[LG]《In-Place Test-Time Training》G Feng, S Luo, K Hua, G Zhang… [ByteDance Seed] (2026)
在长文本理解领域,LLM部署后权重冻结是一个根本性困境:模型无法在推理时动态吸收流式输入的新信息。已有的测试时训练(TTT)方案受困于三重枷锁——需要从头重训的架构不兼容、逐token更新导致的并行瓶颈、以及与下一词预测目标脱节的重构损失函数。
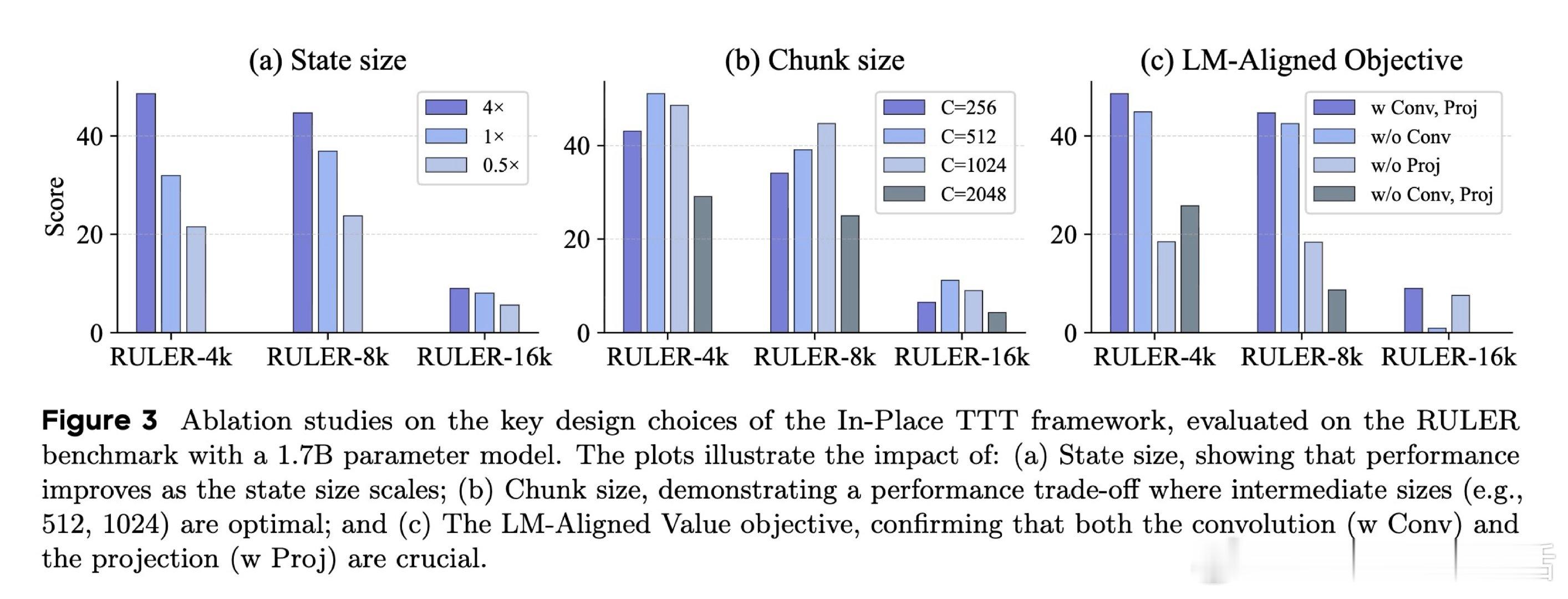
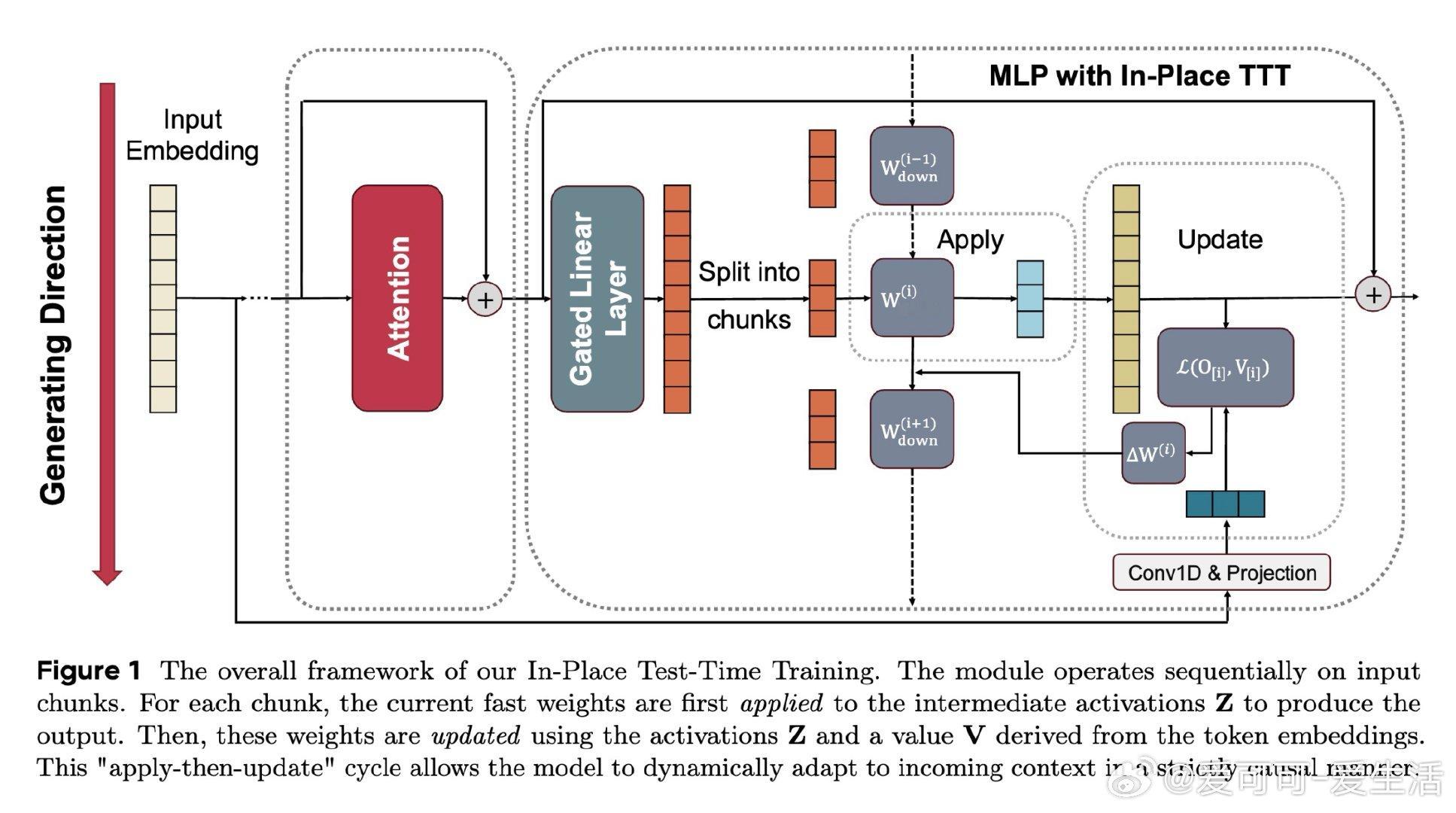
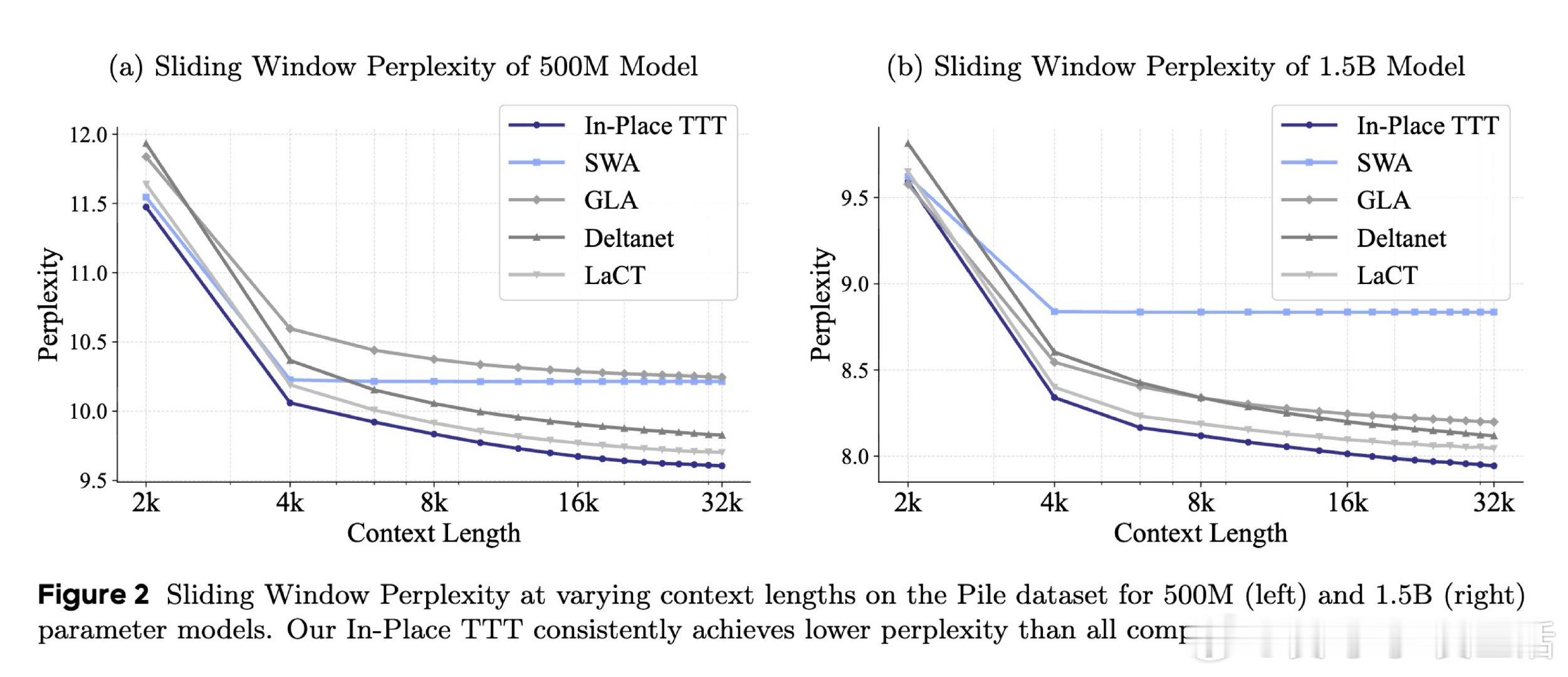
本文的核心洞见是:把MLP块的下投影矩阵重新看作可动态更新的"快权重"。这一原位替换无需改动预训练架构,让TTT从破坏性重构变为零成本植入。与此同时,以未来token嵌入为目标的NTP对齐损失,配合大块并行更新,在理论上保证了正确next token的logit单调提升,而传统重构目标对此毫无贡献。
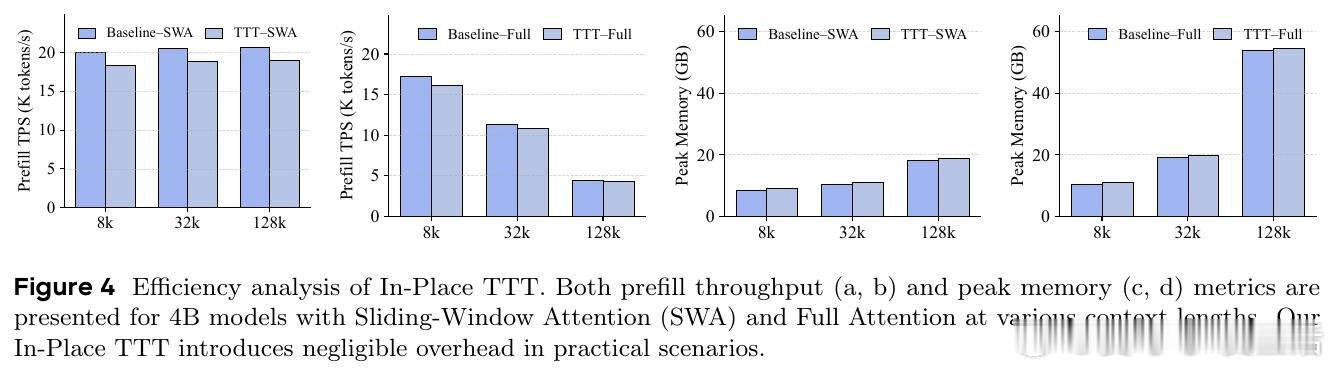
这项工作真正留下的遗产是:证明了预训练LLM可以在极低代价下获得在线持续学习能力——Qwen3-4B在128k上下文任务中超越了更大参数量的竞品。它为后来者打开的新门是将TTT与线性注意力、稀疏注意力等高效架构结合的可能性,但尚未跨过的门槛是:快权重的遗忘与覆盖机制仍依赖启发式重置,对真正跨文档的持续学习尚无系统性解答。
arxiv.org/abs/2604.06169
机器学习 人工智能 论文 AI创造营