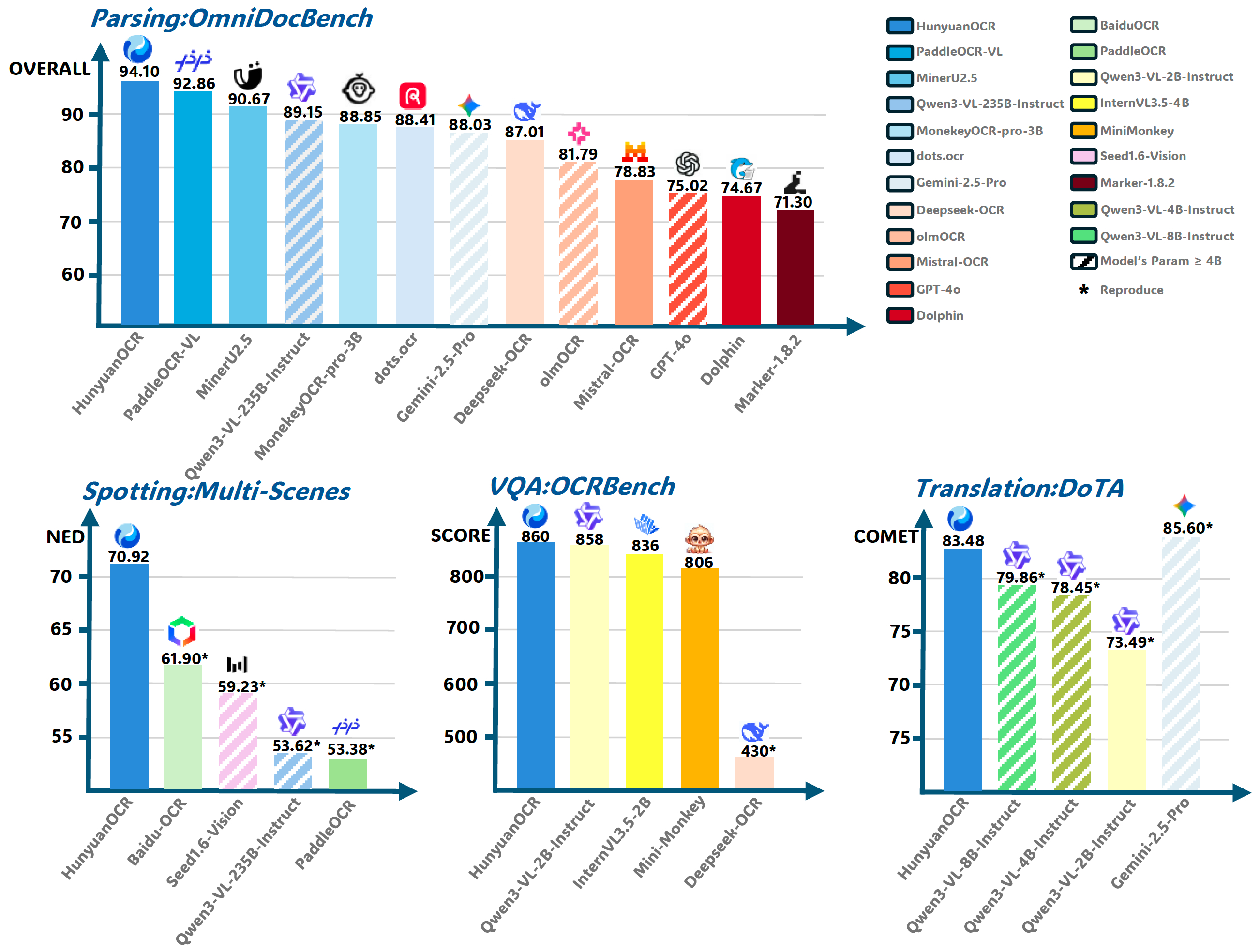
又来了个OCR模型:混元OCR发布并开源github.com/Tencent-Hunyuan/HunyuanOCRHunyuanOCR是一款基于腾讯混元原生多模态架构的端到端OCR专家模型。仅以1B轻量化参数,便已斩获多项业界SOTA成绩。该模型精通复杂多语种文档解析,同时在文字检测识别、开放字段信息抽取、视频字幕识别、拍照翻译等全场景实用技能中表现出色。✨ 核心特点 💪 轻量化架构:基于混元原生多模态架构与训练策略,打造仅1B参数的OCR专项模型,大幅降低部署成本。 📑 全场景功能:单一模型覆盖文字检测和识别、复杂文档解析、卡证票据字段抽取、字幕提取等OCR经典任务,更支持端到端拍照翻译与文档问答。 🚀 极致易用:深度贯彻大模型"端到端"理念,单一指令、单次推理直达SOTA结果,较业界级联方案更高效便捷。 🌏 多语种支持:支持超过100种语言,在单语种和混合语言场景下均表现出色。