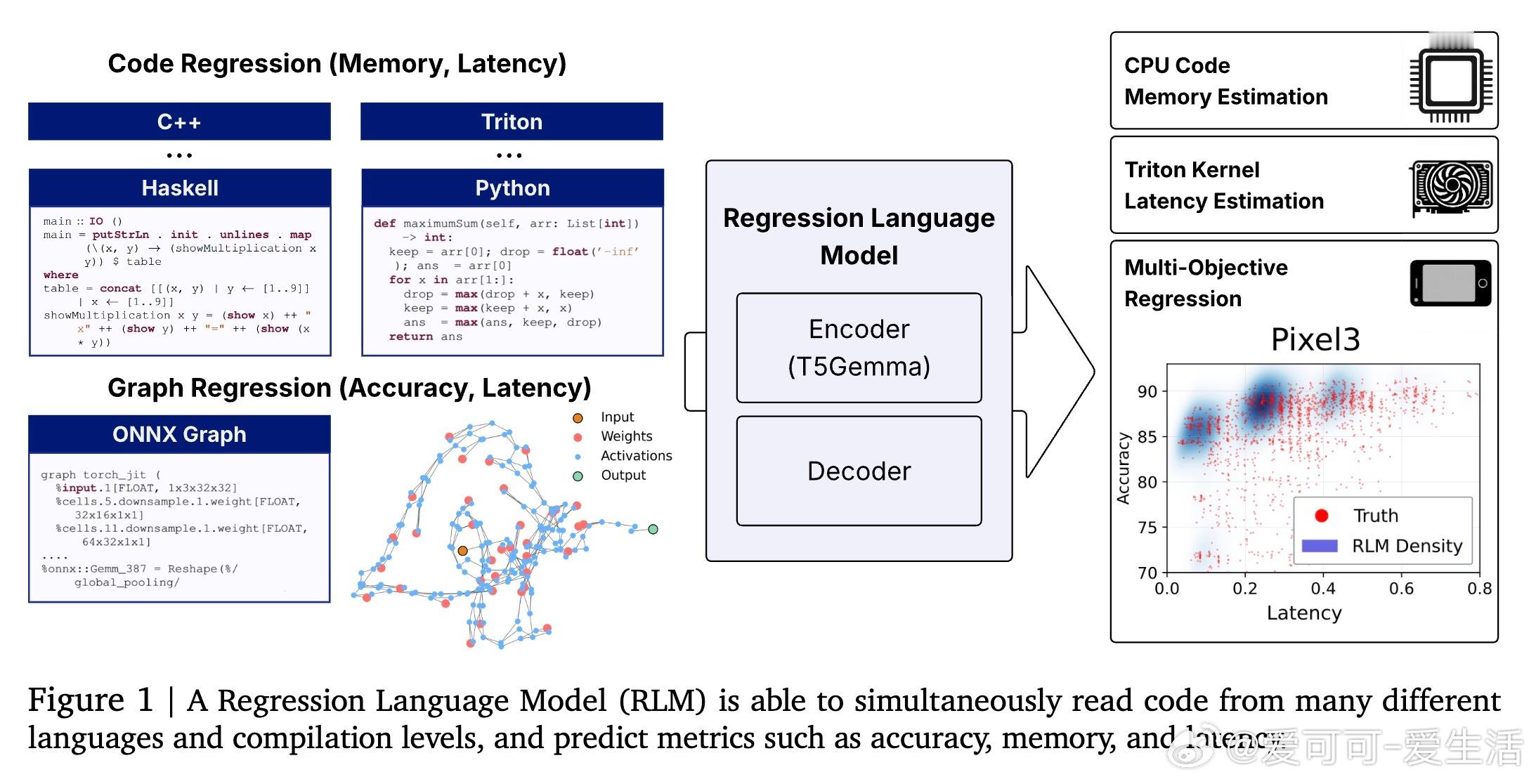
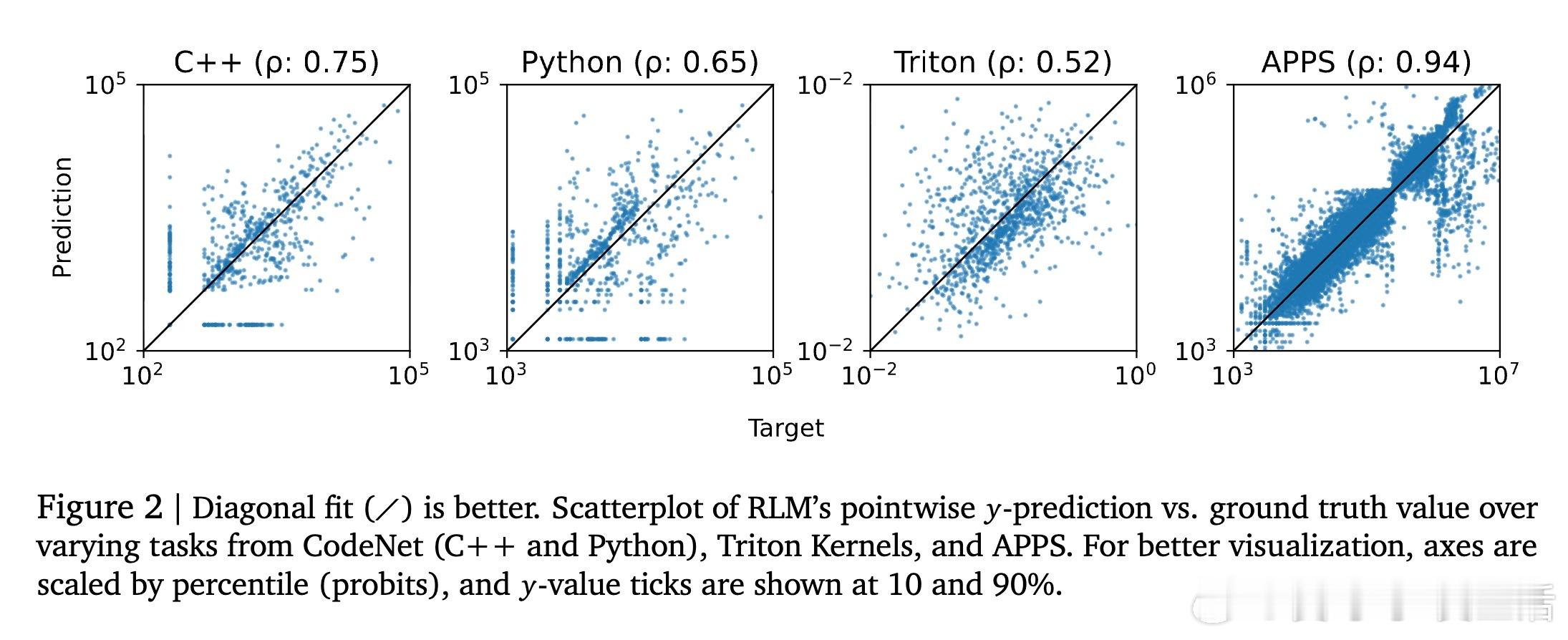
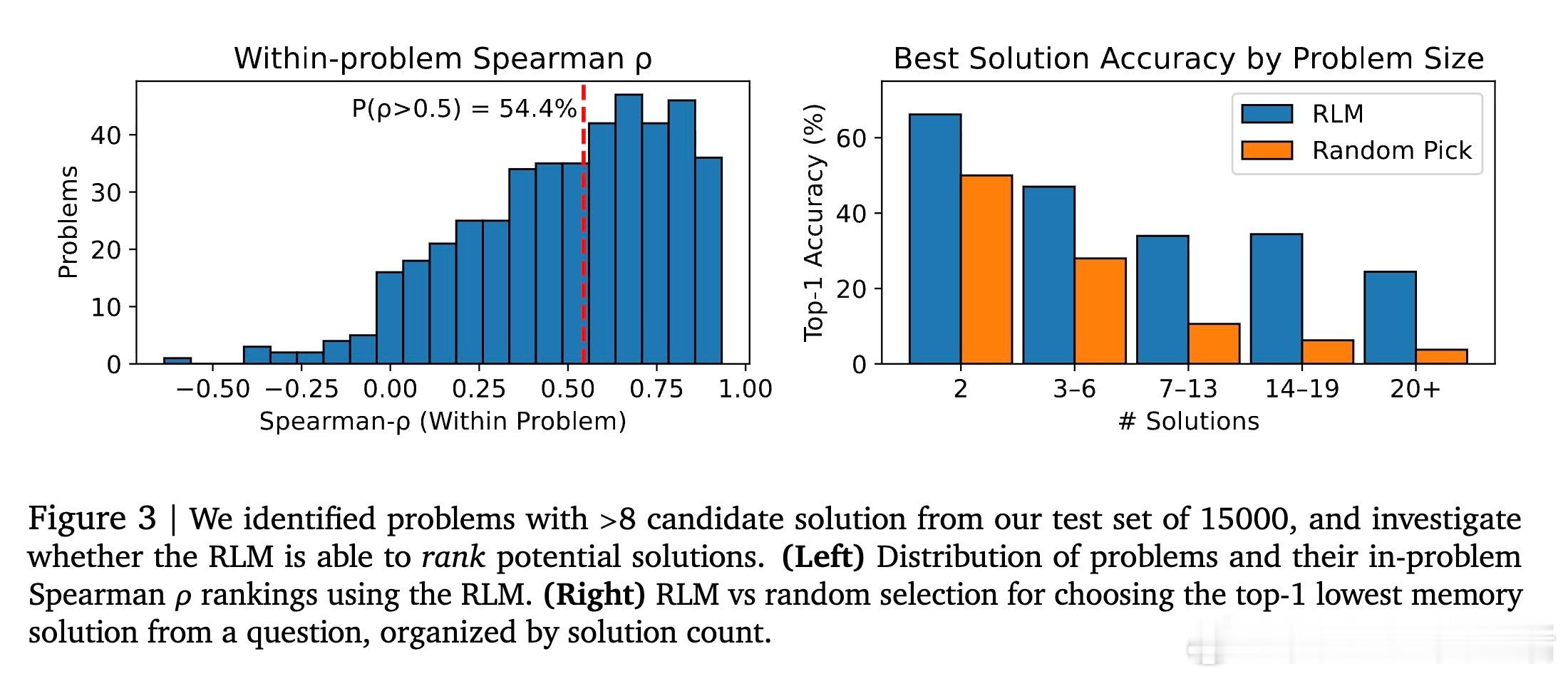
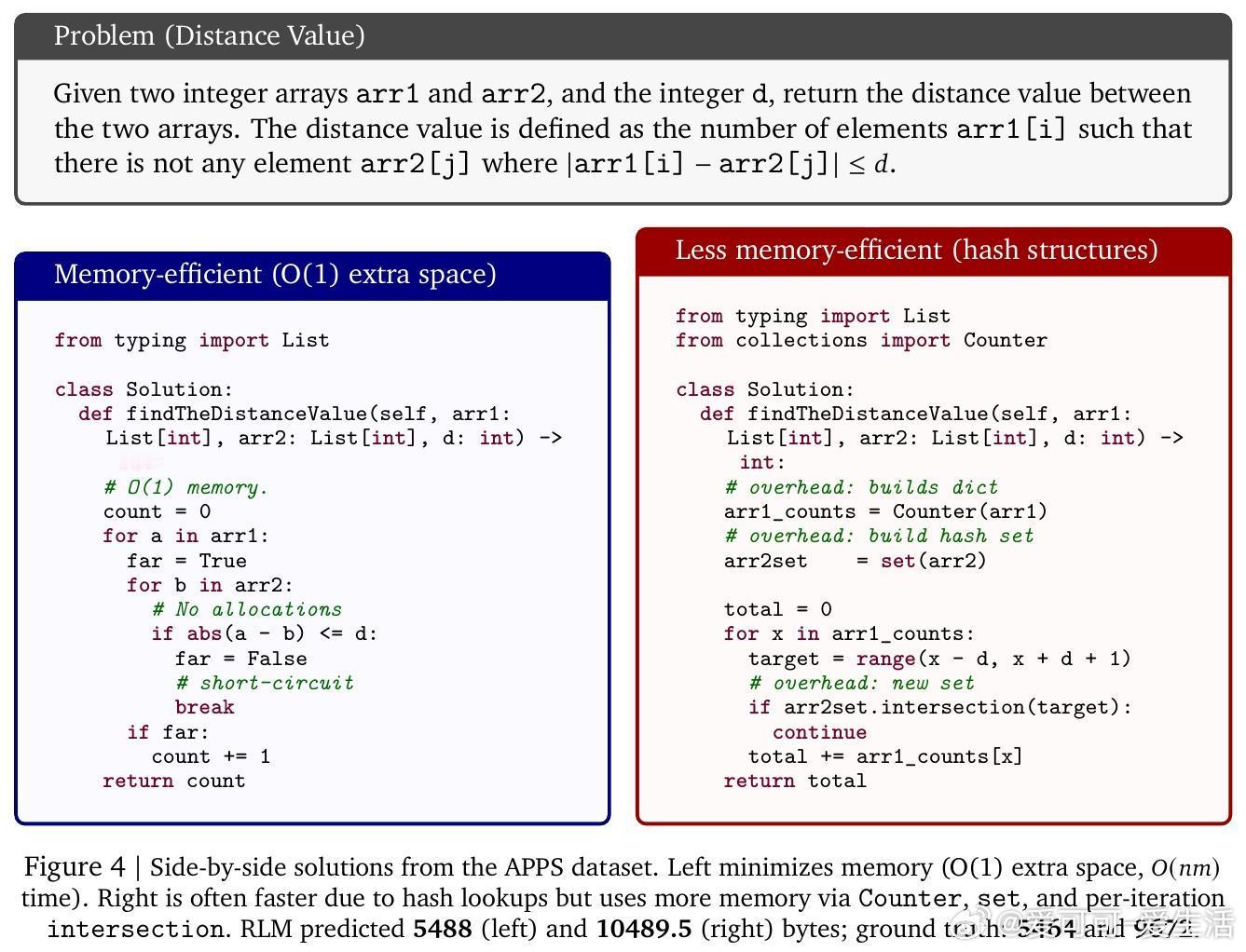
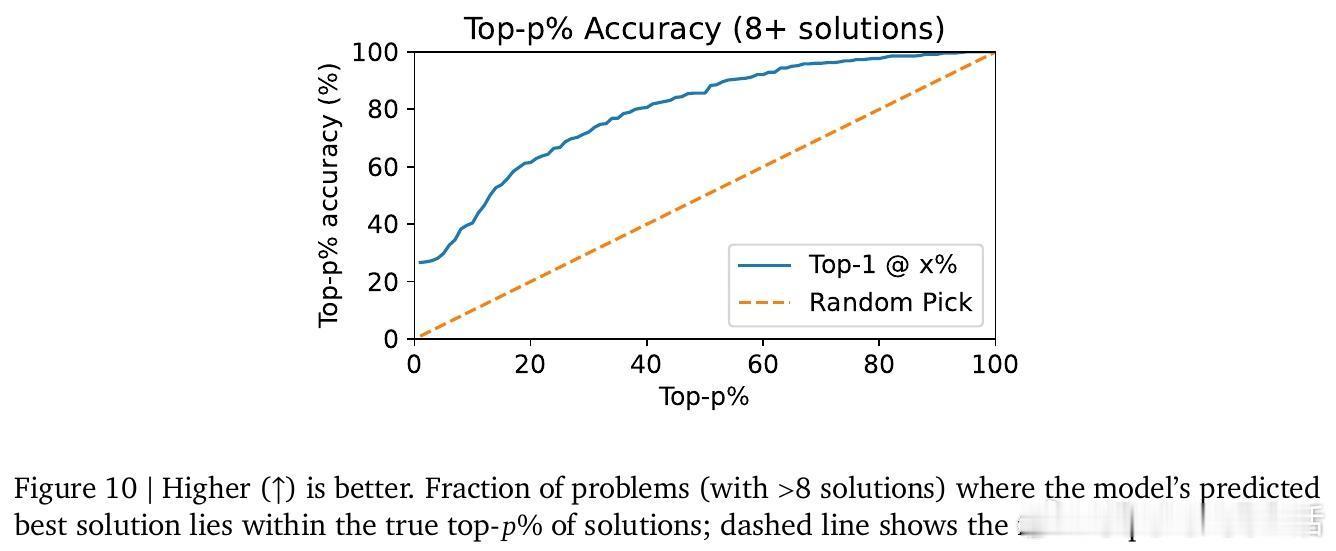
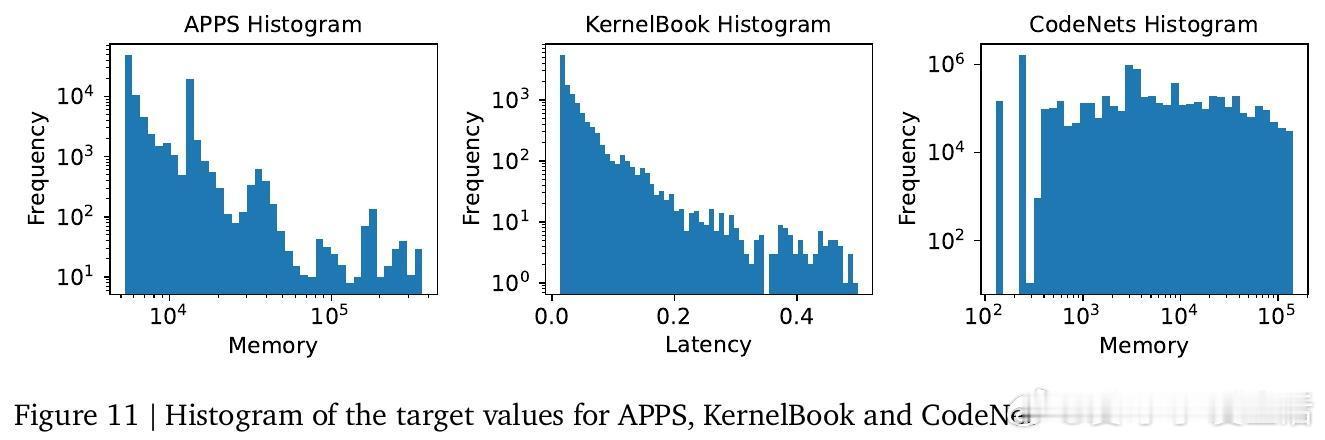
[CL]《Regression Language Models for Code》Y Akhauri, X Song, A Wongpanich, B Lewandowski... [Cornell University & Google] (2025)
语言模型训练进入新阶段:如何突破规模与效率的瓶颈?
• 论文提出“STU”(Sparse Token Unit)训练框架,通过稀疏化处理显著降低训练复杂度,同时保持模型性能。
• 利用动态稀疏激活策略,模型在训练时智能选择关键token参与计算,避免无效冗余,提升计算效率数倍。
• 设计了多层次稀疏机制,不同层次自适应调节稀疏度,实现训练资源与性能的最优平衡。
• 兼容主流Transformer架构,易于集成现有大规模语言模型训练流程,无需专门硬件支持。
• 实验表明,在相同计算预算下,STU训练的模型在语言理解和生成任务上表现优于传统密集训练。
• 该方法为构建更大规模、更高效的语言模型提供了可行路径,助力AI应用更广泛落地。
心得:
1. 关键不是单纯堆参数,而是高效利用每个token的计算贡献,智能稀疏是提高训练效率的突破口。
2. 动态稀疏机制打破静态模型结构限制,赋予模型自适应选择计算路径的能力,体现了训练与推理的融合趋势。
3. 兼容性强意味着该技术可迅速推广,促进更多团队在有限资源下实现更大模型的训练尝试。
详情🔗arxiv.org/abs/2509.26476
人工智能语言模型深度学习稀疏训练Transformer