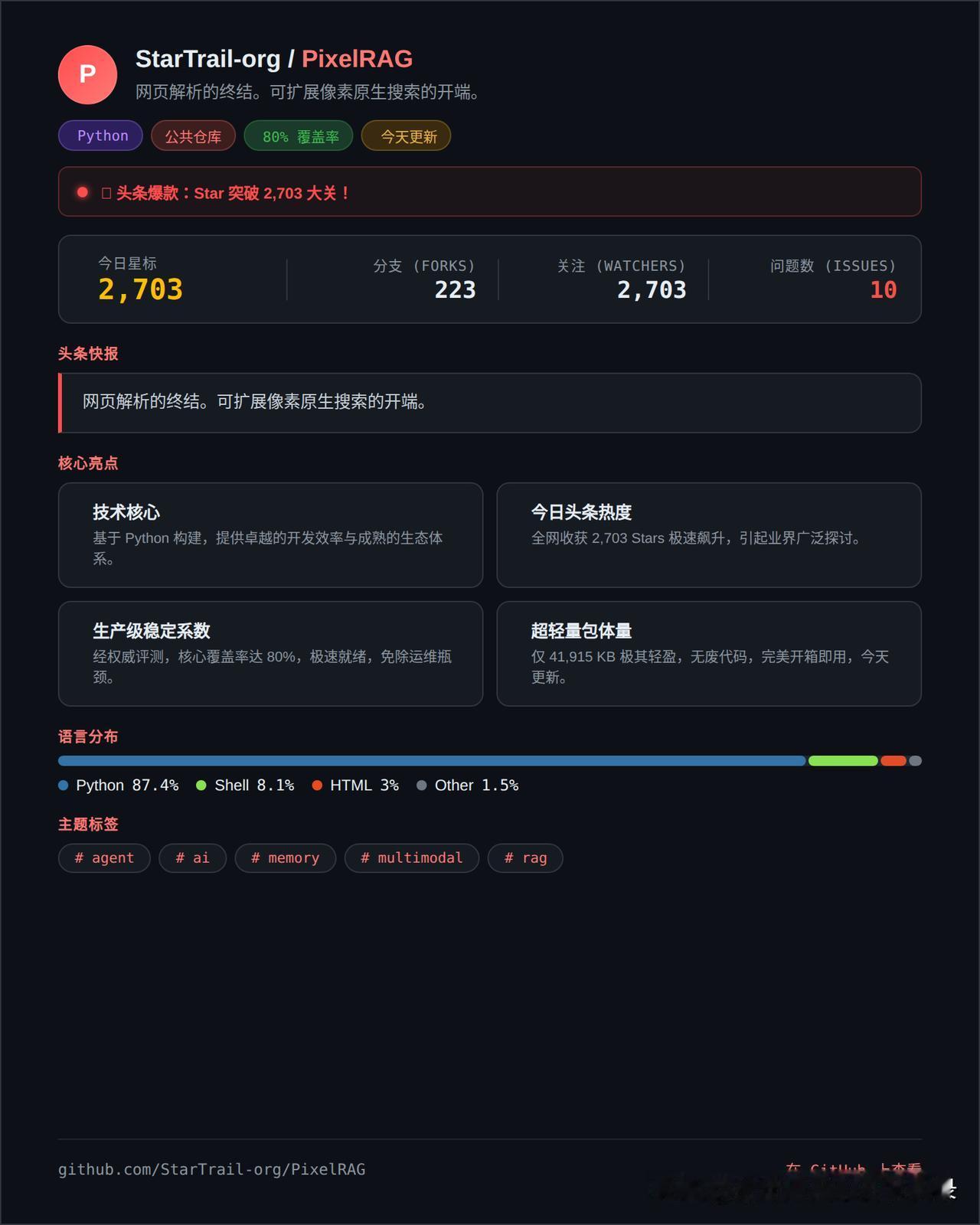
做RAG最头疼的是什么?当然是网页解析。PDF里的表格、数学公式、多列布局、图文混排——正则表达式和CSS选择器一顿操作,结果丢数据、乱格式,完全不像人看到的模样。一堆开发者被“解析地狱”折磨得想放弃多模态场景。
PixelRAG 直接掀了桌子:凭什么要解析?它说“我直接看像素”。把网页截图作为输入,用视觉模型(VLM)理解每一块像素内容,无论是图表坐标、手写笔记还是图片里的文字,全部保留原始布局和语义。这不叫“解析”,这叫“原生像素搜索”——让AI像人眼一样扫描屏幕,而不是靠脆弱的HTML结构猜内容。
2700多星不是白来的。这种模式彻底告别了“解析-清洗-索引”的连环bug,尤其适合那些需要理解页面整体视觉结构的场景,比如研究报告、产品介绍页、UI界面。你再也不用担心某个CSS改了导致整个搜索崩掉。
当然,这种“像素级”依赖更大模型算力,但带来的搜索准确性提升,对于追求多模态应用的团队来说,绝对值得。未来RAG的方向,很可能就是“所见即所得”。
所以,你平时被网页解析搞崩过心态吗?传统RAG工具里的那些解析器,你会考虑彻底弃用,换成这种像素级扫描的方案吗?欢迎在评论区留下你的踩坑记录和看法。