标签: 华为云




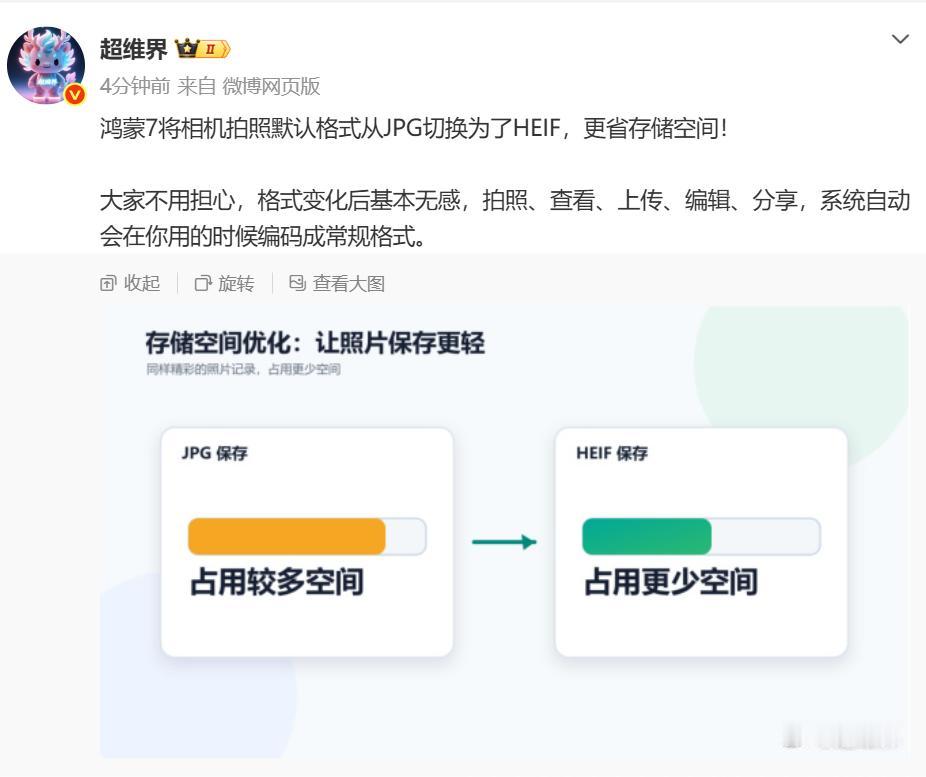















华为云全自研工业级AI开发专区上线:打破CUDA垄断,国产份额首破40%当英伟达
华为云全自研工业级AI开发专区上线:打破CUDA垄断,国产份额首破40%当英伟达CUDA框架长期主导全球AI开发工具链时,中国市场的结构性变化正在加速。2026年6月5日,华为云在上海发布新一代模型训推平台ModelArtsNext,并推出全自研工业级AI开发专区,首次实现了从芯片到应用模型的完整国产化技术栈。这背后是2025年国产AI芯片市场份额首次稳定突破40%的拐点,以及华为昇腾芯片性能对标国际巨头的实质性进展。
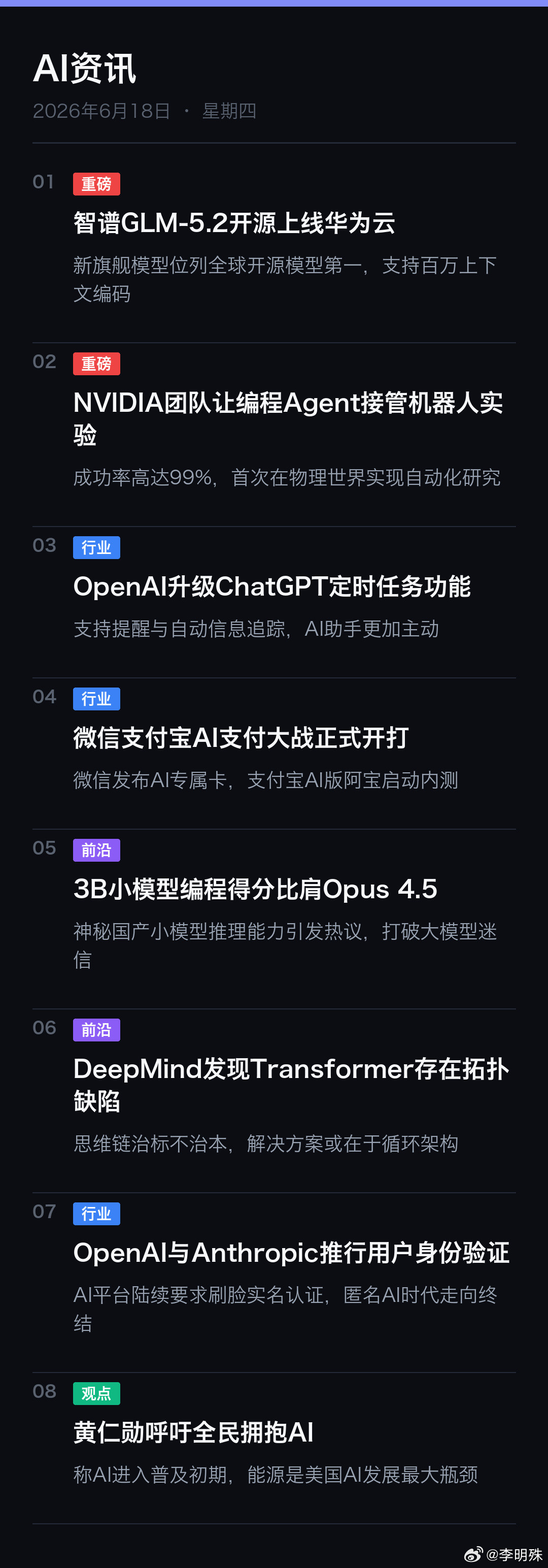
2026年被称为AI元年,这说法很有前瞻性。AI产业链可分上中下游。个股全梳理!
2026年被称为AI元年,这说法很有前瞻性。AI产业链可分上中下游。个股全梳理!上游是基础层,像英伟达、英特尔等芯片巨头是关键,它们为AI提供算力支持,英伟达的GPU在深度学习领域那是相当牛。中游是技术层,百度、谷歌等企业在算法和模型上发力,百度的文心一言就是其成果。下游是应用层,涵盖医疗、金融、交通等多领域。医疗里,AI辅助诊断能提高效率;交通上,自动驾驶正不断发展。AI元年到来,各环节企业都将迎来新机遇与挑战,未来值得期待。



华为发布全球首个城市超级智能体
华为发布全球首个城市超级智能体



中美之间的算力差距到底有多大?根据公开的行业统计,中国总算力规模稳居全球第二
中美之间的算力差距到底有多大?根据公开的行业统计,中国总算力规模稳居全球第二,占全球市场两到三成,和美国咬得很紧。但只要你把目光锁定在人工智能训练最烧钱的那种尖端算力,也就是用英伟达顶级显卡堆起来的智算集群上,差距立马就显现出来了。差距的源头非常简单,就是芯片。目前全球能大规模支撑前沿大模型训练的加速卡,几乎被英伟达一家给包圆了。从A100到H100,再到后来的H200、B200,这些卡不但性能吊打其他同类产品,还因为有一个叫CUDA的软件生态,让全球的人工智能开发者都主动或被动的绑在了英伟达的战车上。这些芯片的核心制造工艺仰仗台积电,设计工具用到美国技术,所以美国一纸出口管制,直接切断了高端GPU流入中国大陆的渠道。这个过程很多人都有印象,2022年先禁了A100和H100,英伟达就搞出A800和H800来绕开限制,主要阉割了卡与卡之间的高速互联带宽,H800的NVLink带宽被砍到了A100时代的水平,让大规模并行训练的效率打了折扣。结果到2023年10月,老美再次加码,连这些特供版也一并禁了。此后英伟达为了不丢掉中国市场这块肥肉,又鼓捣出了完全合规的H20、L20等芯片。H20的纸面算力只有H100的百分之十五左右,显存倒是给到了96GB,但总体上说,它更适合做大模型推理,不太适合从头预训练一个万亿参数级的巨型模型。你看这个管制一步步加码,就让国内公司能获得的顶级训练算力极度受限。没办法,国内大厂和初创企业只能走两条路,一是继续用之前囤下的高端存货精打细算,二是加速切换到国产芯片。华为的昇腾系列自然被推到最前线。昇腾910B自2023年下半年起逐步放量,它的半精度浮点算力与A100大致相当,随后在2024年推出的昇腾910C更进一步,性能与H100的单卡差距进一步缩小。华为云和合作伙伴基于数千张昇腾卡构建集群,成功支持了科大讯飞星火大模型、鹏城实验室的系列模型训练,官方披露的训练效率能接近A100方案的九成。可问题不在单卡性能,而在软件生态。全世界的深度学习框架和模型代码几乎都是围绕CUDA写的,突然要迁移到华为的昇思MindSpore框架或适配CANN算子库,相当于把房子换个地基,大量的底层代码需要重写,算子需要重新调试,显存管理逻辑也要改。开发者社区里普遍反映,迁移成本不低,训练过程中遇到的一些隐性bug,花的时间比预期多不少。这就意味着,即使国产卡的硬件算力上来了,由于软件适配和生态的成熟度差距,实际产出效率还是得打一个折扣,算下来有效算力进一步被拉低。不过事情也不是一边倒。国内有一个美国没有的优势,那就是庞大的内需市场和应用场景。中国的移动互联网、智能制造、自动驾驶、智慧城市,这些领域对算力的消耗巨大,其中绝大部分需求属于推理计算。而推理计算对芯片的要求比训练低不少,H20、L20这类特供芯片以及国产的寒武纪、海光、昇腾推理卡完全能够胜任,甚至因为显存大,部分场景比英伟达的高端卡还划算。所以你会发现,虽然训练前沿模型我们吃点亏,但在真正落地的应用端,中国人工智能服务的覆盖面和使用体验一点不差,甚至因为场景磨砺,在推荐算法、图像识别、语音交互上比美国还强。此外,过去两年国家主导的“东数西算”工程已经把算力当成像水电气一样的基础设施来建设。多个西部省份建起了超大型数据中心,里面开始成规模地部署国产智能计算芯片。2025年,一些城市的智算中心算力规模已经达到数千PFLOPS,能够同时支撑几百家企业的训练和推理任务。这种举国体制的力量,让算力的底座在慢慢夯实。与此同时,国内的服务器制造和液冷散热产业链已经做到全球领先,美国搭建十万卡集群,也得从中国采购大量的光模块和制冷设备。双方在产业链上是相互缠绕的,谁也没法完全甩开谁。所以回到最初的问题,中美之间的算力差距到底有多大。简单说,在最尖端的、支撑下一代通用人工智能训练的那部分算力上,差距是明显的,存在一个数量级的落后,核心卡点就在于能拿到什么级别的芯片以及有多少张。但在通用算力、超算和推理算力这些更宽泛的层面,差距要小得多,甚至互有胜负。这种结构性的差距意味着短期内没法在模型参数量的军备竞赛上直接硬拼,但可以凭借算法优化、数据质量提升和应用创新来打差异化。而且随着国内半导体产业链一点点补课,这种差距的绝对值正在逐步缩小,只不过还需要时间和耐心。

一张图真能看懂AI产业链!AI产业链超庞大,横跨硬件、框架、算法、应用。底层硬件
一张图真能看懂AI产业链!AI产业链超庞大,横跨硬件、框架、算法、应用。底层硬件是根基,AI芯片方面,寒武纪等国产厂商和英伟达等国际巨头竞争,提供核心算力;浪潮等服务器厂商组装高性能集群;海康威视等布局感知硬件。基础软件与框架是“大脑中枢”,像TensorFlow、飞桨等是开发者构建模型的工具。AI应用产业链分上、中、下游。上游提供算力和数据服务,中游开发解决方案,下游面向多领域。在技术和市场推动下,AI前景广阔,未来会创造更大价值。
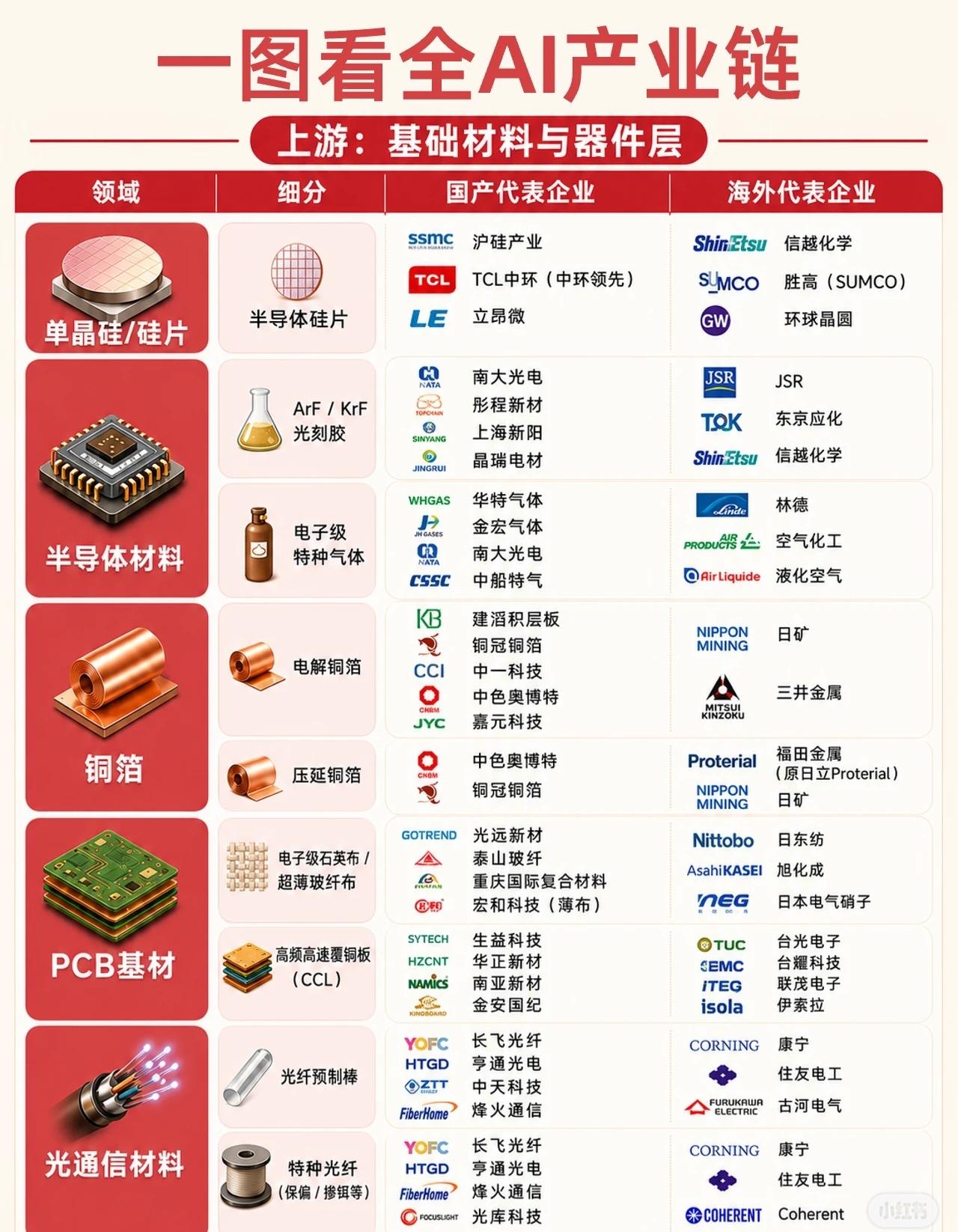
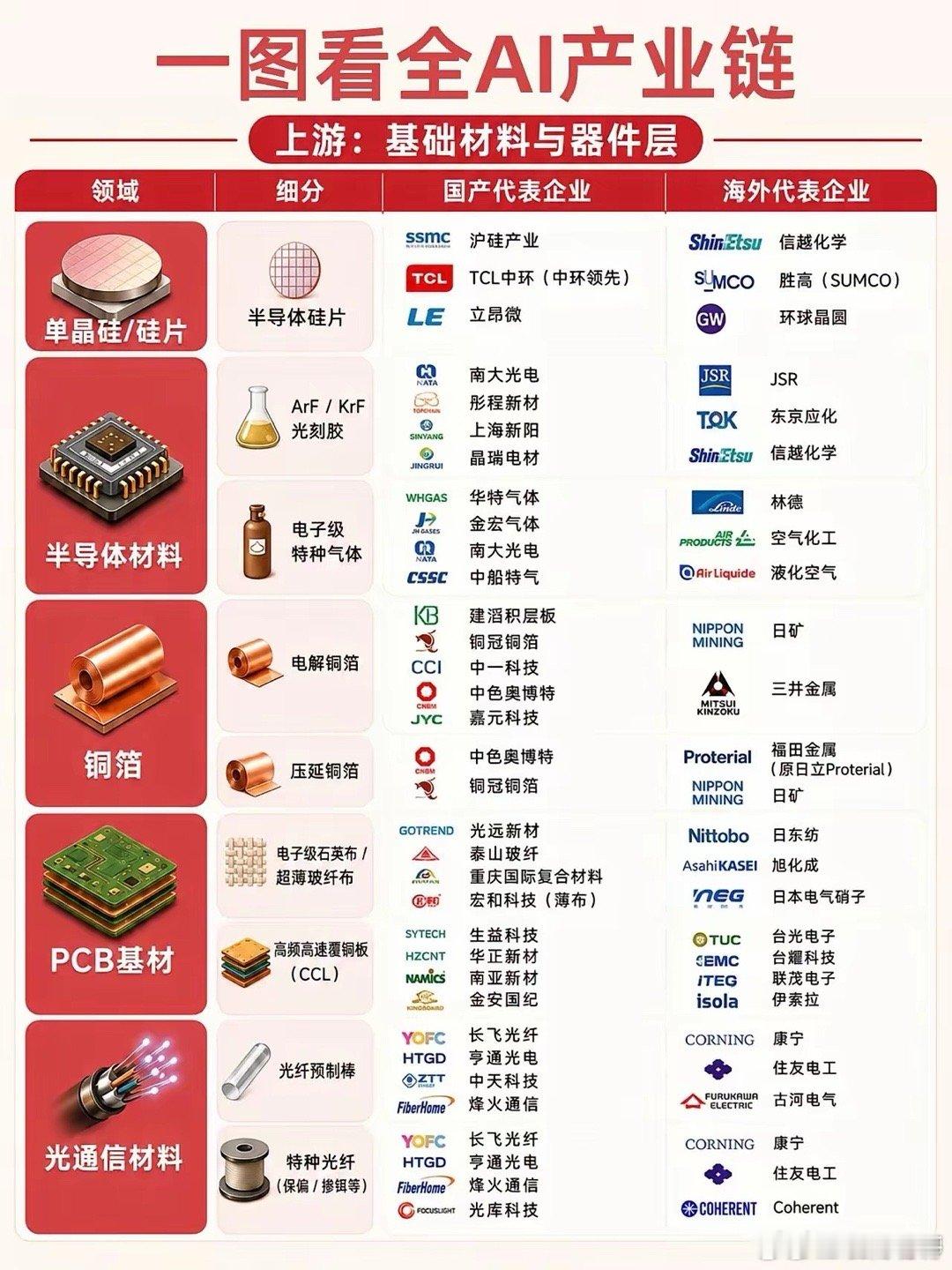
人工智能产业链可清晰地划分为上游基础材料与器件、中游核心硬件、下游系统集成与应用
人工智能产业链可清晰地划分为上游基础材料与器件、中游核心硬件、下游系统集成与应用三大层级。以下为您系统梳理各环节的核心构成:一、上游:基础材料与器件层作为AI产业的基石,上游涵盖半导体材料、PCB基材及光通信材料等关键环节。在单晶硅/硅片领域,国产代表企业包括沪硅产业、TCL中环(中环领先)以及立昂微,而海外则由信越化学、胜高(SUMCO)和环球晶圆占据主导。半导体材料细分为光刻胶与电子级特种气体两大方向。光刻胶方面,南大光电、彤程新材、上海新阳和晶瑞电材是国内代表;国际巨头则为JSR、东京应化及信越化学。电子级特种气体领域,华特气体、金宏气体、南大光电和中船特气构成了国内主力,海外供应端由林德、空气化工和液化空气把控。铜箔环节包括电解铜箔与压延铜箔,建滔积层板、铜冠铜箔、中一科技、中色奥博特、嘉元科技及中色奥博特(压延)是国内代表,海外对应企业为日矿、三井金属及Proterial(原日立Proterial)。PCB基材领域,电子级石英布/超薄玻纤布由光远新材、泰山玻纤、重庆国际复合材料和宏和科技(超薄)主导;高频高速覆铜板(CCL)则主要有生益科技、华正新材、南亚新材和金安国纪。海外方面,日东纺、旭化成、日本电气硝子以及台光电子、台耀科技、联茂电子、伊索拉等企业占据重要地位。光通信材料涵盖光纤预制棒与特种光纤(保偏/掺铒等)。长飞光纤、亨通光电、中天科技、烽火通信和光库科技是国产核心力量,海外则由康宁、住友电工、古河电气及Coherent引领。二、中游:核心硬件层中游是AI产业的算力中枢,聚焦于AI芯片、存储芯片及光互联与光模块。AI芯片包括训练与推理GPU、专用AI加速芯片(ASIC/TPU)及AI服务器CPU。国产GPU代表有寒武纪、海光信息、景嘉微、壁仞科技、沐曦和摩尔线程;专用AI加速芯片以寒武纪、燧原科技、平头哥(阿里)、百度昆仑芯和腾讯紫霄为代表;AI服务器CPU领域则有龙芯中科、兆芯、海光信息和飞腾。海外方面,英伟达、AMD、英特尔、谷歌TPU、亚马逊Trainium及微软Maia构成强大阵营。存储芯片涵盖HBM(高带宽内存)、DDR5高速内存及NANDFlash存储颗粒。值得注意的是,HBM领域国产尚未实现批量出货,而海外由SK海力士、三星和美光主导。DDR5方面,兆易创新、澜起科技(接口芯片)、北京君正和聚辰股份是国产代表,海外为三星、SK海力士和美光。NANDFlash存储颗粒则主要由长江存储(3DNAND)、长鑫存储(DRAM)及兆易创新(NORFlash)支撑,海外对应企业包括三星、铠侠、西部数据、美光和SK海力士。光互联与光模块包括光器件、光模块及网络与互联设备。光器件国产代表为光库科技、腾景科技、天孚通信和博创科技,海外由II-VI(Coherent)和Finisar主导。光模块领域,中际旭创、光迅科技、新易盛、华工科技、天孚通信和剑桥科技表现突出,海外则有Coherent、Marvell、英特尔、Macom、博通等巨头。网络与互联设备方面,华为、中兴通讯、紫光股份(新华三)和锐捷网络是国产主力,海外对应思科、Arista、Juniper等企业。三、下游:系统集成与应用层下游将算力转化为实际价值,覆盖AI服务器、数据中心、液冷散热、云计算、大模型及应用终端。AI服务器与数据中心方面,国产代表包括浪潮信息、工业富联、中科曙光、中兴通讯、紫光股份和华勤技术,海外则由戴尔、HPE、超微(Supermicro)、联想等主导。智算中心与超算中心领域,润泽科技、世纪互联、数据港、光环新网、奥飞数据和万国数据是主要参与者,海外对应Equinix、DigitalRealty和NTT。液冷散热环节,冷板式/浸没式液冷技术由英维克、申菱环境、高澜股份、同飞股份和曙光数创等国产企业推动,海外则有Vertiv、CoolerMaster和nVent。云计算与AI平台包括AI云服务与AI平台/MLOps。AI云服务由阿里云、腾讯云、百度智能云和华为云主导,海外对应AWS、Azure和GoogleCloud。AI平台/MLOps方面,阿里巴巴、百度、腾讯、华为和字节跳动是国产代表,海外则由AWSSageMaker、AzureML和GoogleVertexAI引领。大语言模型领域,国产代表有通义千问(Qwen)、字节跳动(豆包)、百度(文心)、腾讯(混元),海外则以OpenAI(GPT系列)、谷歌(Gemini)、Anthropic(Claude)和Meta(LLaMA)为代表。







华为最年轻天才少年集体出走,不是另攀高枝,而是奔着中国最硬的一块骨头去了。5
华为最年轻天才少年集体出走,不是另攀高枝,而是奔着中国最硬的一块骨头去了。5月10日,创投圈私下流传的一份名单,让很多人看直了眼。赵立晨,19级技术专家,被高管在内部点名夸过的“算法狂人”,周顺波,华为具身智能“1号员工”,手里攥着国际顶级论文和核心专利,朱森华,前华为云AI创新Lab主任,曾经面试无数天才少年的“伯乐”。他们有一个共同的身份:华为“天才少年”计划走出来的顶尖人才,现在,他们都在同一时间做了同一件事,离开华为,扎进国产机器人和先进制造赛道。这事儿乍一听挺让人纳闷,华为啊,多少技术人梦寐以求的殿堂,给的待遇和平台都是顶级的,怎么如今这些“宝贝疙瘩”一个个都往外跑?而且跑的方向出奇一致,全都扑向了“具身智能”这个领域。具身智能是啥?简单说,就是让机器拥有像人一样的身体和智能,能感知、能思考、能动手,是人工智能皇冠上最难摘的那颗明珠,也是全球科技巨头都在拼命争夺的下一座圣杯。这可不是什么赚快钱的互联网风口,这是一条需要砸重金、耗时间、拼硬核技术的“长征路”,是中国科技领域公认“最硬的一块骨头”。那么他们为什么走?又为什么偏偏都选这块骨头啃?先看赵立晨,这位北航软件工程出身的“算法狂人”,是华为天才少年里极少见的校招硕士,一进公司就从零拉起一支20多人的团队,主导的AI项目拿过中国电信卓越创新奖,眼看就要大规模量产了。可他在2026年3月转身就加入了杭州某技术公司,干的事更“硬核”——专攻“具身智能架构”,也就是给未来的机器人打造最底层的“操作系统”。他瞄准的是整个产业的基石,是决定机器人到底有多“聪明”的核心命脉。再看周顺波,这位被圈内人称为华为具身智能“1号员工”的大神。他在华为五年,从零到一搭建了公司第一个也是最大的具身智能团队,一手制定了华为云在这个领域的整个技术体系。可以说,华为在具身智能领域的家底,有一大半是他打下的。结果今年3月初,他也离职了,创办了“欧拉万象”。他在朋友圈里写的话很有意思:“机器人赛道长坡厚雪,离职不是结束,而是换一种方式守望相助。”“长坡厚雪”这个词,出自巴菲特,意思是又长又湿的雪道,可以滚出巨大的雪球。周顺波看中的,正是机器人这个需要长期积累、但未来想象空间无限的超级赛道。他离开,不是对华为失望,而是觉得在创业公司这条更陡峭的雪道上,能更快地滚出那个属于中国机器人的大雪球。最后是朱森华,这位脑神经科学博士后出身的“伯乐”,在华为面试过无数天才少年,自己更是华为云AI算法创新Lab的主任,智能机器人业务的开创者。2023年华为开发者大会上那个能跟真人交互的“具身工匠”原型,背后就是他主导的华为首代具身大模型。他在2025年10月离职,创立了“具脑磐石”。他的路线更“科幻”,他想用研究人脑认知的方式,去“改造”机器人的大脑,让机器人告别那种靠海量数据“暴力计算”的笨办法,真正像人一样学会思考和决策。这简直是给机器人“注入灵魂”的工程。三个人,三个方向,但目标惊人一致:攻克具身智能。他们离开华为的时间点也集中在2025年底到2026年初,这绝不是巧合。背后是时代的浪潮在推着人走。一方面,经过几年高歌猛进,AI大模型在软件层面的竞争格局初步形成,下一个必然的战场就是“软硬结合”,让AI从虚拟世界走进物理世界,去操控实体机器人,去改造千行百业。这是全球共识,也是国家战略。另一方面,华为作为中国科技的“黄埔军校”,已经完成了在通信、手机、云计算等领域的顶级人才培养和输出。当这些顶尖人才在内部积累了足够的技术视野和产业认知后,向外溢出,去更前沿、更垂直的领域开疆拓土,是一种必然。任正非老爷子自己就说过,华为不能垄断人才,员工想出去创业,人尽其才,对国家也有用。这是一种格局,更是一种自信。这些天才少年,在华为这座大熔炉里淬炼成了最锋利的剑,如今,他们不约而同地选择了科技自立自强道路上最难啃的硬骨头——国产机器人和先进制造。他们不是去追逐短期的资本泡沫,而是去夯实中国智能制造的底层地基。赵立晨攻架构,周顺波做产品,朱森华研大脑,他们正在从不同的维度,合力撬动中国机器人产业的未来。是啊,他们奔着中国最硬的一块骨头去了,但这块骨头再硬,也硬不过这批中国最聪明大脑的决心。他们的集体转身,像一面镜子,照出了中国硬科技创业正在从“模式创新”深水区,挺进“原始创新”无人区的历史性转折。华为培养了他们,而他们,正在成为播种机,把最顶尖的技术火种,撒向中国制造最需要突破的腹地。这场由天才少年们掀起的具身智能创业浪潮,或许刚刚开始,但它指向的,是中国从制造大国迈向智造强国的星辰大海。骨头虽硬,啃下来,就是通途。参考:华为“天才少年”今何在?——读创






