
【本文仅在今日头条发布,谢绝转载】
本文作者——田维新|爱奇艺科技频道前编辑
DeepSeek终于发布了V4模型。到底有多强?美国官方先给出了答案。
美国人工智能标准与创新中心(CAISI)给出的评估是:DeepSeek V4是中国AI公司迄今为止最强的大语言模型,但落后美国8个月。换句话说,水平大约和8个月前OpenAI发布的GPT-5相当。

(中国AI在全行业的推广应用非常迅速)
CAISI是美国商务部国家标准与技术研究院的下属机构,专门研究中国AI是否对美国构成威胁,再把差距量化成时间差。这帮人天天盯着中国模型测,数据还是有参考价值的。
测试中,“蓝队”是美国大模型,选手包括OpenAI、Anthropic等;“红队”是中国大模型,参测的有阿里通义千问、月之暗面KIMI以及DeepSeek。每一个红点都代表当下时间两队各自的最高水平,只看模型性能,不考虑成本等因素。
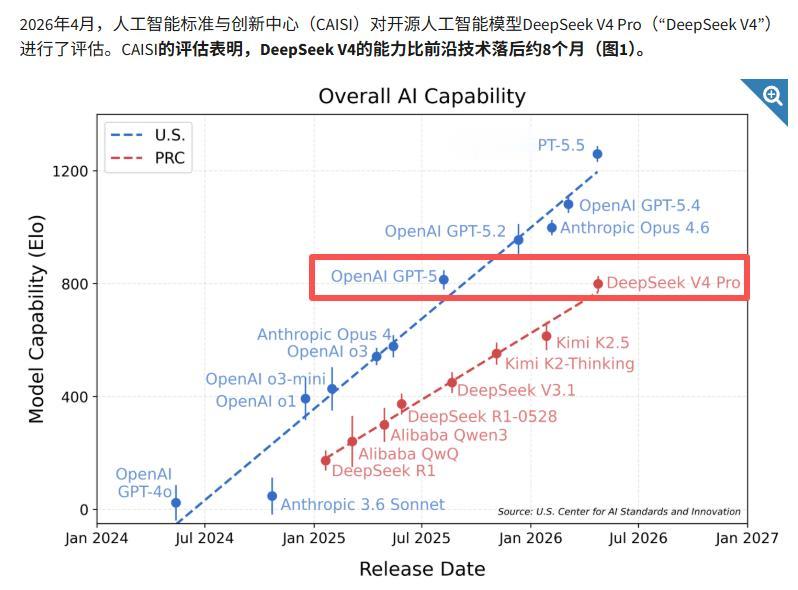
(美方公布的差距图,图中也暗示“中美AI差距在拉大”,这一点令人质疑)
美国人对此挺乐观。英伟达CEO黄仁勋一年多前还说,中国AI水平对比美国只是略有落后,随时能赶上。现在CAISI的数据却显示,“红蓝”之间的差距在拉大——2025年1月DeepSeek R1发布时,差距只有4个月,现在已经扩大到8个月,蓝队评分还远超红队30%。
不过DeepSeek自己也大方承认了差距。官方技术论文写道:V4的推理和智能体能力与GPT-5.2、Gemini 3.0 Pro和Claude Opus 4.5相当,比目前最先进的模型落后大约3到6个月。
不同测试标准下评分有差异,商务部和DS官方这点“误差”可以忽略不计。一个基本事实是确定的:中美在大模型前沿竞争上确实存在差距,而且短期内不会被抹平。
但这就等于美国赢了吗?远没有。
CAISI的报告里还藏着一行关键信息:红队任何一个模型的训练成本,都远远低于蓝队。GPT长期受困于超高的训练费用,单次训练成本在15亿美元级别。
这说得还算保守了。OpenAI的大模型训练推理都要依赖超大计算集群,动辄上万个高性能计算卡。不仅卡贵,把上万张卡“组装”成集群的成本也相当恐怖。

(AI计算集群成本极高)
目前比较可靠的数据是,OpenAI使用的计算集群归属微软Azure数据中心,买英伟达GPU花了约20亿美元,集群搭建成本约10亿美元,再加上存储设备、散热系统、电力系统等投入,一座能训练GPT-5的数据中心总投入在百亿美元级别。
反观红队这边,任何一个大模型的单次训练成本不超过1000万美元,数据中心投入保守估计只要美国的五十分之一。
至于怎么做到的、用了什么方法、有没有“蒸馏”国际一流大模型,在今天这个竞争环境下已经不那么重要了。
训练成本低,推理成本自然也跟着低。DeepSeek V4的平均使用成本只有GPT-5的四分之一。中国用户现在可以用四分之一的价格,体验到大约大半年前GPT-5同等性能的大模型,这本身就是巨大的成功。
有人可能会问:光便宜有什么用?DeepSeek以前不是经常“已读乱回”,用户反而要多花钱纠错?
以前确实有这个毛病,也是DS最大的争议点之一。CAISI这次也专门测了这个指标。
结果显示,V4 Pro在面对蓝队性价比最高的大模型时,依旧表现出极高的端到端性价比。即便把反复消耗token的纠错成本算进去,红队依然7局5胜。

(Deepseek表现抢眼,成本优势明显)
AI成本问题已经成了国际共识。AI竞争最激烈的部分,其实是应用普及率的竞争。高价开发的GPT、Claude确实性能更强悍,面对复杂问题时更得心应手。
但放眼当下的应用场景,很多时候并不需要那么极致的推理性能。在大量高频次、低智能需求的场景下,用户反而主动选择“头脑更简单”但响应更快、性价比更高的模型。比如AI客服、AI教育、AI翻译等,这些场景占据了token消耗总量的大头。
国际第三方机构OpenRouter的数据显示,红队大模型的周调用token总量在12.96万亿左右,蓝队只有3.03万亿。
红队在性能仅落后8个月的情况下,应用普及率上已经把蓝队甩在身后。
此外,红队还解决了一个大问题:国产GPU适配。

(国产硬件早晚要跟上来)
DS R1发布时曾掀起一波私有化部署风潮,当时出现一个挺尴尬的情况——性价比最高的大模型推理GPU居然是英伟达的产品。国产GPU由于芯片架构和软件生态原因,性价比远低于英伟达。一套满血版DS R1的推理机,用英伟达方案比国产方案便宜30万左右。
大模型开发厂商当时也想方设法引进英伟达GPU,一方面是单位算力价格问题,另一方面是技术生态问题。英伟达的AI生态成熟,训练和推理都更方便。
如今这个问题基本不存在了。国产大模型厂商在经历多轮严格限制后,已不再考虑从外部引进GPU。国产GPU厂商也在针对大模型训练和推理特点做软硬件优化,技术难题被一道道打通。花样繁多的限制条件,反倒倒逼红队的整个AI生态快速成熟。
说到底,红队的上限依旧紧随蓝队。在蓝队反复施加限制的情况下,差距被拉开了一点,但远没到令人担忧的程度。而在大模型应用普及这条赛道上,蓝队差得还远。
成本的鸿沟比性能的差距更难追。美国人嘴上不说,心里清楚这才是真正让他们坐立不安的地方。

(机器人马拉松,意义非常大)
这种成本优势背后,是整个产业链的系统性差异。美国在AI基础设施上的投入规模惊人,微软、谷歌、亚马逊三大云巨头每年在数据中心建设上的资本开支加起来超过千亿美元。这些投入需要摊薄到每一次API调用中,结果就是用户使用成本居高不下。
中国的云厂商虽然体量小一些,但建数据中心的方式更“接地气”。地方政府提供土地和电力配套,芯片厂商针对性优化,模型厂商深度参与硬件适配,整条链条的协作效率更高。没有那么多中间环节抽成,成本自然压得更低。
更关键的是,中国AI应用场景的丰富程度全球罕见。从电商客服到短视频推荐,从外卖调度到网约车派单,从在线教育到医疗影像,每个场景背后都是海量数据和调用需求。这种“场景红利”是美国同行羡慕不来的。
OpenAI的Sam Altman曾经宣称,未来 whoever builds the best AI will rule the world。可现实是,谁能把AI用得最广、用得起,谁才真正掌握主动权。从这个角度看,8个月的性能差距,远没有4倍的成本差距那么致命。