[CL]《Repurposing Synthetic Data for Fine-grained Search Agent Supervision》Y Zhao, K Li, X Wu, L Zhang... [Alibaba Group] (2025)
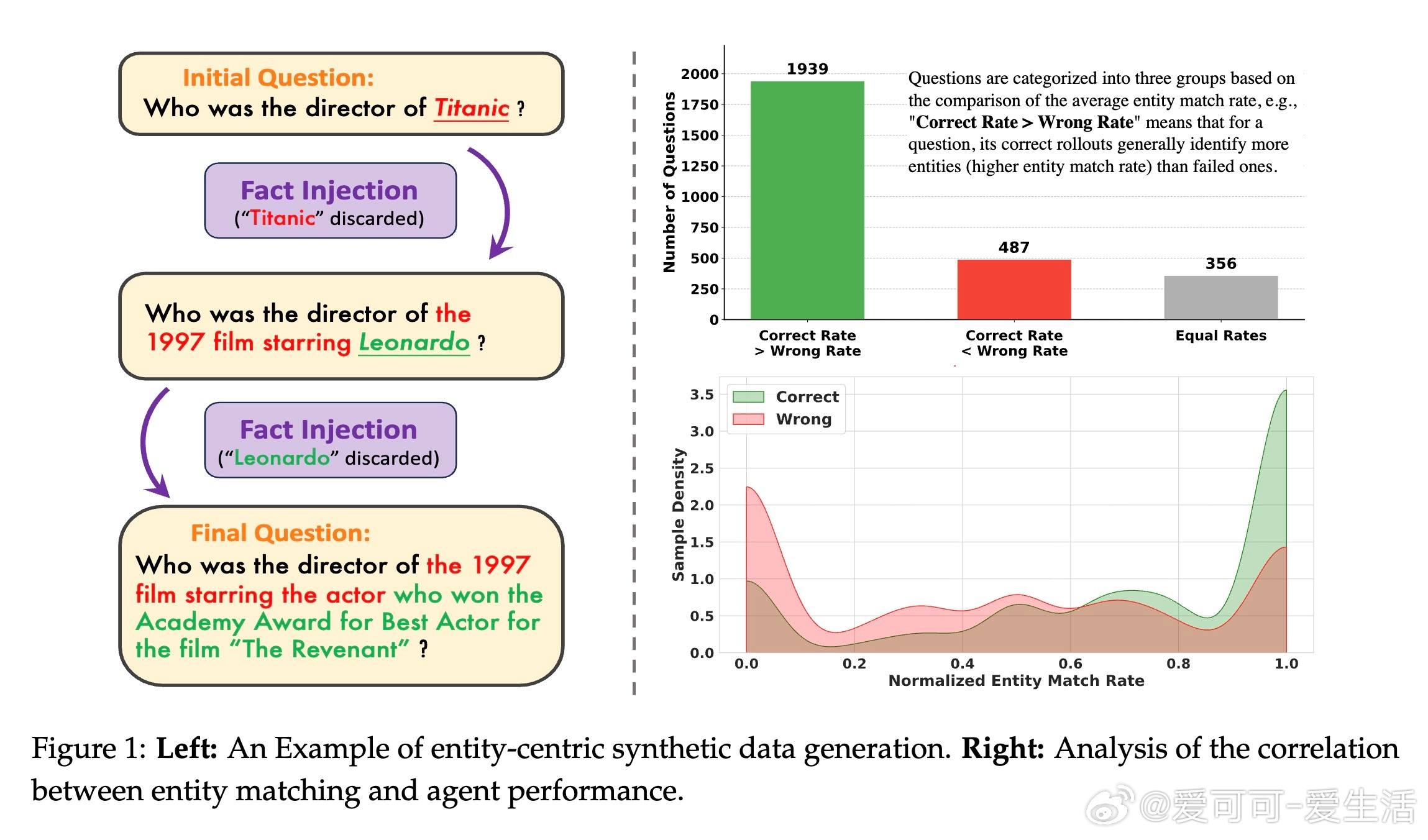
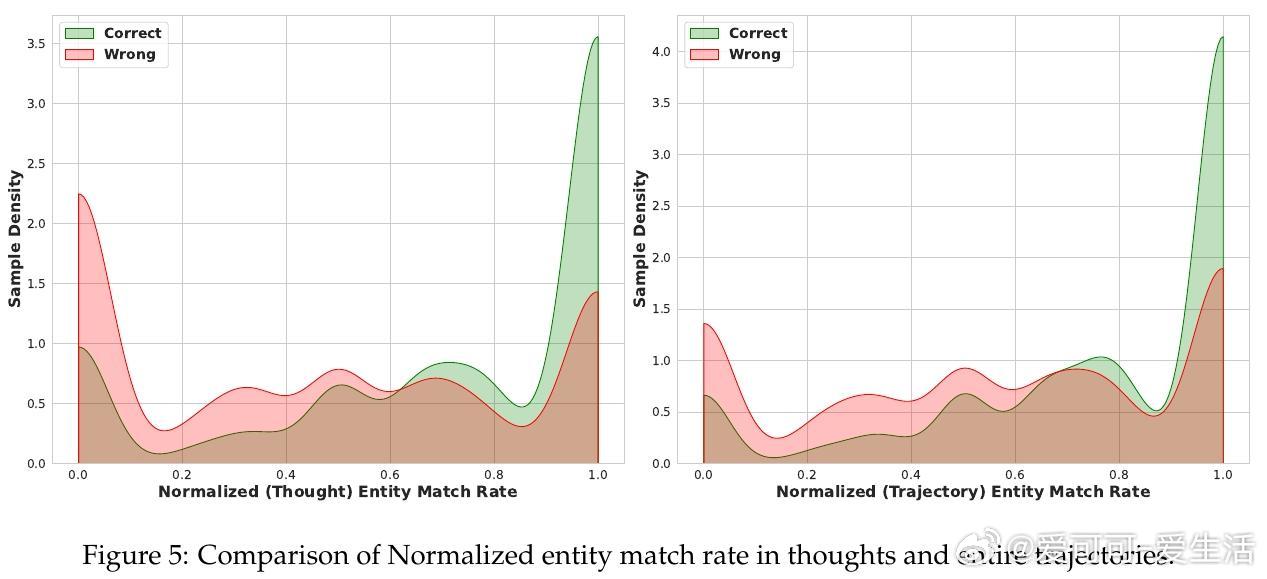
在当今基于大语言模型(LLM)的搜索代理训练中,合成数据因其实体中心的特性被广泛采用以解决复杂知识密集型任务。然而,主流训练方法如Group Relative Policy Optimization(GRPO)只利用了最终答案的稀疏奖励,忽视了合成数据中丰富的实体信息,导致无法区分“近乎正确”的推理过程与完全失败的样本,浪费了宝贵的学习信号。
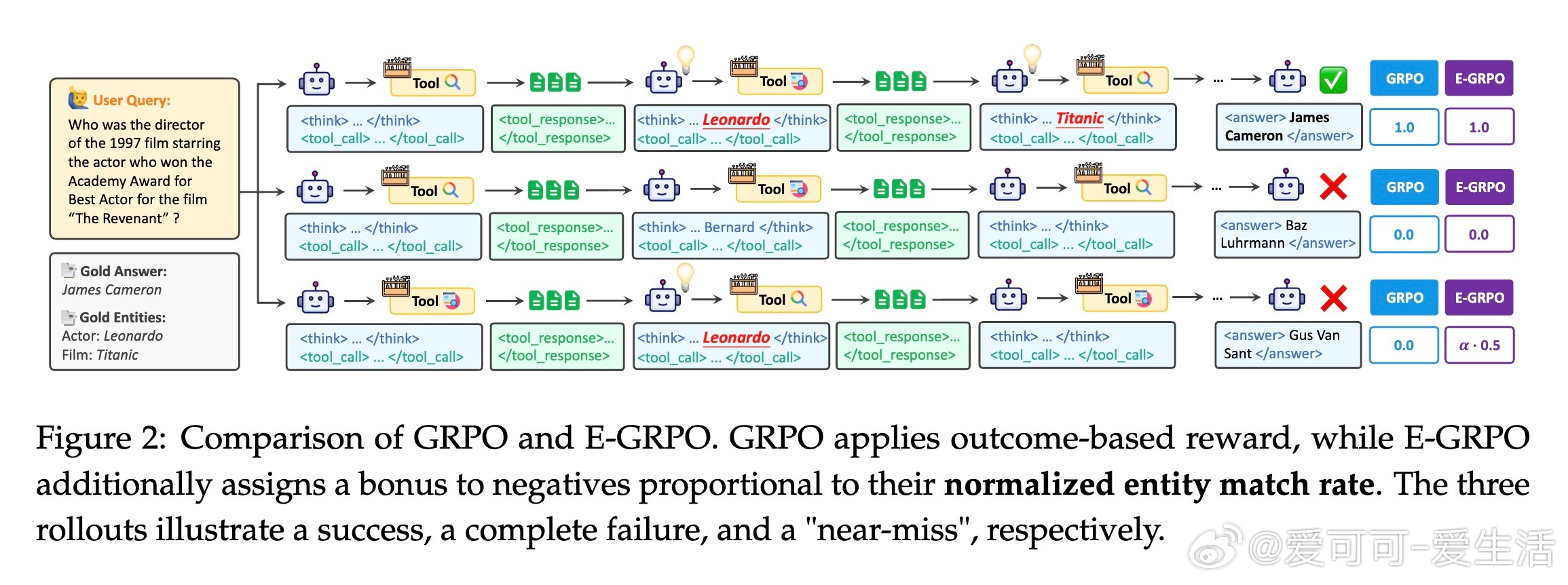
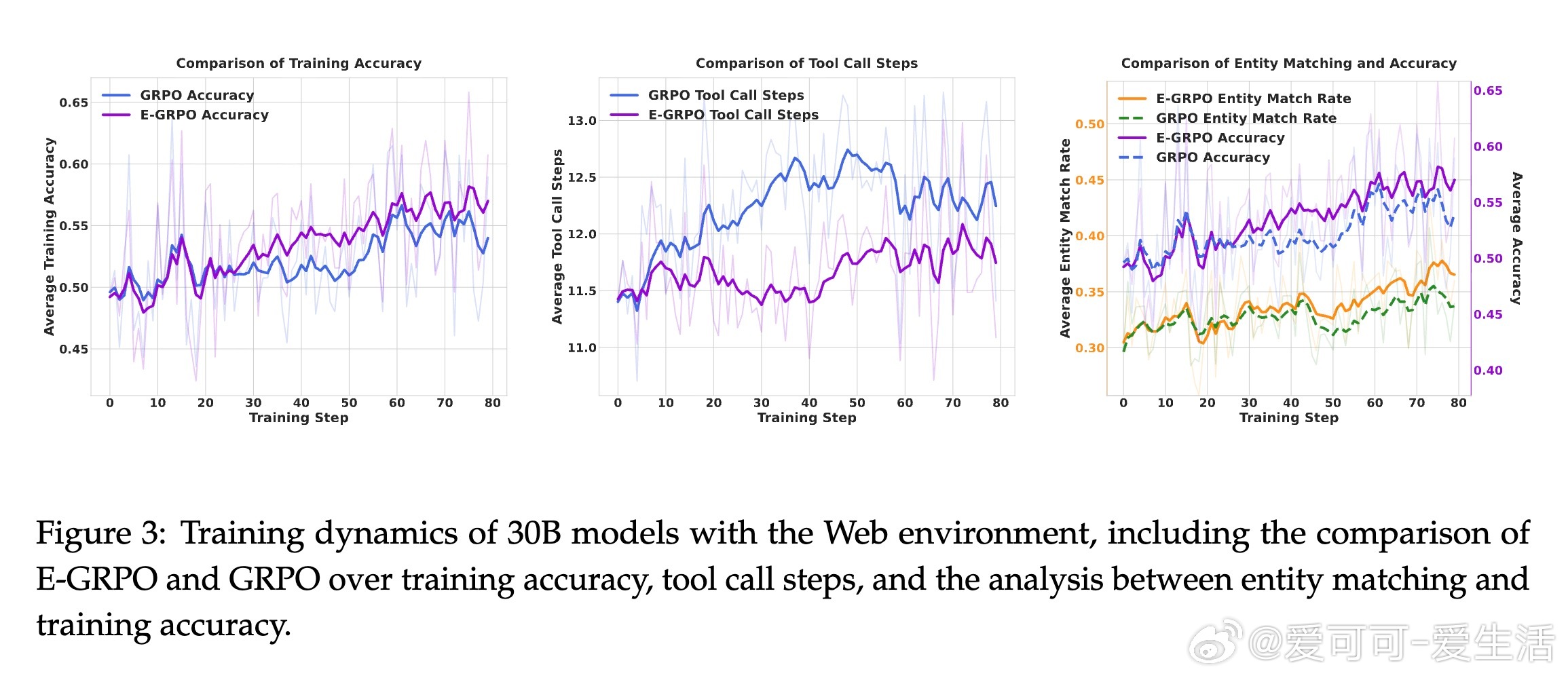
本文提出了Entity-aware Group Relative Policy Optimization(E-GRPO)框架,通过引入基于实体匹配率的稠密奖励函数,赋予部分错误样本与其实体匹配程度成正比的奖励,从而有效利用“近乎正确”的样本促进模型学习。实验证明,E-GRPO在多个问答及深度研究基准上显著优于传统GRPO,不仅提升了准确率,还促使模型学会更高效的推理策略,减少了工具调用次数,提升了训练样本的利用效率。
核心创新点包括:
1. 发现并量化了实体匹配率与答案准确率的强正相关性,将被废弃的合成数据实体重新用于细粒度监督。
2. 设计实体感知的奖励函数,为错误样本分配基于实体匹配的部分奖励,有效区分“近乎正确”与彻底失败样本。
3. 通过多环境、多模型、多任务的实验验证,展示了E-GRPO的稳健性和优越性能。
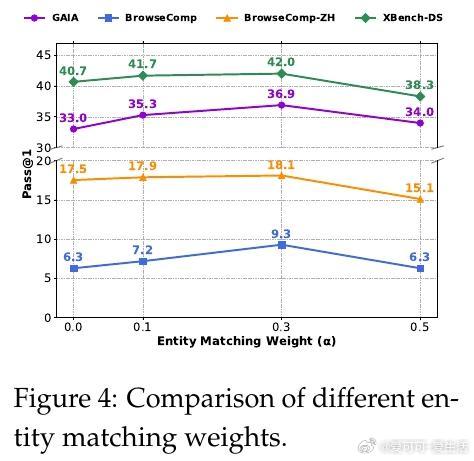
此外,论文深入分析了搜索代理的多轮推理过程及工具调用设计,阐述了实体匹配的严格字符串匹配策略及仅在“思考”阶段匹配实体以避免虚假奖励的合理性。还进行了权重调节的消融实验,确定了平衡准确率与实体匹配奖励的最优参数。
总结来看,E-GRPO通过充分挖掘合成数据中的实体信息,实现了对搜索代理训练的细粒度监督,大幅缓解了传统方法中稀疏奖励带来的学习瓶颈。该方法不仅提升了模型性能,更促进了推理效率的提升,为复杂知识型任务中的智能搜索代理训练提供了更有效、经济的解决方案。
原文链接:arxiv.org/abs/2510.24694