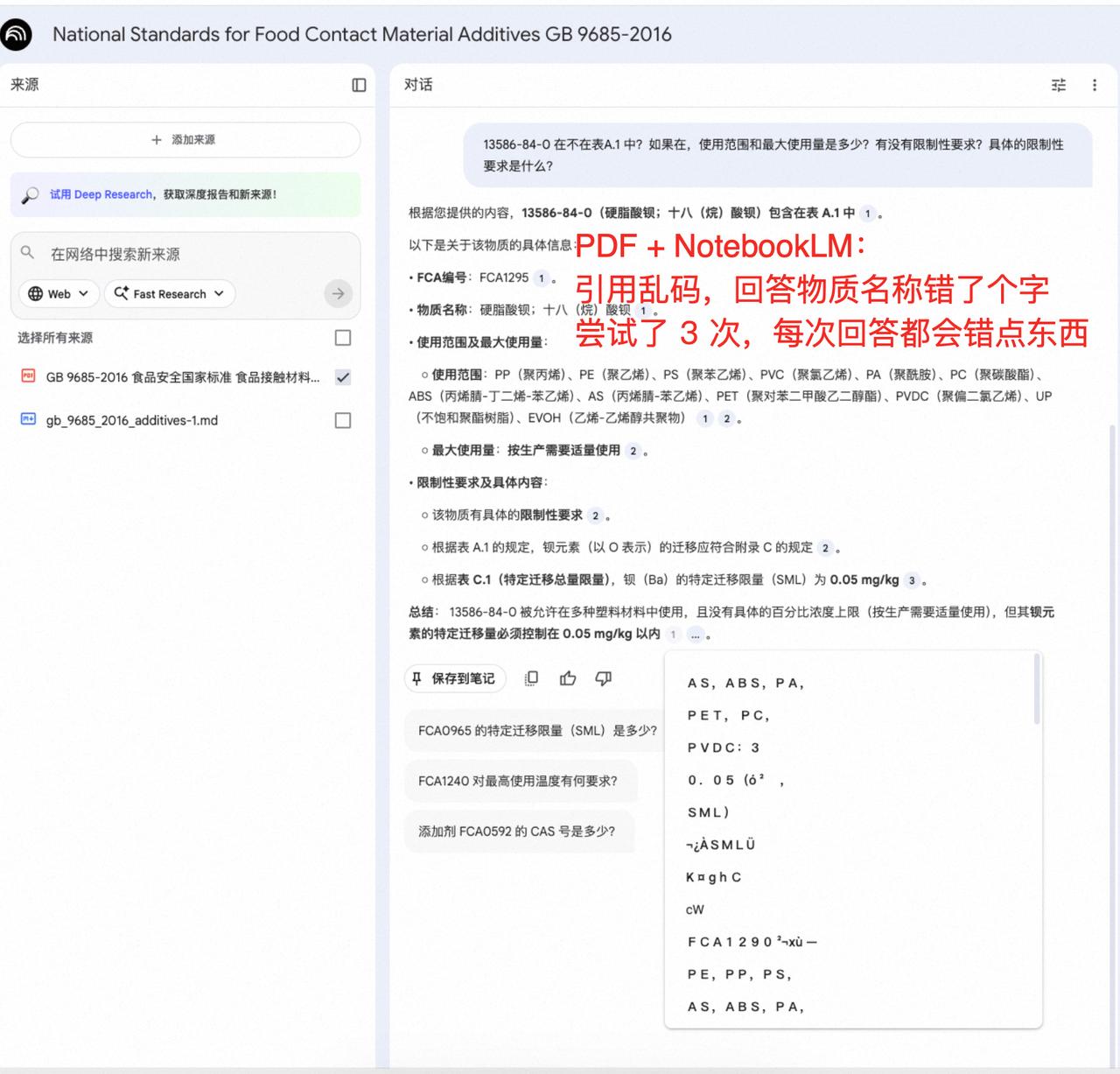
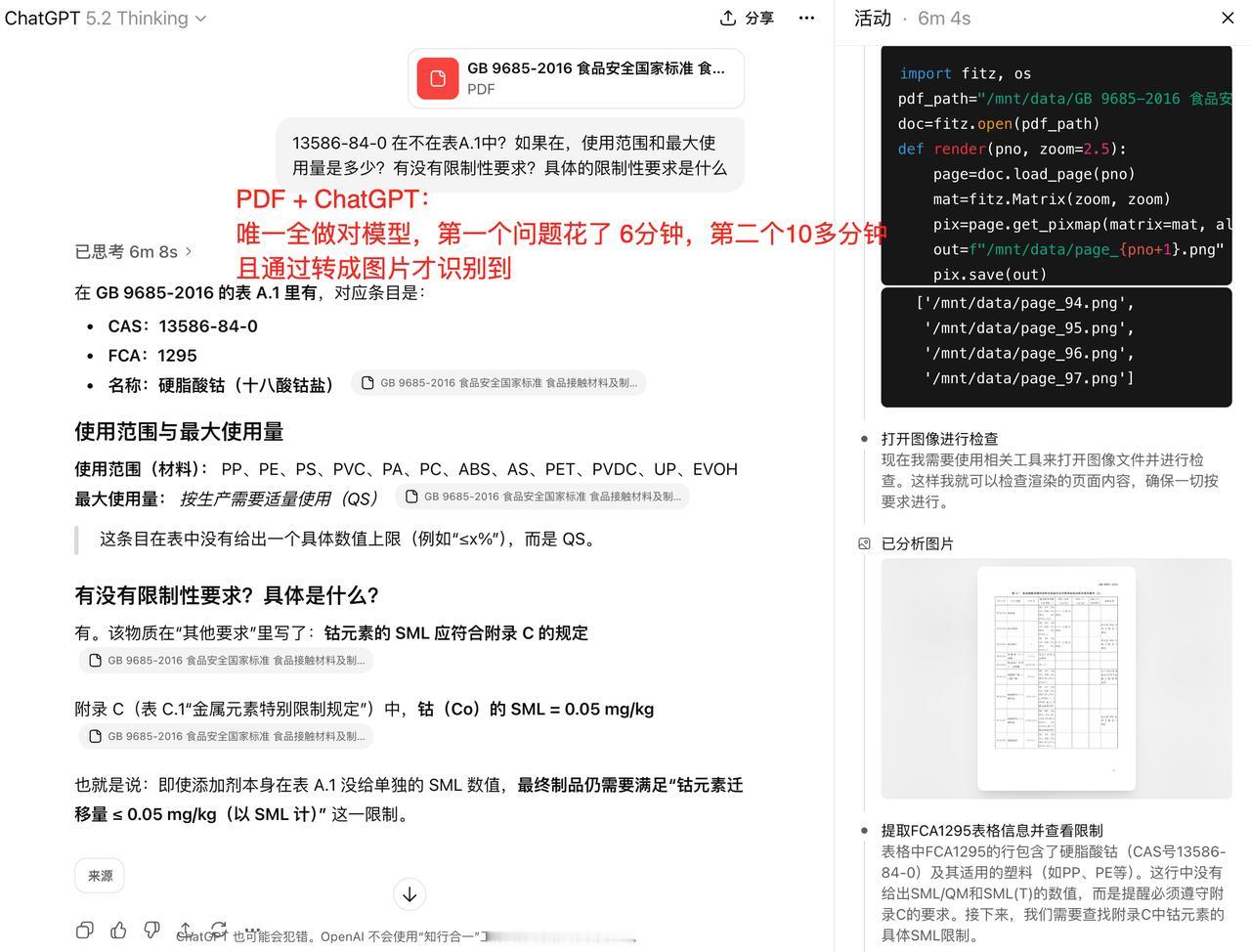
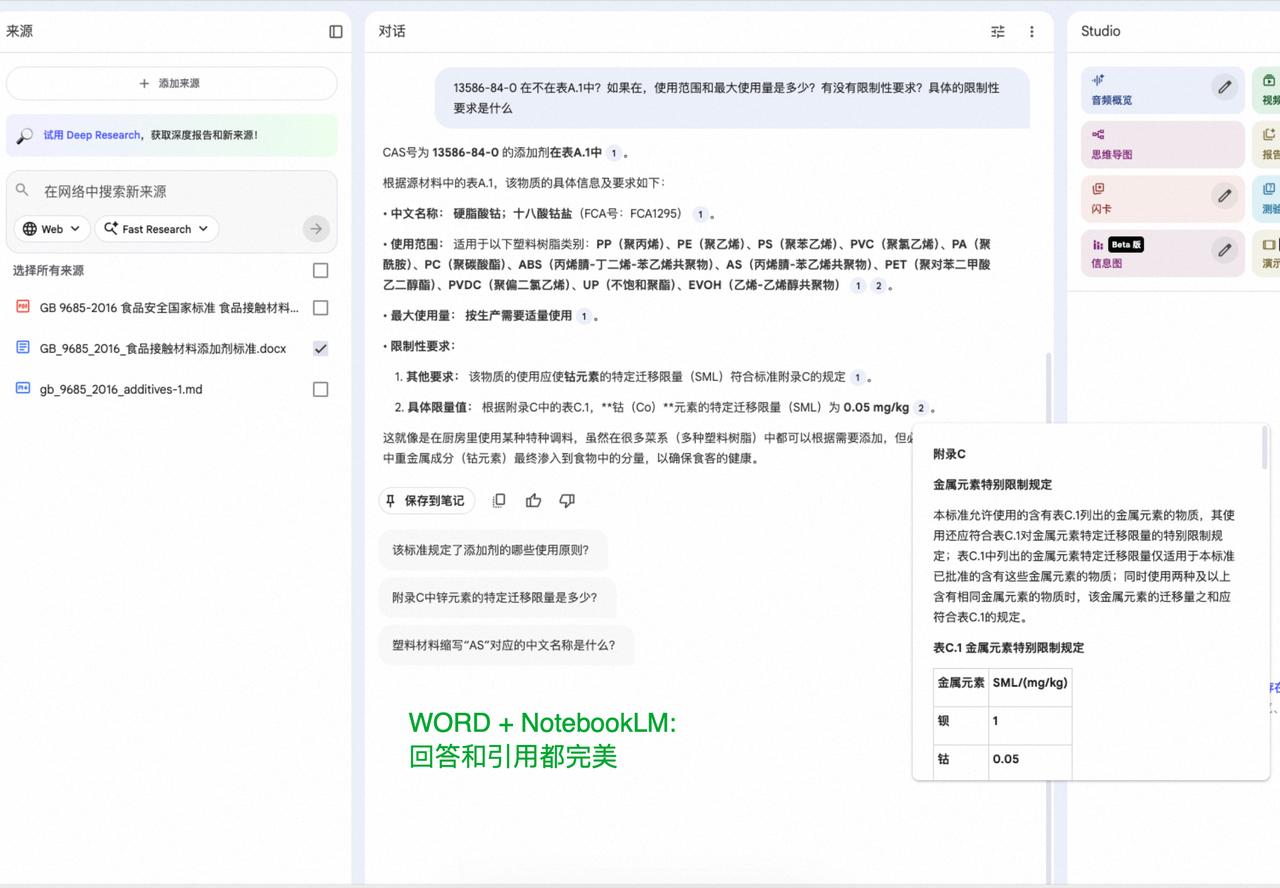
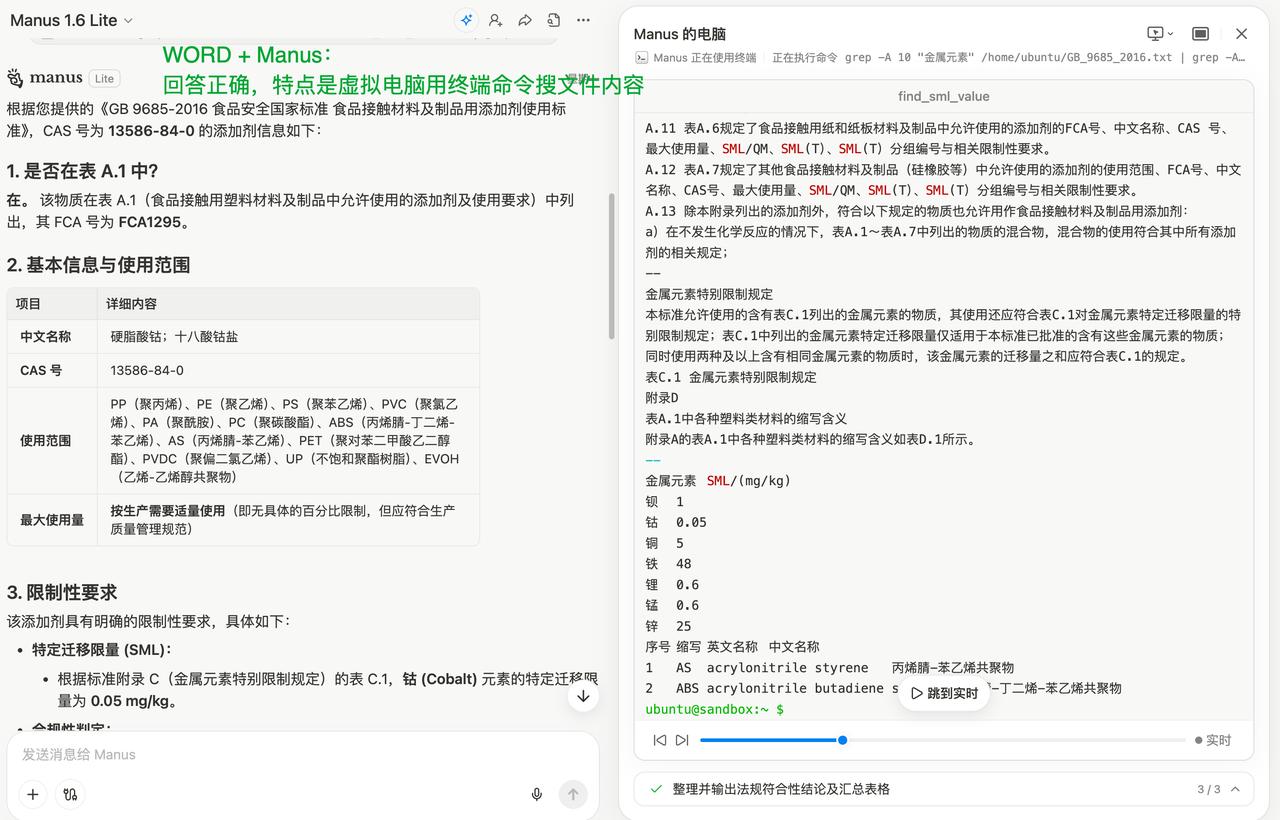
NotebookLM 很多人喜欢它,觉得它准确度高,幻觉少。 我周围用它的人,都是这个评价,在给定文档回答问题这个场景,比如售前,它的超低幻觉,有引用来源好验证,速度快等特点,带来了实实在在的价值。 就是客户来一个问题,你把问题转手给 NotebookLM,然后把回答发给客户就可以了! 我很好奇,它是怎么做到的,只有它才能做到吗?Claude 和 ChatGPT 这些能做到吗?2026 开年,也就是几天前,被 Meta天价收购的 Manus 能做到吗(据传是 50 亿美元)? 它们做到的方式有什么差异吗?还有一个容易被忽视是,你给的原始内容格式,对结果好或坏的影响大吗? 如果对上面这些有了基本结论和认知,对不同的路线,哪些场景通用(算力和代码解决一切),哪些应该垂直(多点工程和人工),会有启发和思考。 带着这些问题,我开始了测试:一份 382 页的中文法规文档,和两个中等复杂的问题(包含多跳问题)。 参赛选手有:NotebookLM、Claude、ChatGPT、Gemini、Manus 和扣子空间。这些产品是我平时有用到的。 第一轮测试,我将法规 PDF 原文上传到这些产品中,敲下问题,回车,等待结果。 结果可以说是惨不忍睹: 1、Claude、Gemini 和扣子空间团灭。 2、NotebookLM 有点玄学,从回答看,它答对了一些但不全对,可见它对原文是有理解的,但给出的引用原文却是乱码。 3、Manus 和 ChatGPT 第一个问题都对,有点惊喜。但付出的成本很大,我等了 5-6 分钟它们才完成,第二个问题,Manus 一顿操作直接耗光了我今天的额度,ChatGPT 花了 10 多分钟做出来了,答案是正确的。 虽然 ChatGPT 做对了,但两个问题花了快 20 分钟,比人自己做慢多了,那实际上也没啥价值。NotebookLM要么识别的物质名称有错字,要么对法规条款引用内容的追踪张冠李戴。 普遍做不出来,问题在哪?发现这些模型,在解析后原文乱码了, 艰难做对的 ChatGPT,展开它的思考过程,它是一边推理探索,一边将可能相关的 PDF 页面转换成了图片,通过识别图片内容,找到回答依据的。 原文乱码原因? 如果换成一个格式良好,不会造成乱码的文档格式,会有完全不同的结果吗? 于是,我将这个 PDF,通过合合,转换成了 Markdown,再转换成 WORD。打算用 WORD 再测一遍同样的问题。 插一句,为啥用 WORD,不用 Markdown?一是 WORD 是更常见的文档格式,二是这个法规文件表格很多,为了保持复杂表格格式,表格用了网页格式。本来 Markdown 是 AI 很喜欢的格式,结果在上传到NotebookLM 时,直接上传失败,或者会被去掉表格。 WORD 版本的测试结果,非常惊艳,直接大反转,我的观察是(排名分先后): 1、Claude & NotebookLM:Claude 通过写代码(结合 SKILL)的方式做,NotebookLM 有规划步骤,有向量(通过引用来源推测),答案非常稳和清晰。 2、Manus:给虚拟电脑,它像个程序员操作电脑,敲终端命令做文件检索,做的也很好。 3、ChatGPT & Gemini:有 Thinking 有步骤和思维链,回答也对。 4、扣子空间:有规划步骤,有虚拟电脑和代码能力,但回答比提问要求总会缺少一点东西,不够理解任务要求(模型层面还有点小差距)。 只是更换了文档类型,就从人工智障跃升为人工智能。所以,如果要做 NotebookLM 那样,有依据的文档问答,将PDF 文档,通过靠谱的方式,先转成 WORD,准确度就会直线拉升。 这些产品,本质上都是通用 Agent, Claude是 SKILL + 代码,Manus 和扣子空间是任务规划 + 虚拟电脑 + 浏览器 + 代码,ChatGPT 和 Gemini 是 Thinking + 代码。路径虽有小差异,但结果大差不差,都是能抓到老鼠的好猫。 原来,不是只有 NotebookLM 能做到,很多产品都能做到,当前最好的模型都能做到,只要你给它代码能力,代码是它们共同的技术线。 到这里,我开始想,RAG 甚至是 GraphRAG,有必要吗?NotebookLM 没有 GraphRAG,但有 RAG。更好的问题也许是,在什么场景下需要它们?如果不是少量文档,而是一个行业的文档集,该如何构建智能问答系统?是不是应该有个文档索引系统,通过这个索引系统,将用户提问快速锁定少量文档,这就变成了本次测试类似的场景了,是不是就解决好了? 有很多问题需要思考和讨论,这是 2026 年我第一个想要搞清楚的,评论区见。