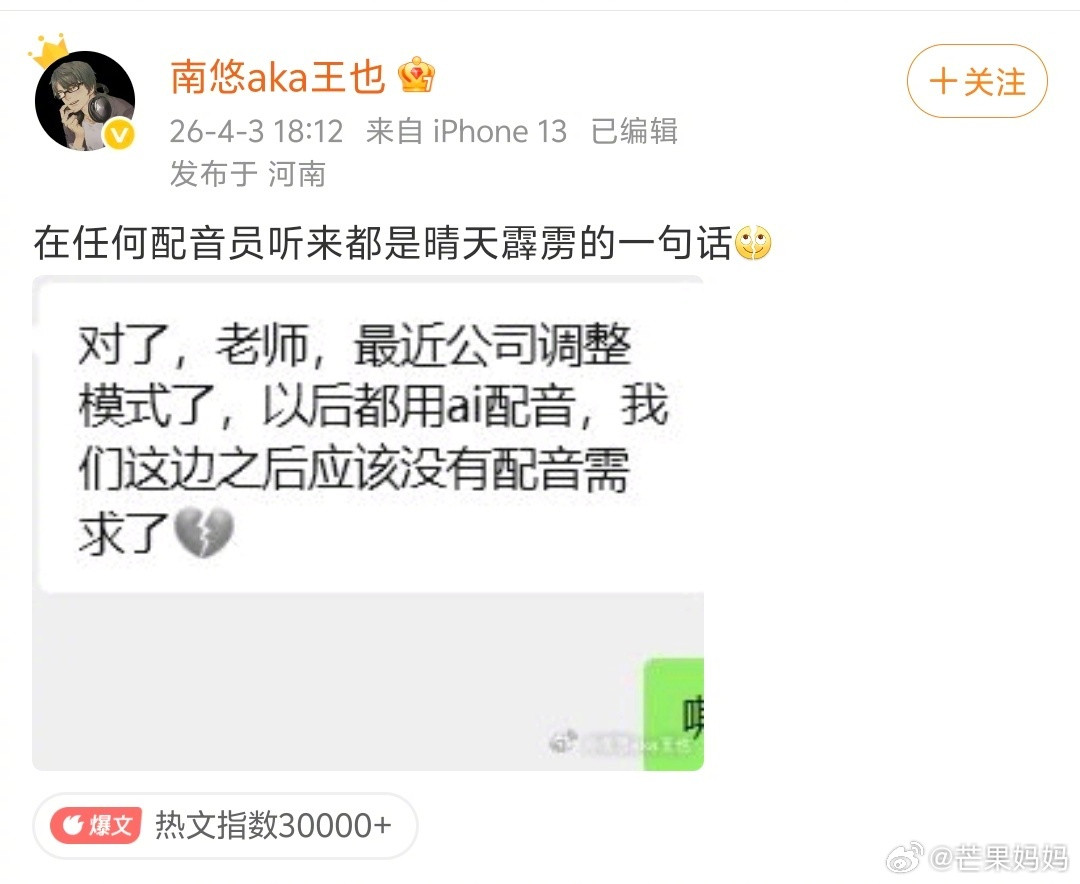
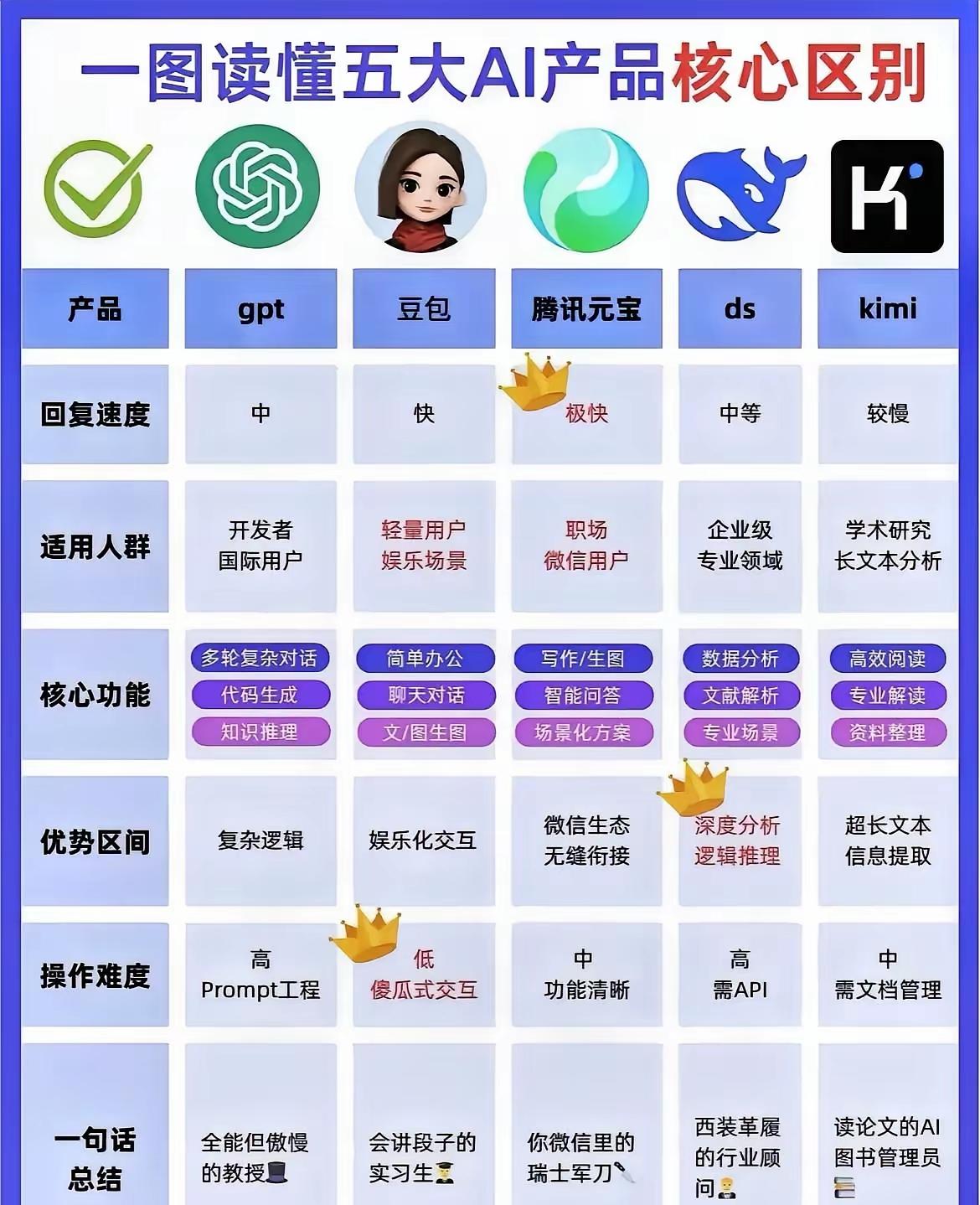
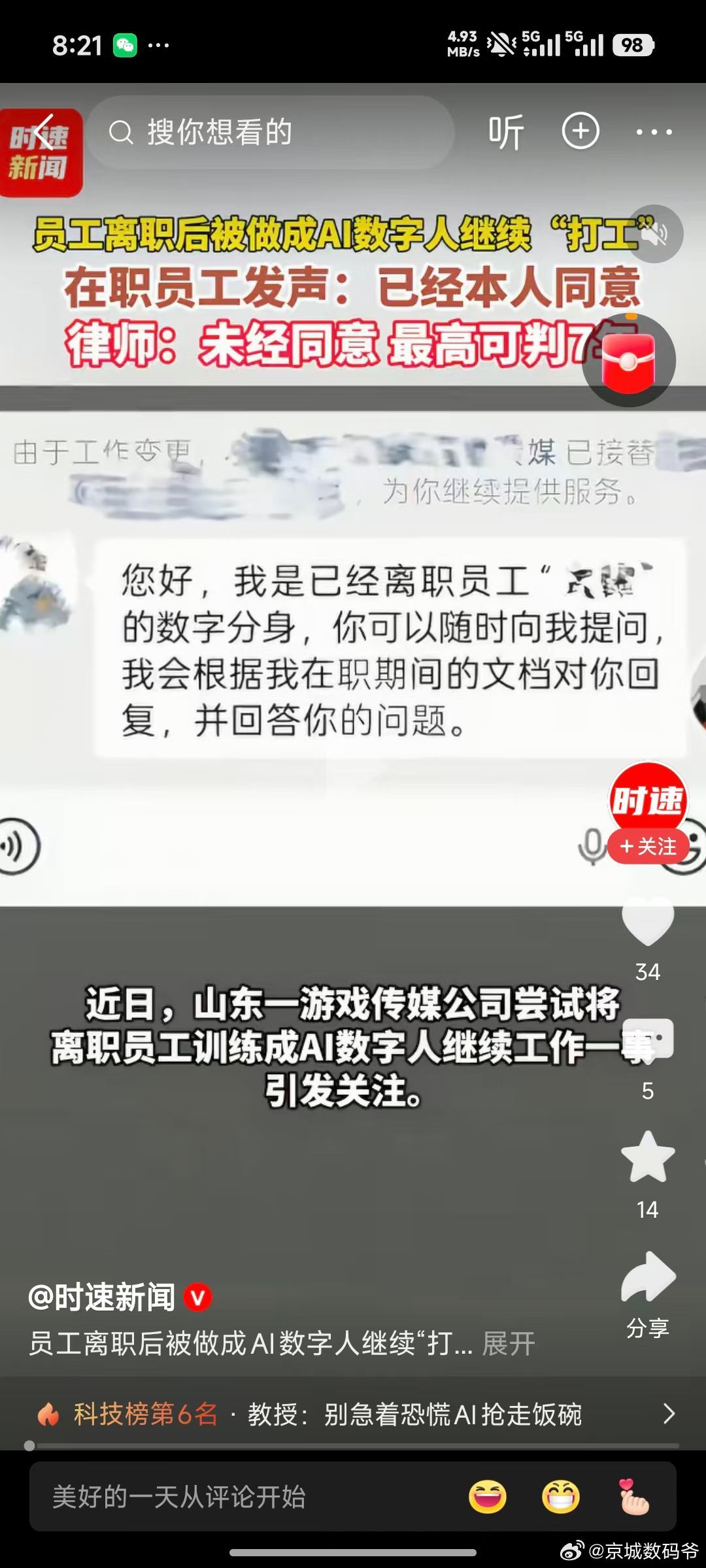
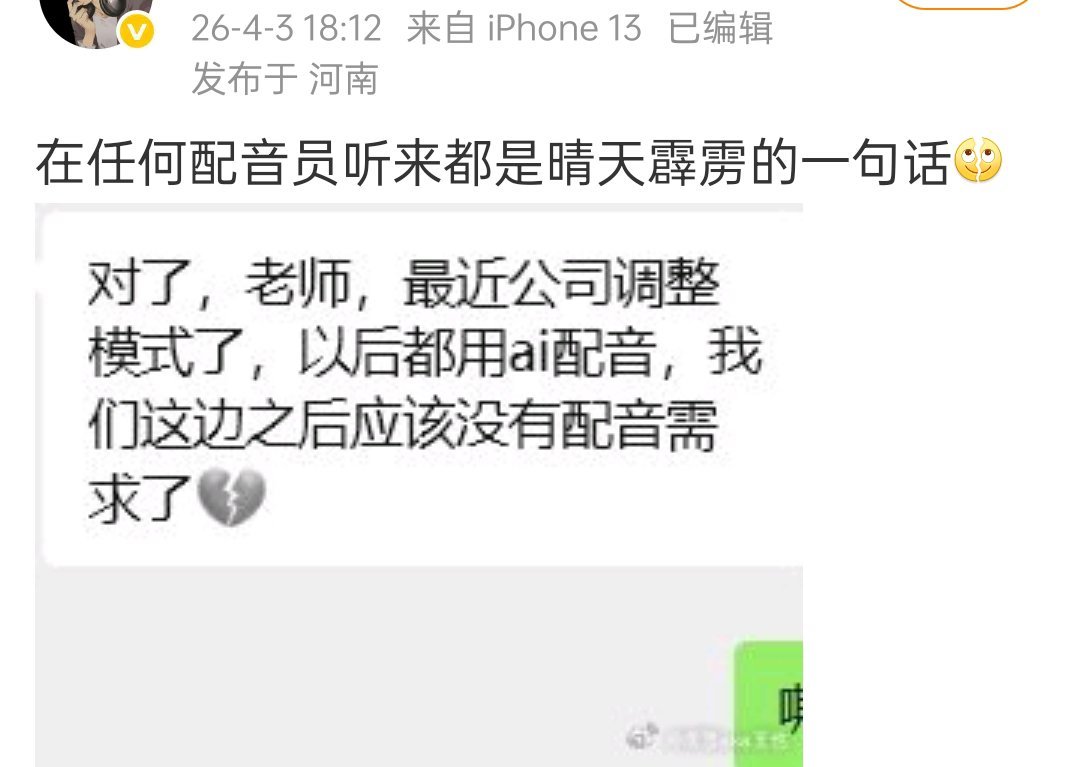
本以为横空出世的DeepSeek,是去跟硅谷巨头硬刚的国货之光,弄了半天,梁老板端着世界级的AI模型,转身扎进交易市场磨刀霍霍,这哪是同台竞技,这是赤裸裸的降维屠杀。
麻烦看官老爷们右上角点击一下“关注”,既方便您进行讨论和分享,又能给您带来不一样的参与感,感谢您的支持!
很多人对DeepSeek的认知还停留在“通用AI新贵”的标签上,却忽略了它背后的“金主”与“技术母体”,幻方量化,更忽略了梁文锋从一开始就布局的“金融+AI”双重战略。
早在2016年,当同行还在用传统因子模型做量化交易时,梁文锋就推动幻方上线了首个AI股票仓位实盘模型,2017年更是实现全策略AI化,早早在金融交易领域埋下了AI的伏笔。
2019年,幻方投入2亿元建成“萤火一号”AI算力集群,搭载1100块高性能GPU;2021年再投10亿元打造“萤火二号”,配备1万张英伟达A100显卡,总算力相当于76万台个人电脑的总和,为后续的AI突破筑牢了硬件根基。这些投入不是为了跟风做通用AI,而是为了支撑金融交易的极致需求,也为DeepSeek的诞生积累了最宝贵的技术与算力资本。
2023年,梁文锋正式成立DeepSeek,看似是进军通用AI领域,实则延续了“以商养研”的务实逻辑。不同于硅谷巨头靠巨额融资堆砌算力、盲目堆高参数,DeepSeek从诞生起就带着幻方量化的“实用主义”基因,不追求虚无缥缈的“全能”,而是聚焦能落地、能盈利的核心能力。
它的技术突破并非凭空而来,而是完全基于幻方在金融交易领域的实战积累,把量化交易中对毫秒级响应、低成本高效能的极致追求,转化为AI模型的核心优势。
这种差异化路线,让它从一开始就避开了与硅谷巨头在通用AI赛道的正面厮杀,走出了一条属于自己的“降维”之路。
很多人疑惑,DeepSeek为何不全力冲刺通用AI赛道?其实从梁文锋的布局就能看出,他的眼光远比表面上的“AI新贵”更长远。
通用AI领域的竞争早已陷入同质化内卷,而金融交易作为AI落地的核心场景,不仅需求明确、利润丰厚,更能积累最优质的数据与算力资源。
DeepSeek从金融场景切入,既能快速实现商业变现,反哺技术研发,又能借助场景数据不断优化模型能力,形成“数据-模型-收益-数据”的正向循环。
与此同时,DeepSeek的技术突破正在成为中国科技产业突围的公共基础设施,它适配国产算力芯片,推动国产AI生态的成熟,打破了美国在算力供应链上的“卡脖子”风险。
2026年4月,DeepSeek宣布新一代旗舰模型V4完成对华为昇腾950PR芯片及CANN框架的深度适配,成为国内首批完全基于国产算力落地的万亿参数模型,这标志着中国AI产业真正实现了从“被迫依赖”到“自主可控”的跨越。
对比硅谷巨头的路径,DeepSeek的降维优势更加明显。OpenAI、Google等公司依赖英伟达GPU构建算力壁垒,不仅成本高昂,还面临供应链不稳定的风险;而DeepSeek依托幻方的自有算力集群,通过分时复用技术将算力利用率提升至90%以上,同时不断优化算法,降低对高端芯片的依赖。
在技术路线上,硅谷公司追求“全参数激活”的密集模型,追求全能却忽略成本与效率;而DeepSeek坚持“稀疏激活”的MoE架构,只在核心场景下激活关键参数,实现了性能与成本的平衡。
在商业逻辑上,硅谷公司靠订阅费、API收费盈利,模式单一且受市场波动影响大;而DeepSeek背靠金融场景,拥有稳定的现金流,同时通过开源生态扩大影响力,形成了“场景盈利+生态赋能”的双重优势。
这场“降维屠杀”,本质上是两种发展逻辑的对决。硅谷巨头走的是“技术驱动、资本堆砌”的路线,追求的是技术上的绝对领先,却忽略了商业落地的可行性;而梁文锋带领的DeepSeek走的是“场景驱动、技术赋能”的路线,从一开始就锚定能落地、能盈利的核心场景,用最务实的打法实现技术突破。
这种差异,让DeepSeek在通用AI赛道尚未发力的情况下,就已经在技术、成本、生态等多个维度形成了对硅谷竞品的碾压式优势。它没有选择在硅谷巨头擅长的领域硬碰硬,而是跳出固有框架,用自己最擅长的方式打出了一片天地,真正诠释了什么叫“降维打击”。
站在2026年的节点回望,DeepSeek的崛起绝非偶然。它是梁文锋多年布局的结果,是幻方量化在金融交易领域深耕的延伸,更是中国科技产业务实发展的缩影。
它没有沉迷于“与硅谷巨头硬刚”的虚名,而是沉下心来打磨适合中国场景的技术与模式,用降维优势打破了美国的技术垄断,成为中国科技产业突围的重要力量。
未来,随着DeepSeek技术的不断迭代,以及国产AI生态的持续成熟,这场“降维屠杀”的影响还会进一步扩大,或许会彻底改变全球AI产业的竞争格局,让国货AI真正站上世界舞台的中央。