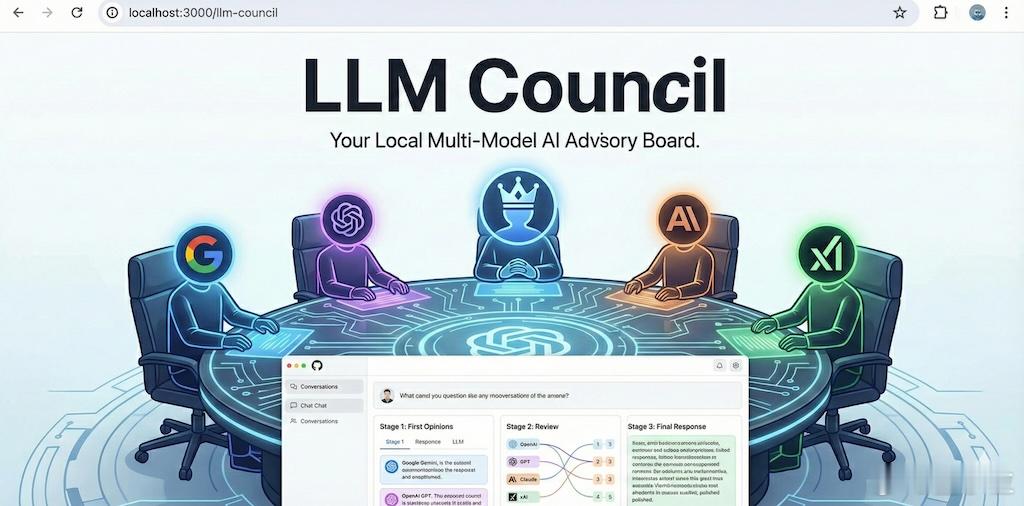
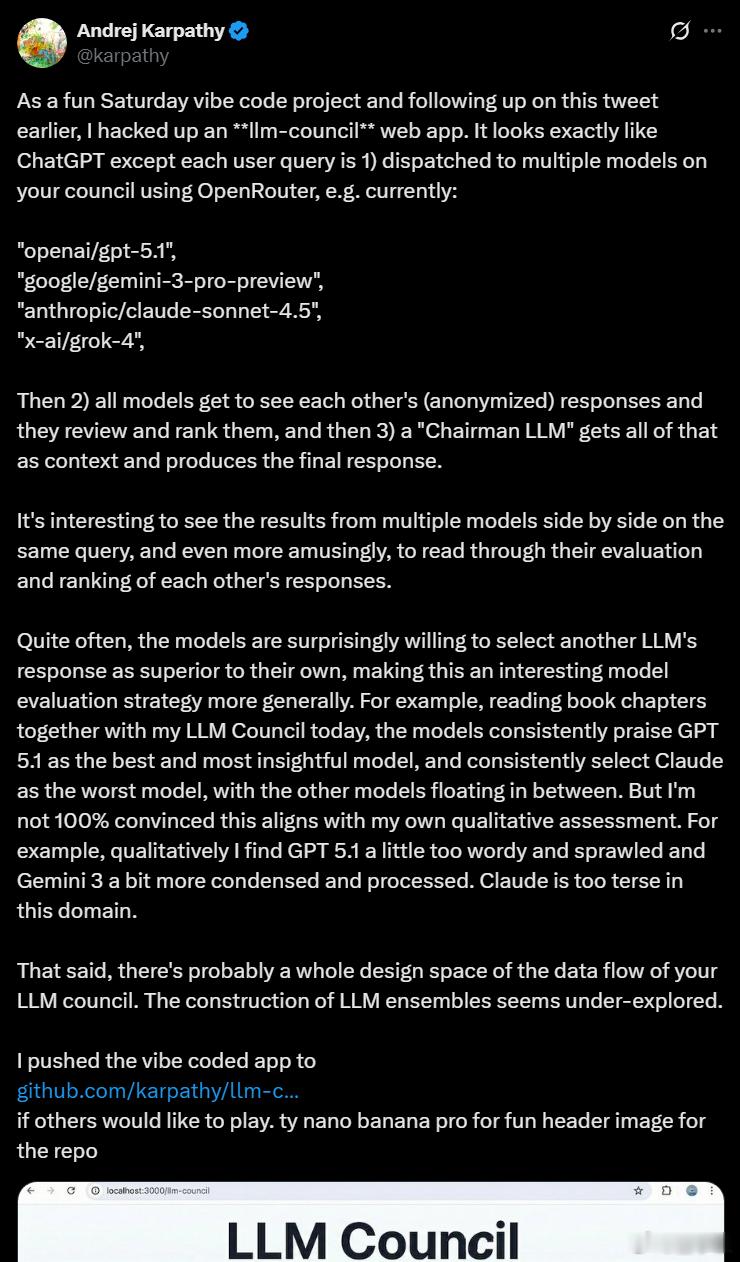
AI大神卡帕西又整活了,这次把大模型拉进了“议会系统”互相开会评判彼此——他新做了一个llm-council项目,是一个开源web应用,底层是多个模型串联合作的“多模态委员会”机制:- 用户提问后,问题会被同步发送给多个大模型,比如GPT-5.1、Gemini 3 Pro、Claude Sonnet 4.5和Grok-4;- 每个模型单独答一遍,再看到其他模型的回答进行匿名互评、打分、写点评;- 最后由“主席模型”整合大家的答案和评价,生成最终答复。最有趣的部分就是模型彼此互评时居然挺“诚实”,它们很乐意承认别的模型写得比自己好,甚至不乏批评自己答得不如人意的情况。卡帕西还拿这个“议会”一起读书做实验,观察哪家模型更擅长分析文本,结果显示GPT-5.1经常被大家评为最佳,而Claude总是垫底,但他个人认为Gemini 3其实更凝练,GPT-5.1太啰嗦了。这个项目探索了一个新方向:多模型“集体智慧”,不再只靠一个大模型闭门造车,而是让它们互相反馈、竞合、择优生成。更大胆的想法是,也许未来的AI系统不是一个模型,而是多个模型组成的团队,每个都有分工,互相投票、互相审校。项目目前已开源,感兴趣的朋友可以从这里玩起来:github.com/karpathy/llm-council