[LG]《RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems》Y Qu, A Singh, Y Lee, A Setlur... [CMU & Stanford University] (2025)
RLAD:用抽象引导大语言模型高效解决复杂推理难题
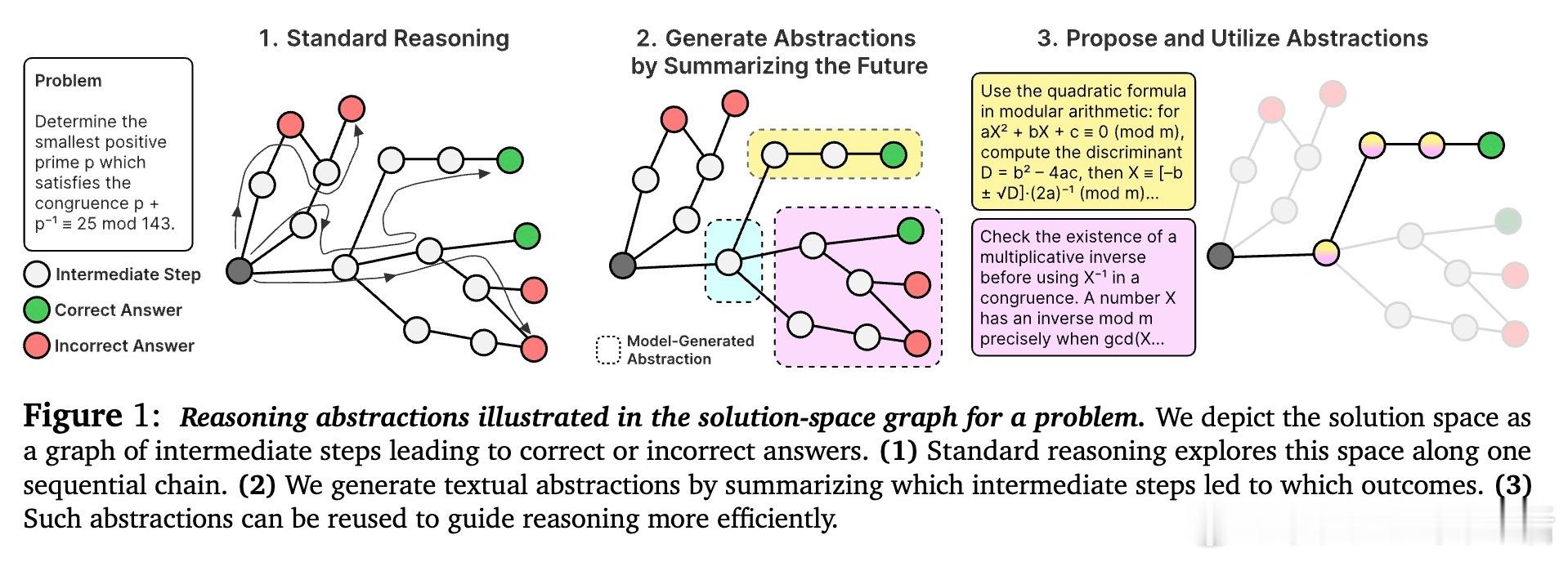
• 推理不仅是模式匹配,更需发现并利用“算法式程序”,即关键原语与中间结果,突破传统长链思考中“深度”探索陷入的逻辑混乱和低效。
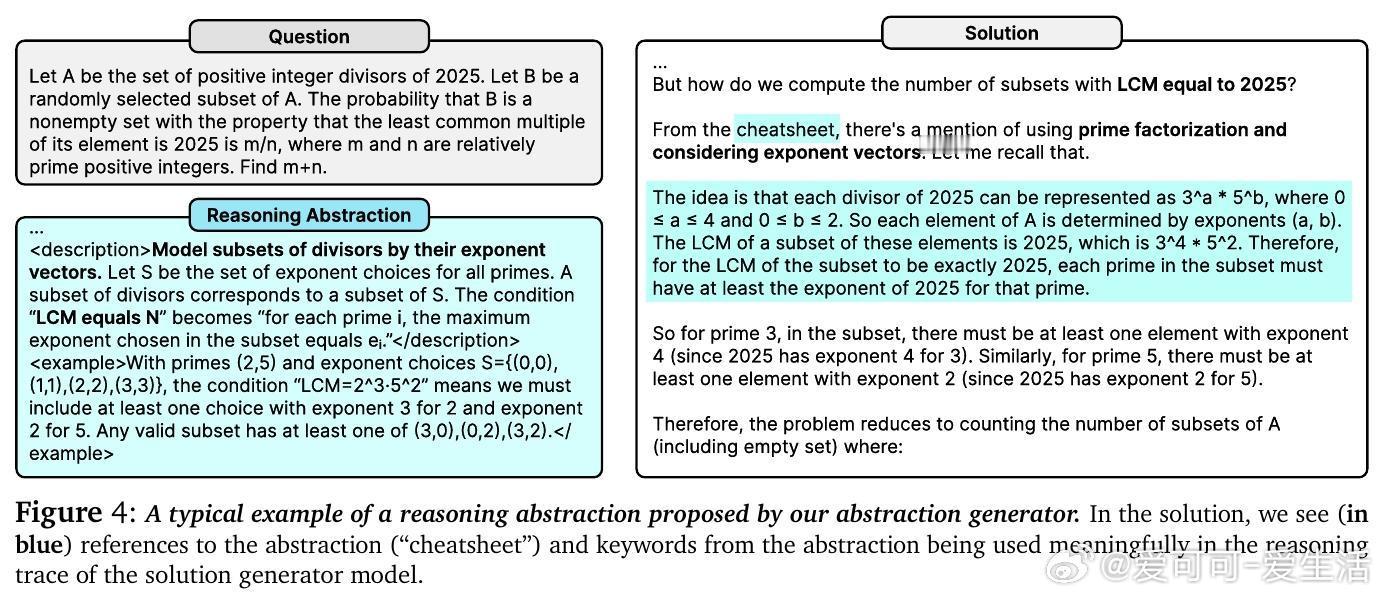
• 引入“推理抽象”——简洁的自然语言描述,浓缩程序性与事实性知识,作为模型探索多样推理策略的高层指导。
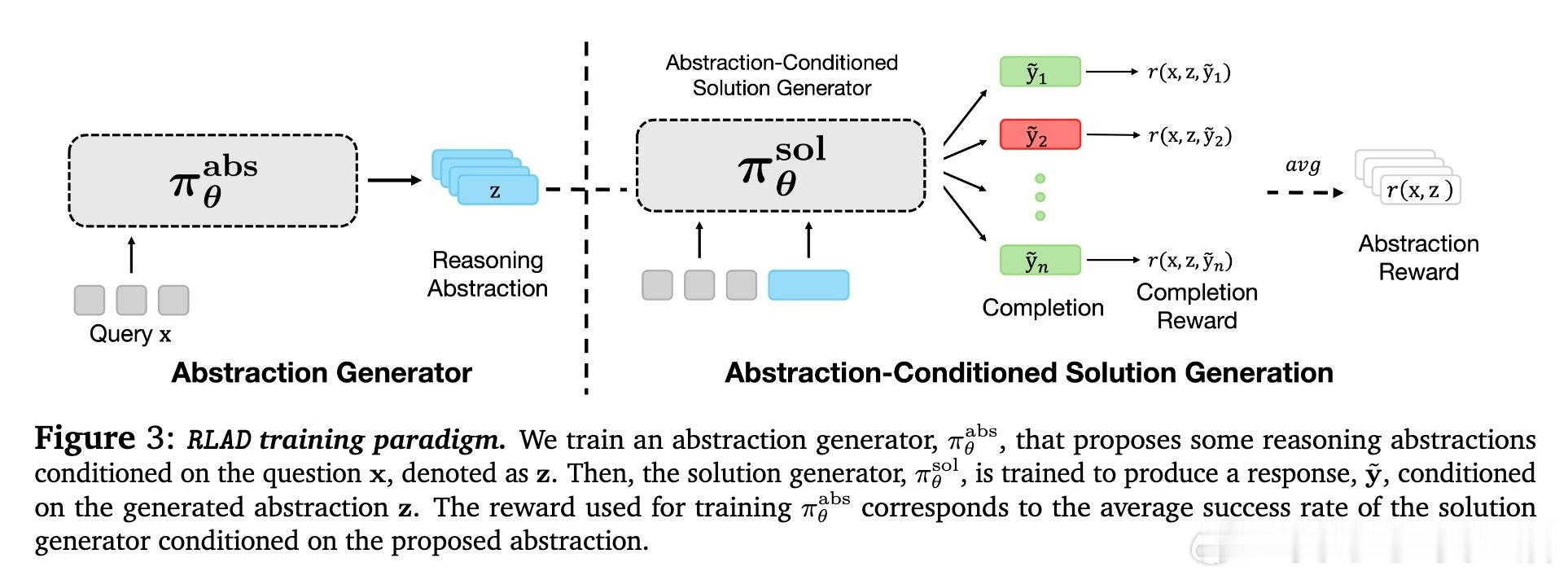
• 双模型强化学习训练框架RLAD:一方生成多样抽象,另一方基于抽象条件生成解答,奖励机制鼓励抽象提升解答准确率,实现结构化探索与信号解耦。
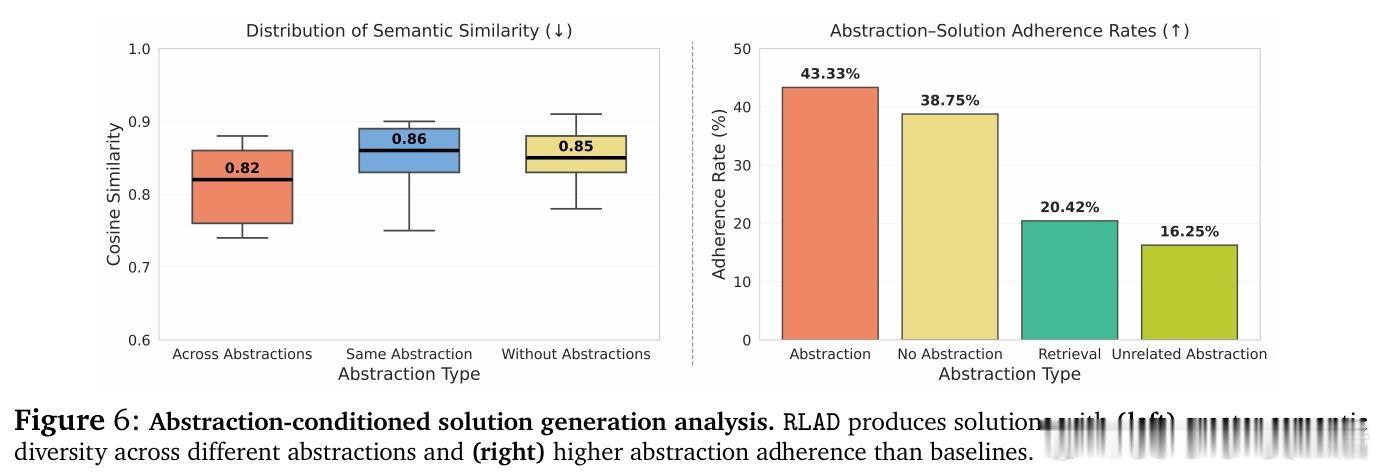
• 通过对数学推理(AIME 2025、DeepScaleR Hard、AMC 2023)及ARC-AGI程序合成任务验证,RLAD在无抽象及抽象条件下均显著优于现有RL长链思考方法,最高提升达44%。
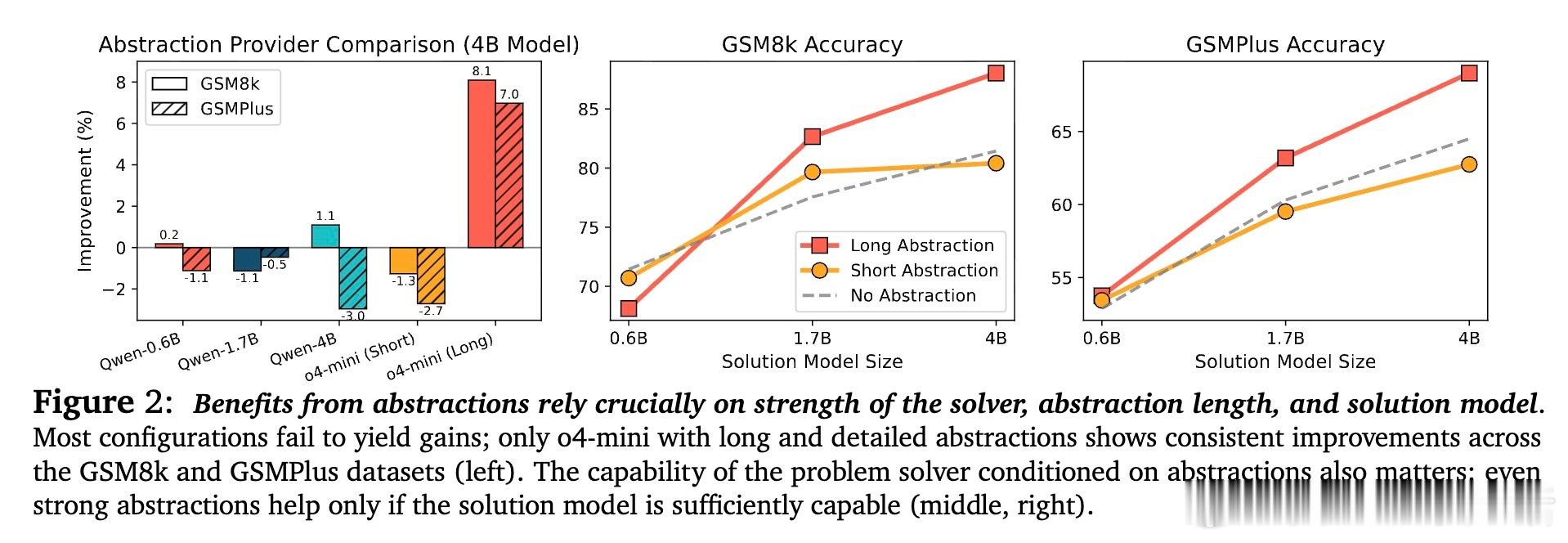
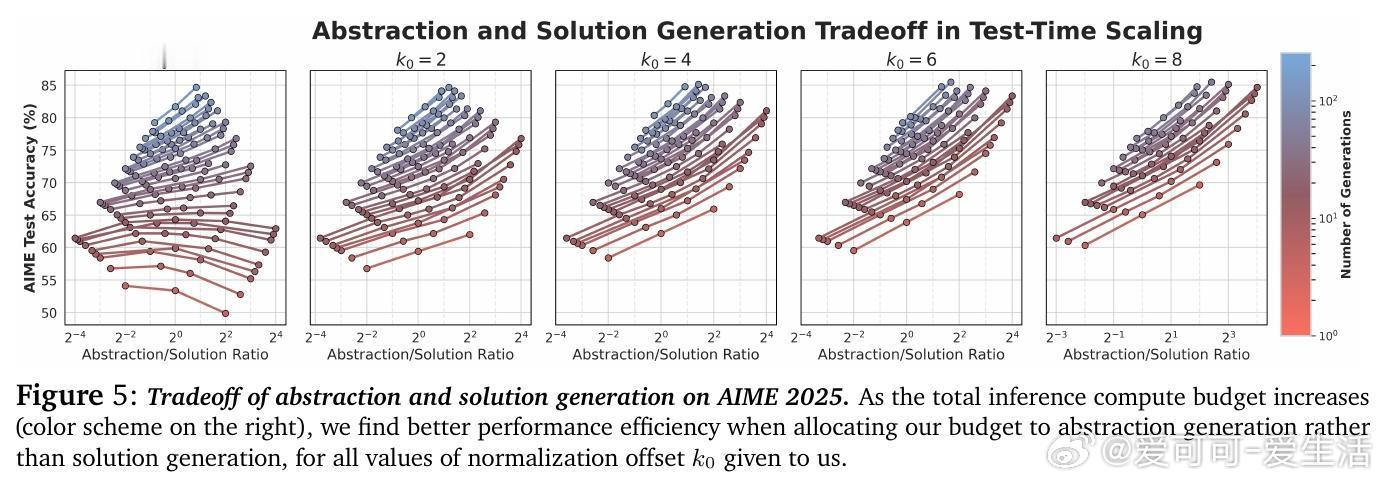
• 研究计算资源分配表明,投入更多算力生成多样抽象,较单纯增加解答采样更有效提升表现,强调抽象作为推理多样性和探索的关键杠杆。
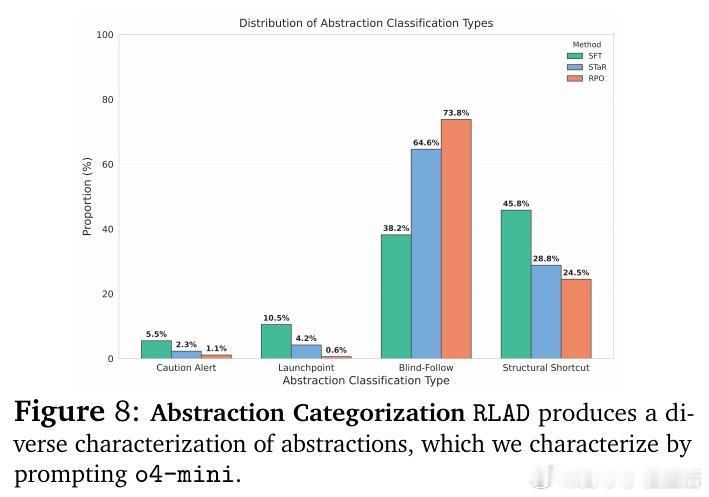
• 抽象类型涵盖警示(避免误区)、启动点(策略框架)、盲从路径(可重复执行流程)、结构捷径(抽象不变量),帮助模型跨结构相似问题泛化。
• 抽象生成不仅限数学,医疗、法律等37个任务领域均提升约30%准确率,展现极强的跨领域适用性与指导意义。
心得:
1. 抽象作为高层次“策略提示”,能有效引导模型跳出局部最优陷阱,提升推理广度和多样性。
2. 协同训练抽象和解答模型,分离奖励信号,解决单一模型难以同时掌握抽象发现与利用的难题。
3. 计算资源应优先投向生成抽象而非单纯加深链条或增加解答样本,体现推理效率优化的新范式。
详情🔗arxiv.org/abs/2510.02263
人工智能大语言模型强化学习数学推理算法抽象模型训练