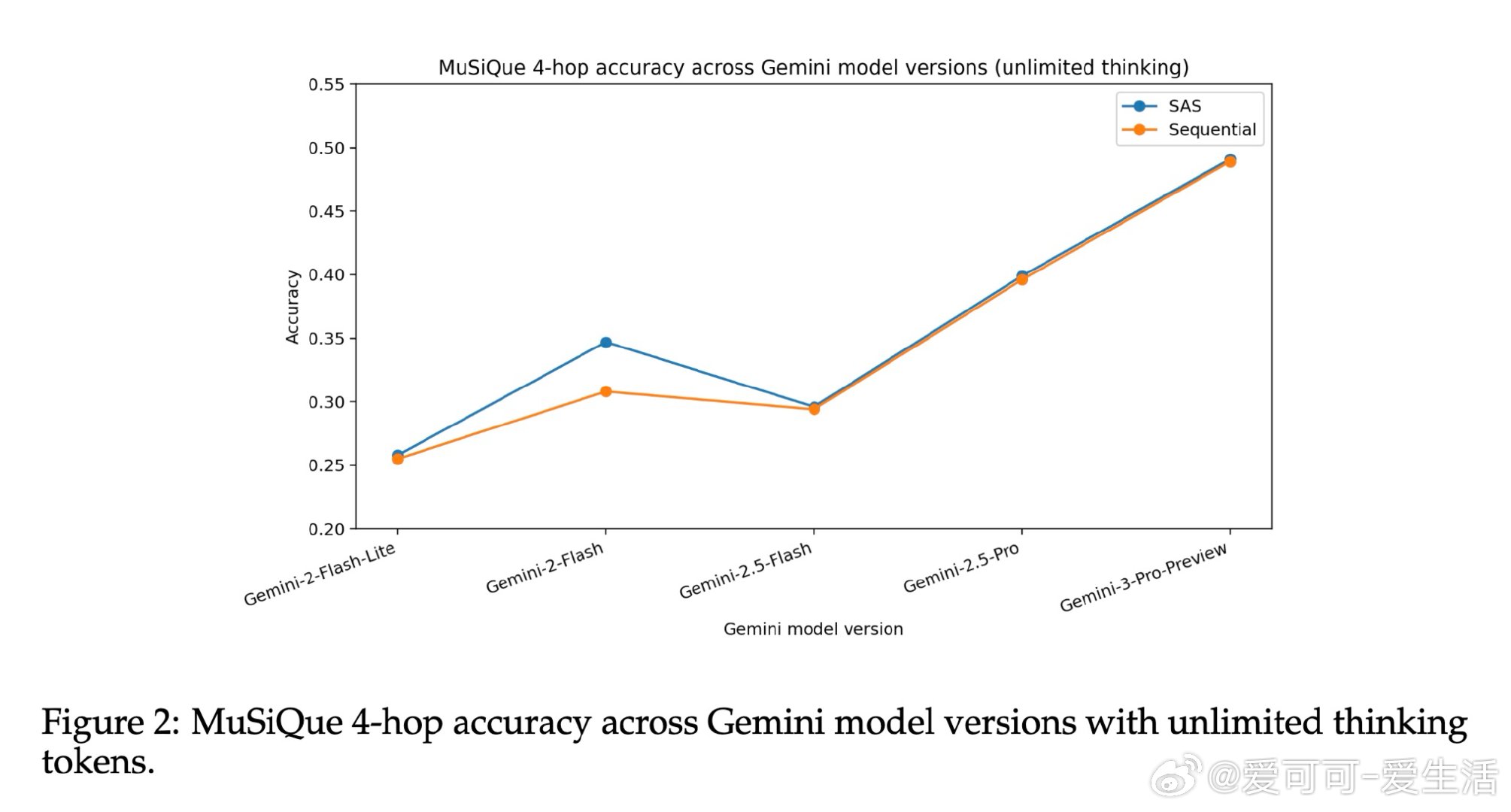
本文的核心洞见是:把多智能体间的消息传递重新看作一种信息压缩过程。借助数据处理不等式,可以证明任何从完整上下文提炼而成的中间消息,只会损失、而非增加对正确答案的预测信息量。由此推论:在相同推理 token 预算下,单智能体因保留完整上下文而天然占优;只有当单智能体的上下文利用能力因噪声或干扰而退化时,结构化多智能体才有机会反超。跨三类模型族、五种 MAS 架构的受控实验系统性地验证了这一预测。
这项工作真正留下的遗产是:为"算力对齐后 MAS 是否仍有优势"这一问题给出了信息论层面的否定性基准,并揭示了 API 层面 token 计数存在系统性虚高这一评测隐患。它为后来者打开的新门是:精确定位 MAS 真正有效的退化条件边界,而非将其视为通用解法。但尚未跨过的门槛是:研究仅限于文本多跳推理,工具调用、视觉输入及安全约束等场景下的结论是否成立,仍属未知。
arxiv.org/abs/2604.02460 机器学习 人工智能 论文 AI创造营