[CL]《Limited Preference Data? Learning Better Reward Model with Latent Space Synthesis》L Tao, X Du, Y Li [University of Wisconsin-Madison & Nanyang Technological University] (2025)
偏好数据有限?用潜空间合成提升奖励模型学习效率
• 关键难点:奖励模型依赖昂贵的人类偏好数据,传统文本合成方法计算资源消耗巨大。
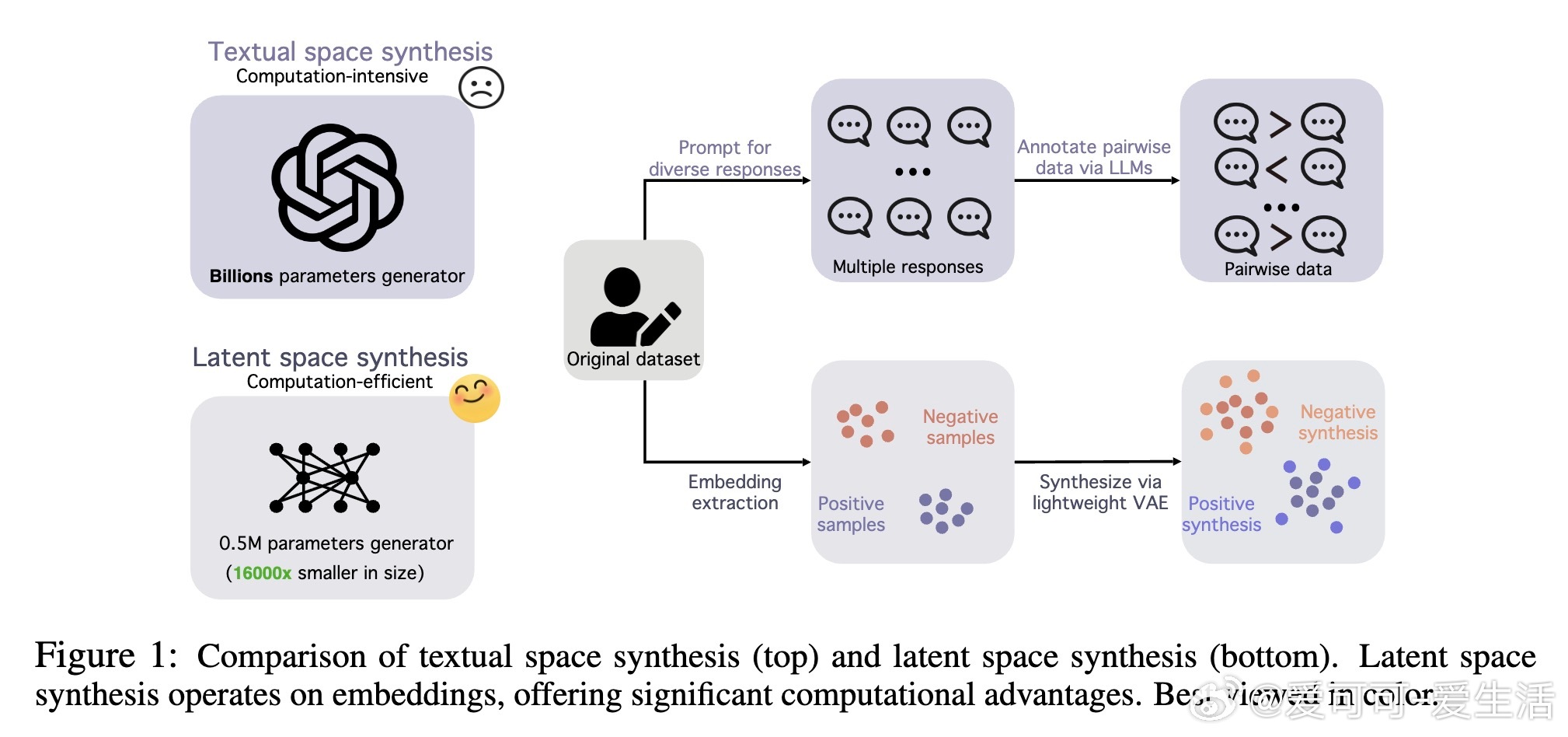
• 创新框架LENS:在大型语言模型(LLM)响应的潜在嵌入空间中直接合成偏好数据,绕过文本生成与注释,极大提升合成效率。
• 核心技术:基于变分自编码器(VAE)学习响应嵌入的结构化潜空间,通过控制潜空间扰动生成多样且语义一致的合成偏好对。
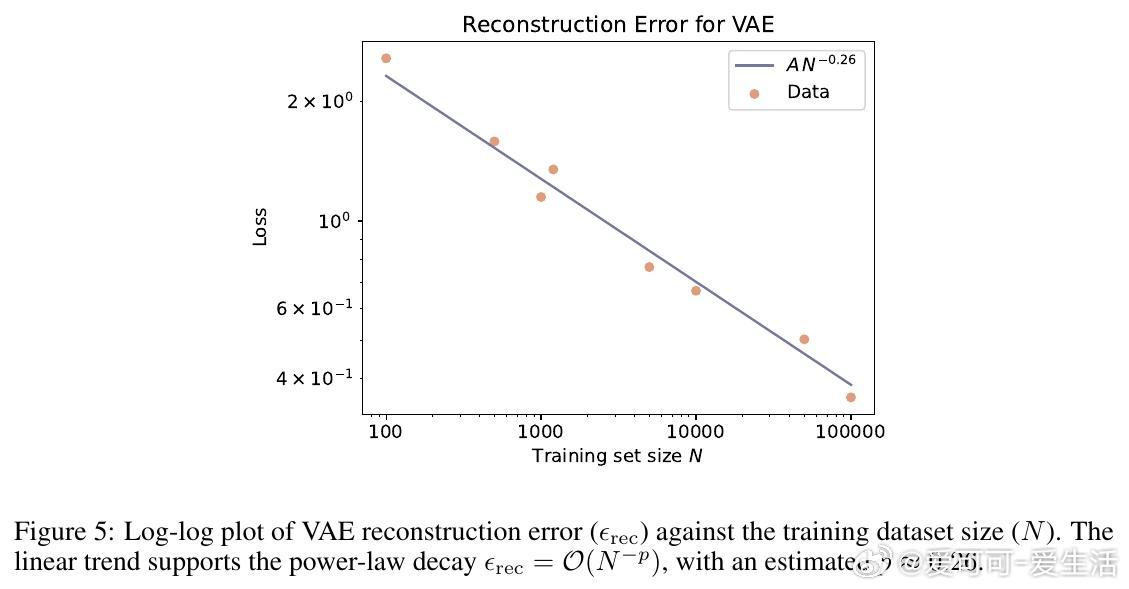
• 理论支撑:合成样本在理想奖励函数下保持原始偏好序,且扩充训练集可降低奖励模型估计误差,实现更好泛化。
• 实验表现:在HH-RLHF和TL;DR数据集上,LENS超越文本合成基线,生成速度快18倍,模型规模小1.6万倍,且跨多种LLM架构均表现优异。
• 计算优势:单次合成仅需0.5M参数,文本合成需8B参数;总运行时间缩短至1/13,适合资源受限环境。
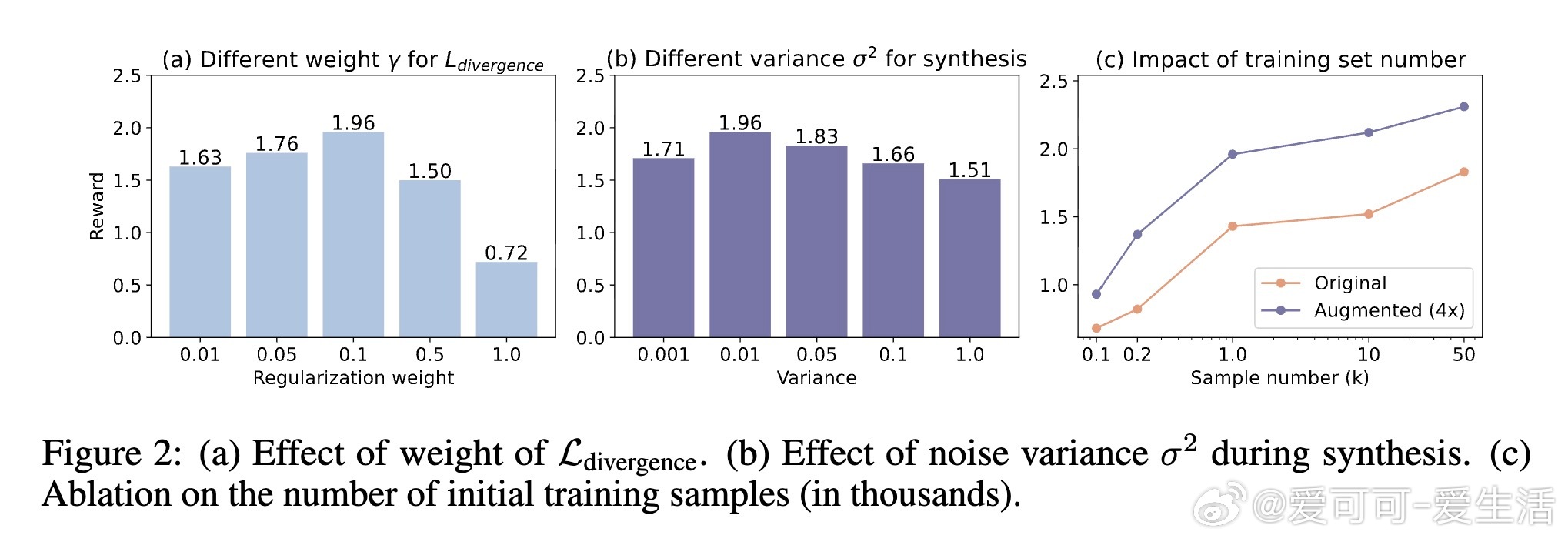
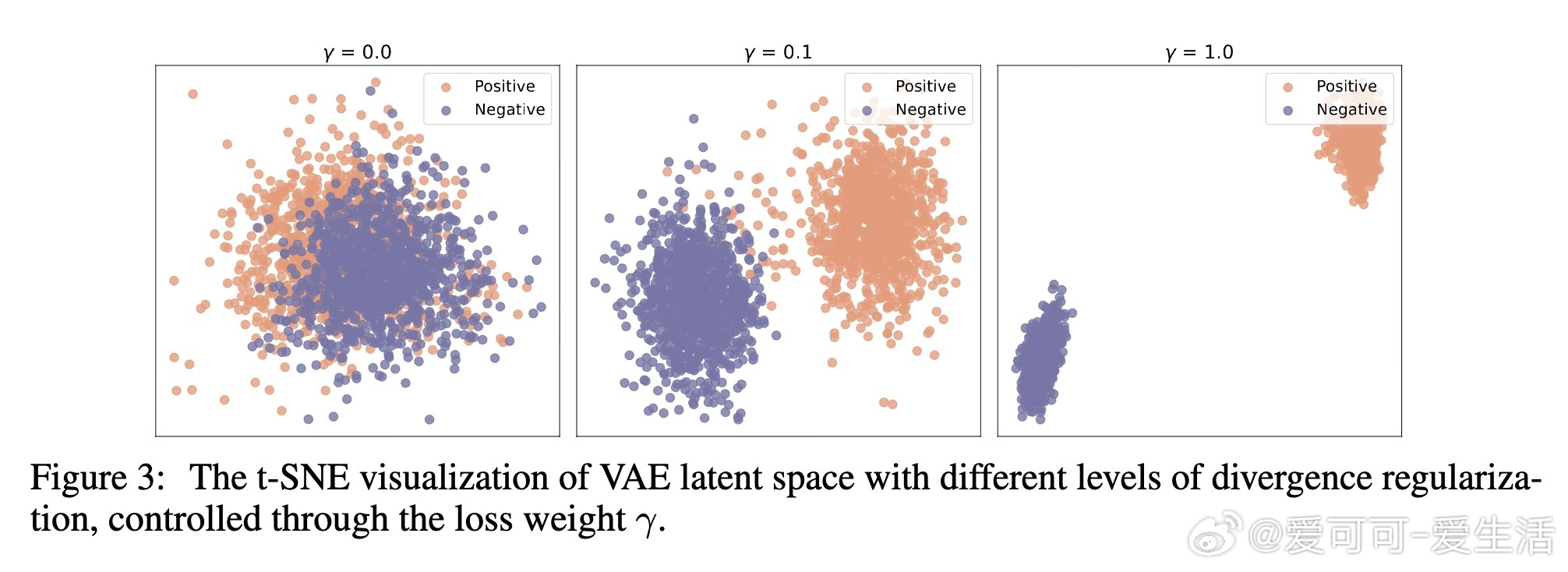
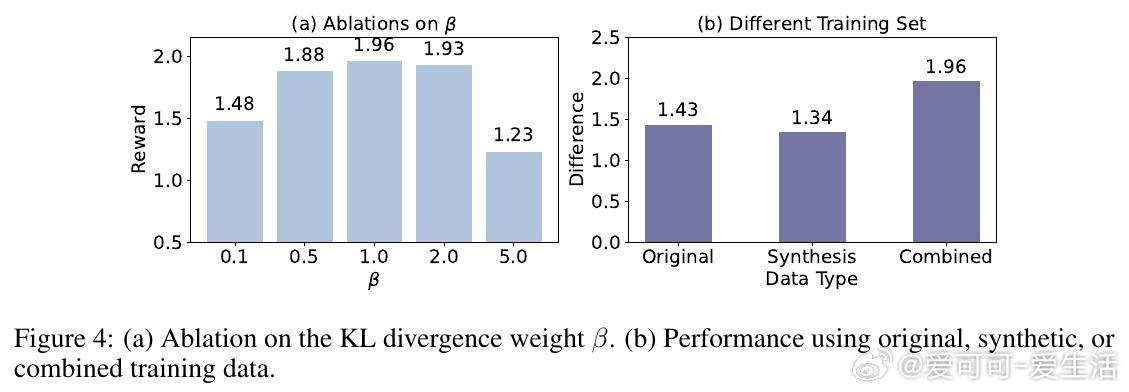
• 设计细节:适度加权潜空间分布分歧损失,控制噪声方差保证合成样本质量与多样性平衡,结合原始与合成数据训练奖励模型效果最佳。
• 下游效应:基于LENS训练的奖励模型指导拒绝采样提升监督微调(SFT)表现,GPT-4评测胜率达61%。
• 限制和展望:当前方法依赖离线固定嵌入,未来可探索在线动态更新潜空间合成,适应训练过程变化。
心得:
1. 在语义潜空间合成偏好数据,远优于传统文本层面生成,体现了深度模型语义表示的巨大潜力与利用价值。
2. 适度的潜空间分布分离既能强化判别能力又避免过拟合,揭示了生成多样性与判别难度间的微妙平衡。
3. 理论与实证结合验证了合成数据对模型泛化的促进作用,展示了数据扩充背后的数学保障与实际效益。
了解详情🔗arxiv.org/abs/2509.26074
代码开源👉github.com/deeplearning-wisc/lens
奖励建模大语言模型数据合成变分自编码器机器学习