[CL]《Tool-MCoT: Tool Augmented Multimodal Chain-of-Thought for Content Safety Moderation》S Zhang, D Zhou, Y Liu, Y Yang… [Google & Stanford University] (2026)
多模态内容审核领域,如何在保留大模型推理深度的同时,实现可规模化部署,始终是一道工程死结。现有方案只能二选一:要么用大模型把关准确但算力昂贵,要么用小模型快速部署但遇到图文交叉语义时频频失判。根本矛盾在于,小模型缺乏足够的推理容量来整合视觉与文本的隐含关系。
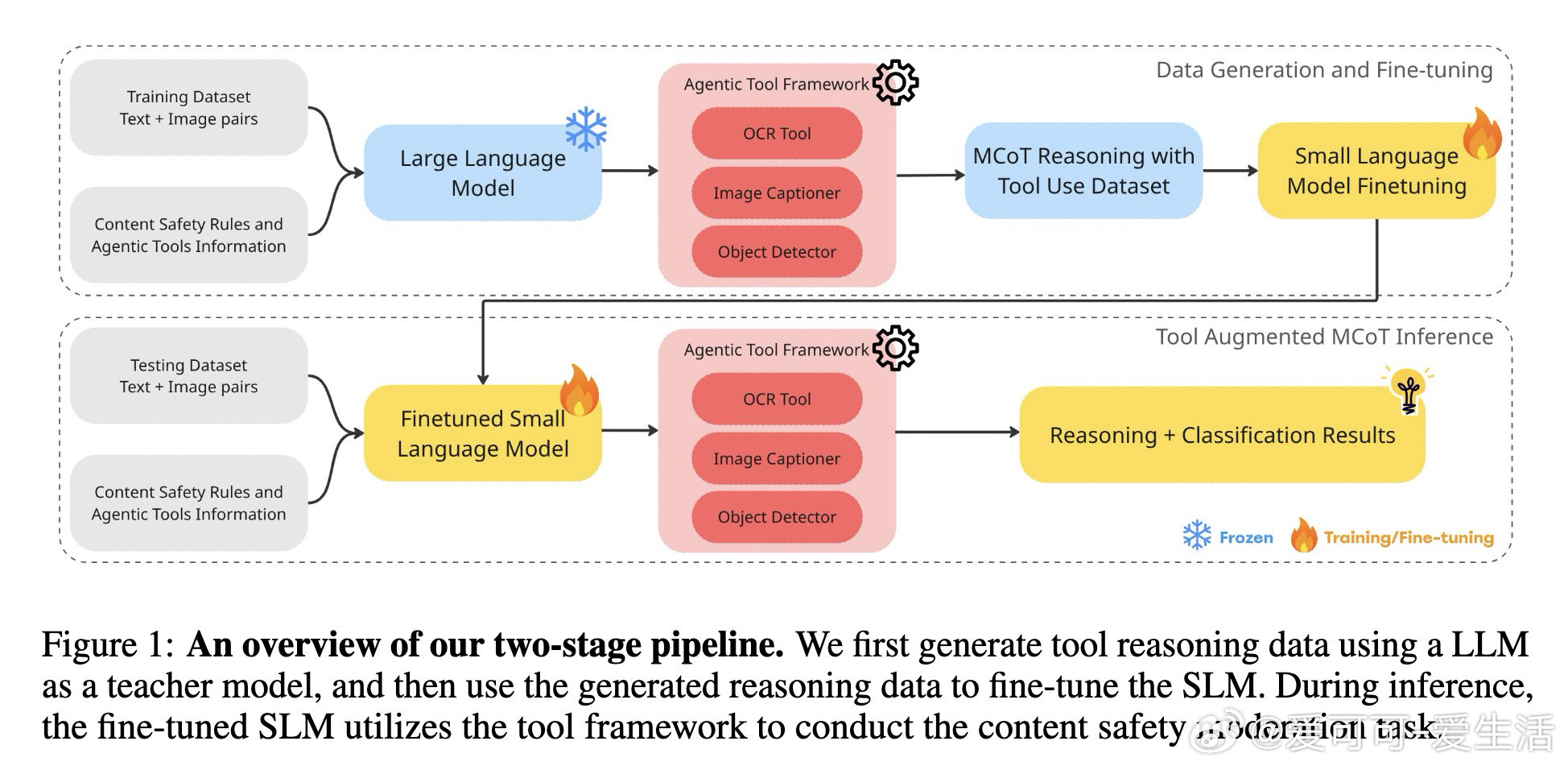
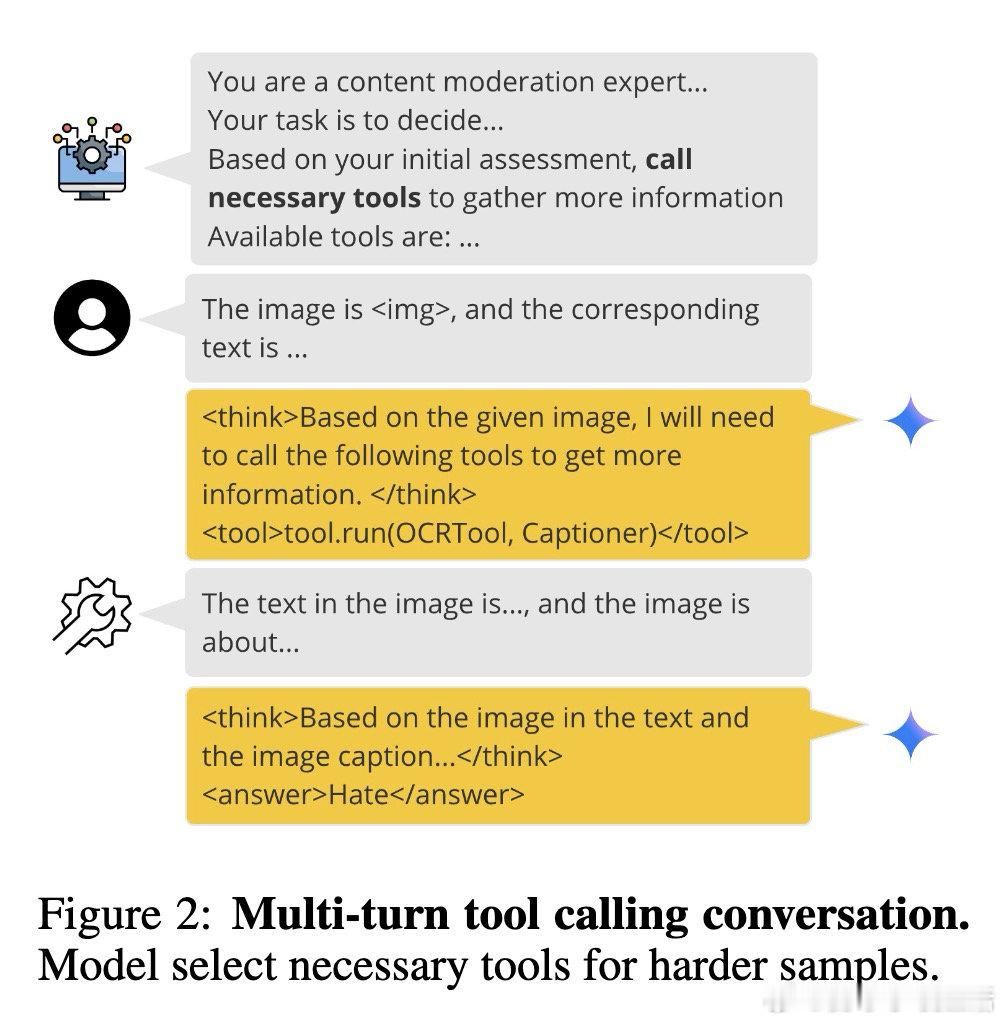
本文的核心洞见是:把"让小模型变聪明"重新看作"让小模型学会问对问题"。由此,用大模型生成含工具调用轨迹的思维链数据作为教师信号,再通过 LoRA 微调与强化学习,将"何时调用 OCR/图像描述/目标检测"这一决策能力蒸馏进 4B 参数的学生模型,使模型在推理时按需索取外部信息而非依赖内部记忆。
这项工作真正留下的遗产是:证明工具调用能力可以通过合成数据被蒸馏进小模型,而非大模型的专属特权。它为后来者打开的新门是:为边缘端部署的内容审核系统提供了一条可复制的"推理增强而非规模增大"路径。但尚未跨过的门槛是:工具调用的准确性仍依赖教师模型生成数据的质量,一旦教师模型本身在某类有害内容上存在盲区,学生模型将系统性地继承这一缺陷。
arxiv.org/abs/2604.06205
机器学习 人工智能 论文 AI创造营