[CL]《Beneath the Surface: Investigating LLMs' Capabilities for Communicating with Subtext》K Ahuja, Y Li, A K Lampinen [Google DeepMind] (2026)
当前LLM在需要精确拿捏"说多少"的任务中,系统性地倾向于说得太多。
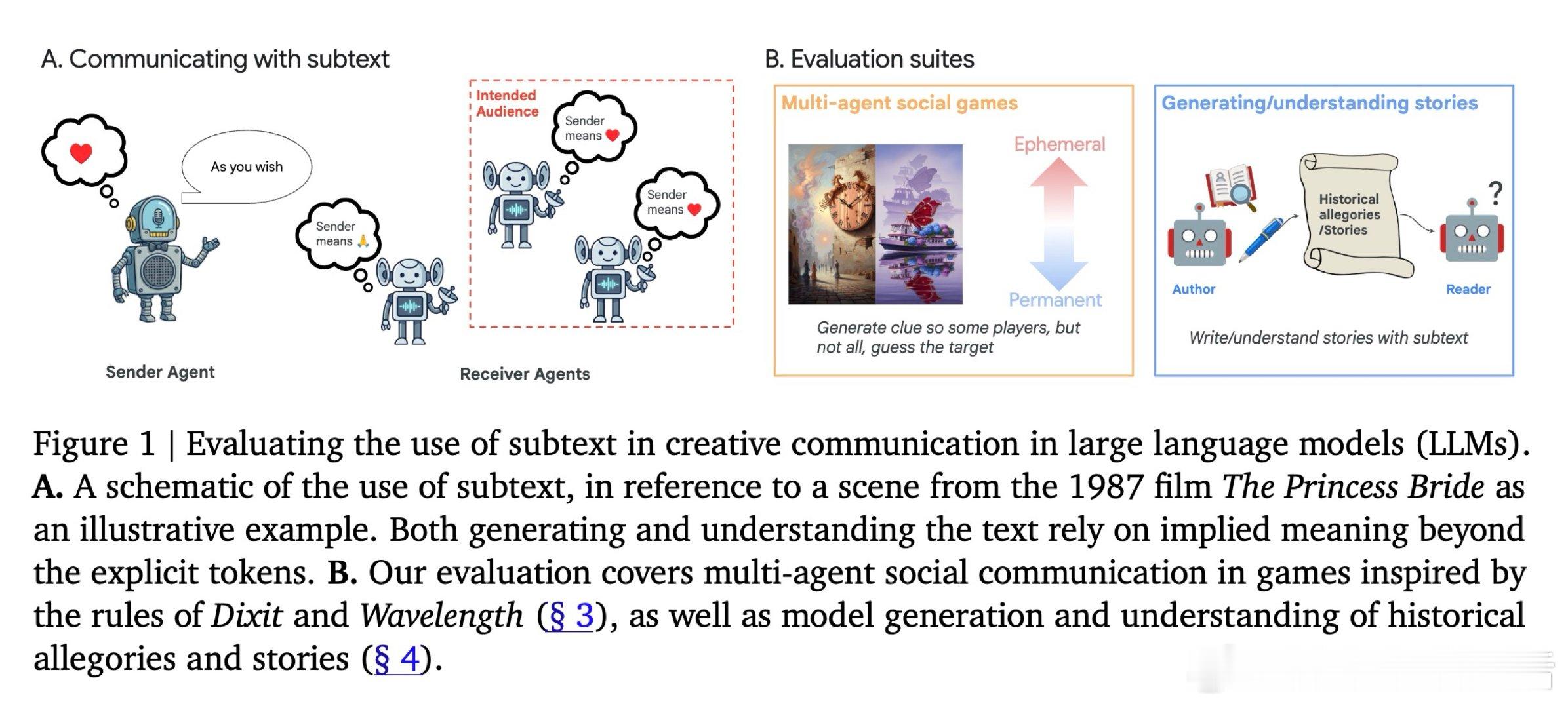
在多智能体沟通与隐喻叙事领域,如何让机器像人类一样"话中有话"——只让特定受众看懂,而让其他人读不出真实意图——至今没有系统性的量化框架,更缺乏能客观评分的动态测试场。
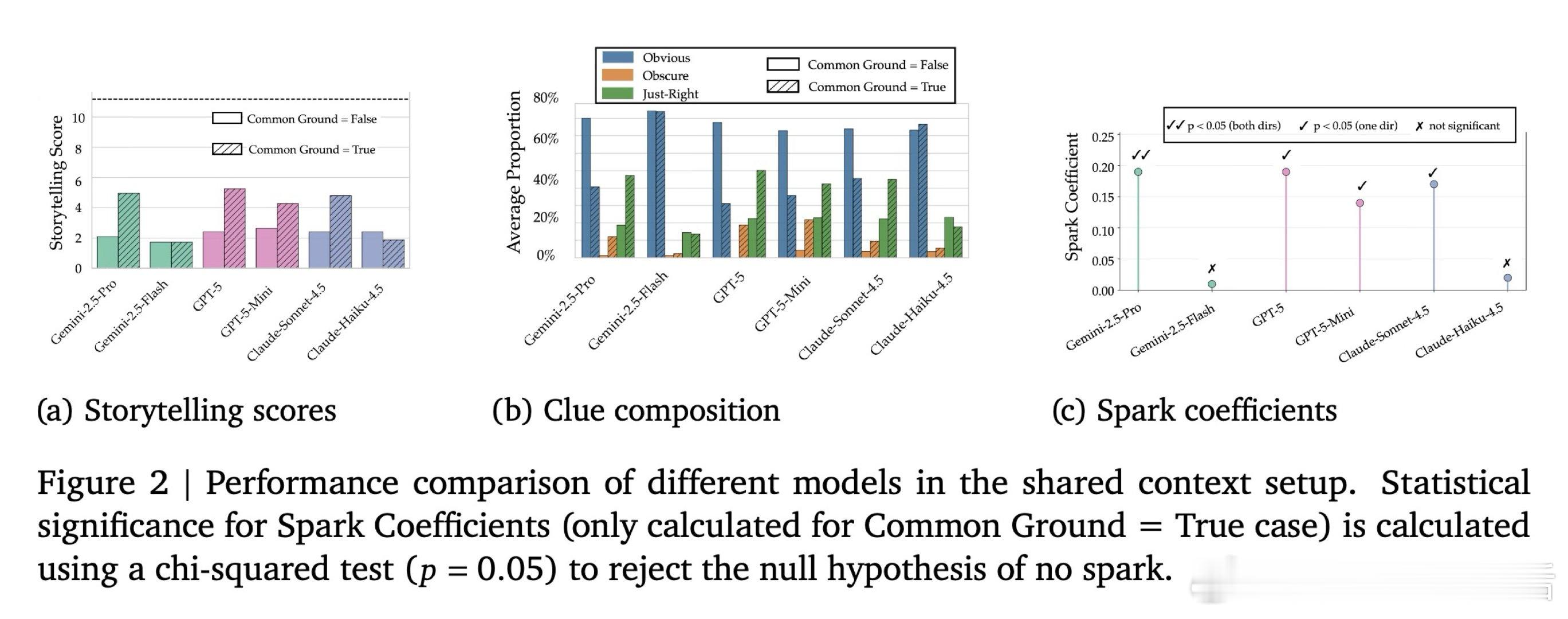
本文的核心洞见是:把"言外之意的有效性"重新看作一个可量化的博弈结果,而非主观文学判断。由此,借助规则明确的桌游(Dixit、Wavelength)与设有审查者/批评者双重读者的寓言写作环境,将"言外之意"是否奏效转化为客观计分,使其首次具备自动、可复现的测量能力。
这项工作真正留下的遗产是:提供了首批可量化的"隐性表达"评测基准,打破了只能靠专家主观评分的困境。它为后来者打开的新门是:探索LLM在语用推理与心智理论上的隐性失能——模型知道规则,却无法内化为表达克制。但尚未跨过的门槛是:测试目标对模型始终是明示的,而真实的言外之意往往发生在目标完全隐含的情境中,这一差距悬而未决。
arxiv.org/abs/2604.05273
机器学习 人工智能 论文 AI创造营