[LG]《Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models》S Xie, L Kong, X Song, X Dong... [CMU] (2025)
训练复杂推理任务的扩散大语言模型迎来新突破——Step-Aware Policy Optimization(SAPO)算法:
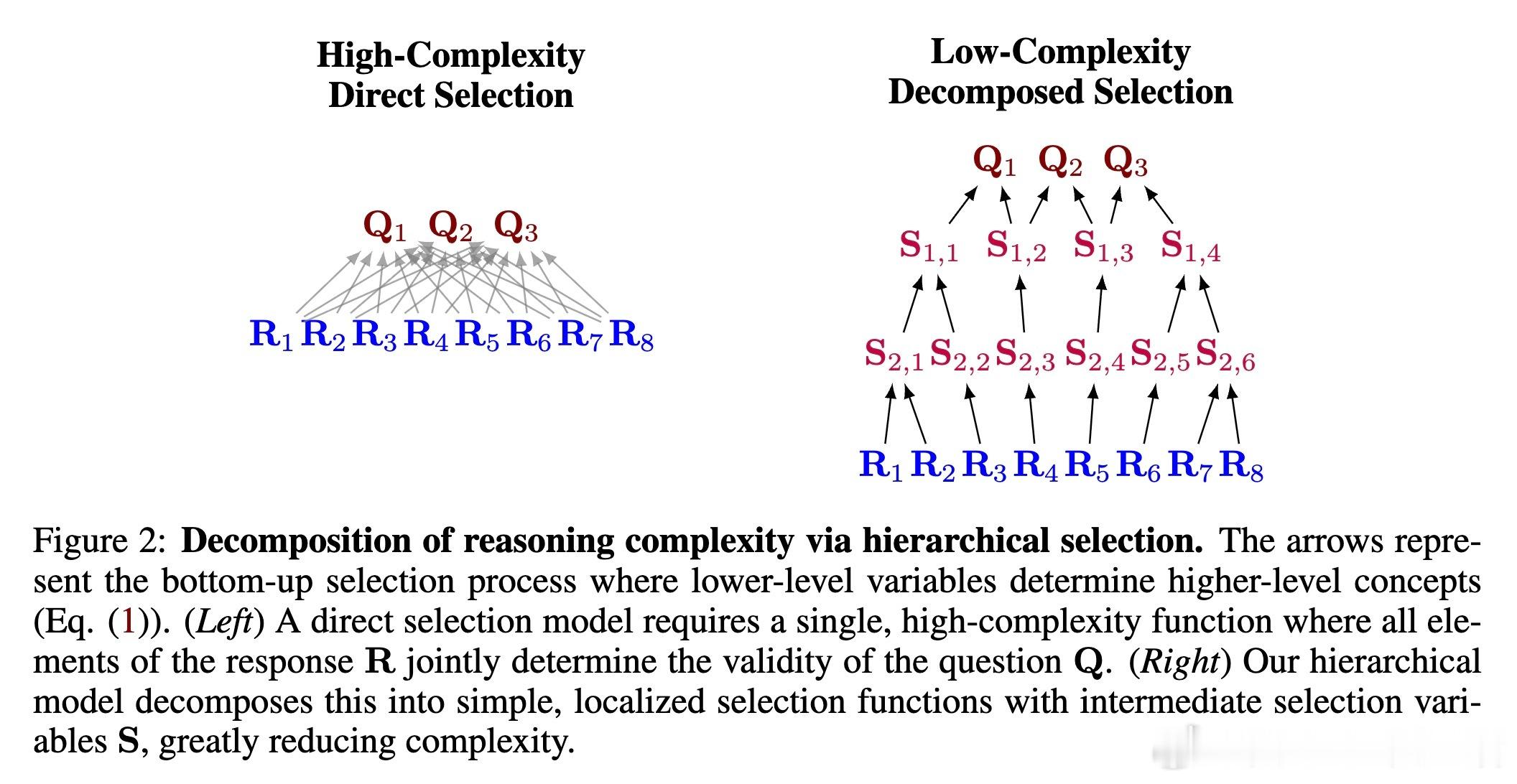
• 颠覆传统:将复杂推理视为一个层级选择过程,分解全局难解约束为一系列简单、局部的逻辑步骤,符合人类解题思路。
• 识别潜在结构:理论证明潜在推理层级结构可从问题-解答数据中辨识,为算法设计提供坚实基础。
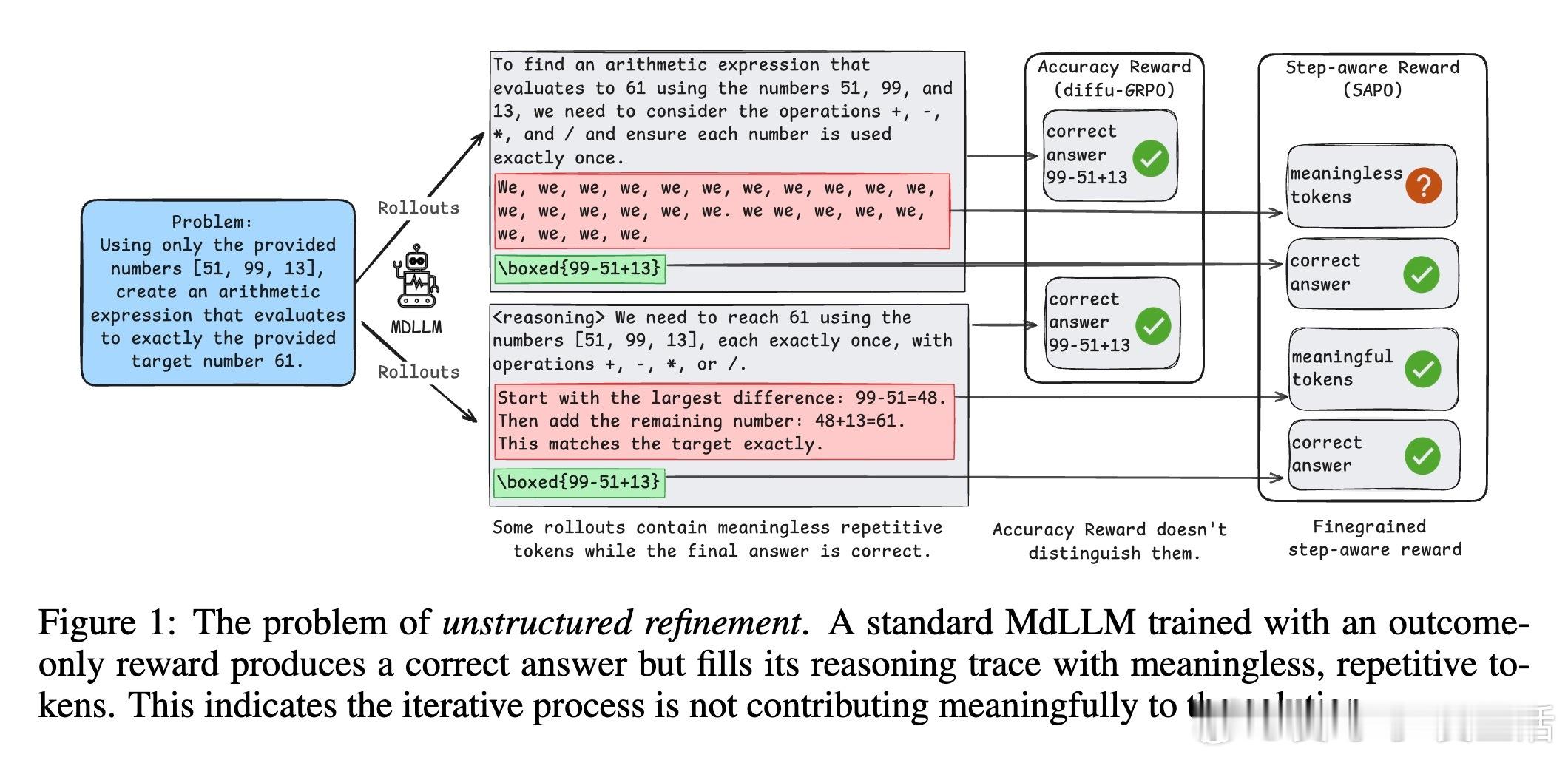
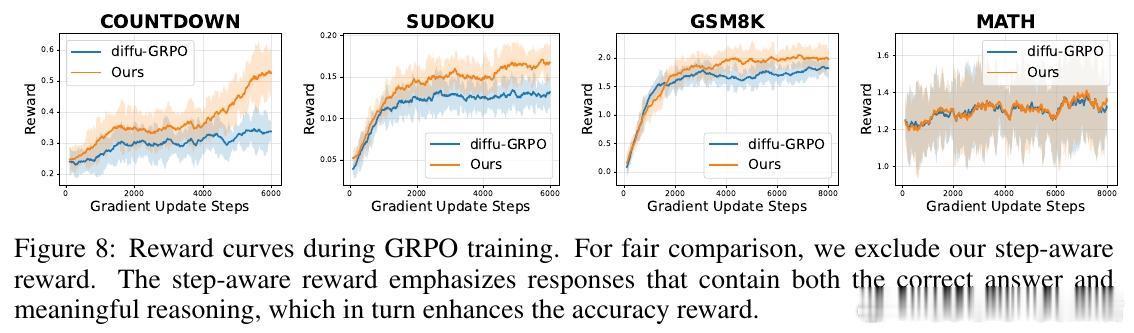
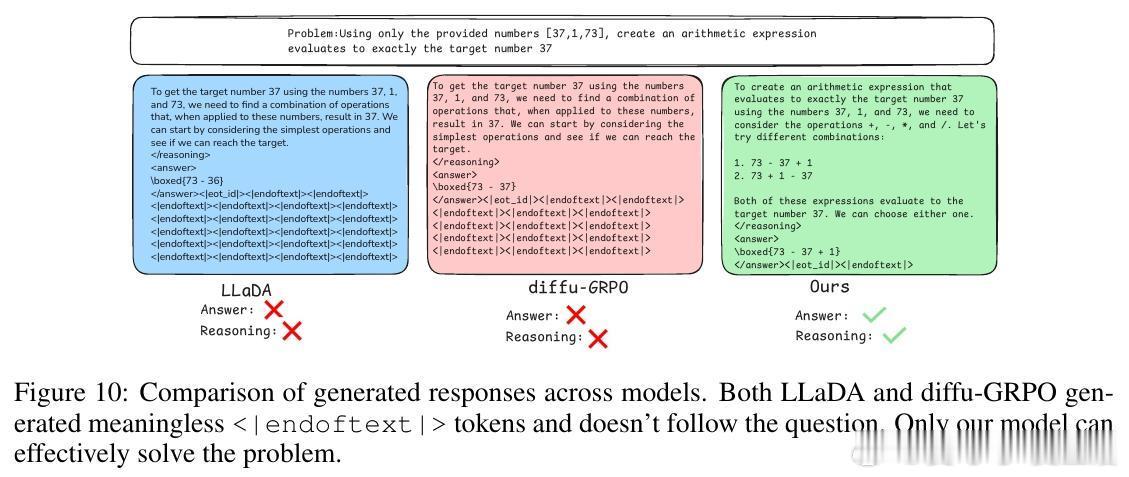
• 解决“无结构细化”难题:传统基于最终结果的稀疏奖励往往强化偶然正确但推理混乱的路径,SAPO通过过程奖励引导模型在每个去噪步骤实现有意义的进展。
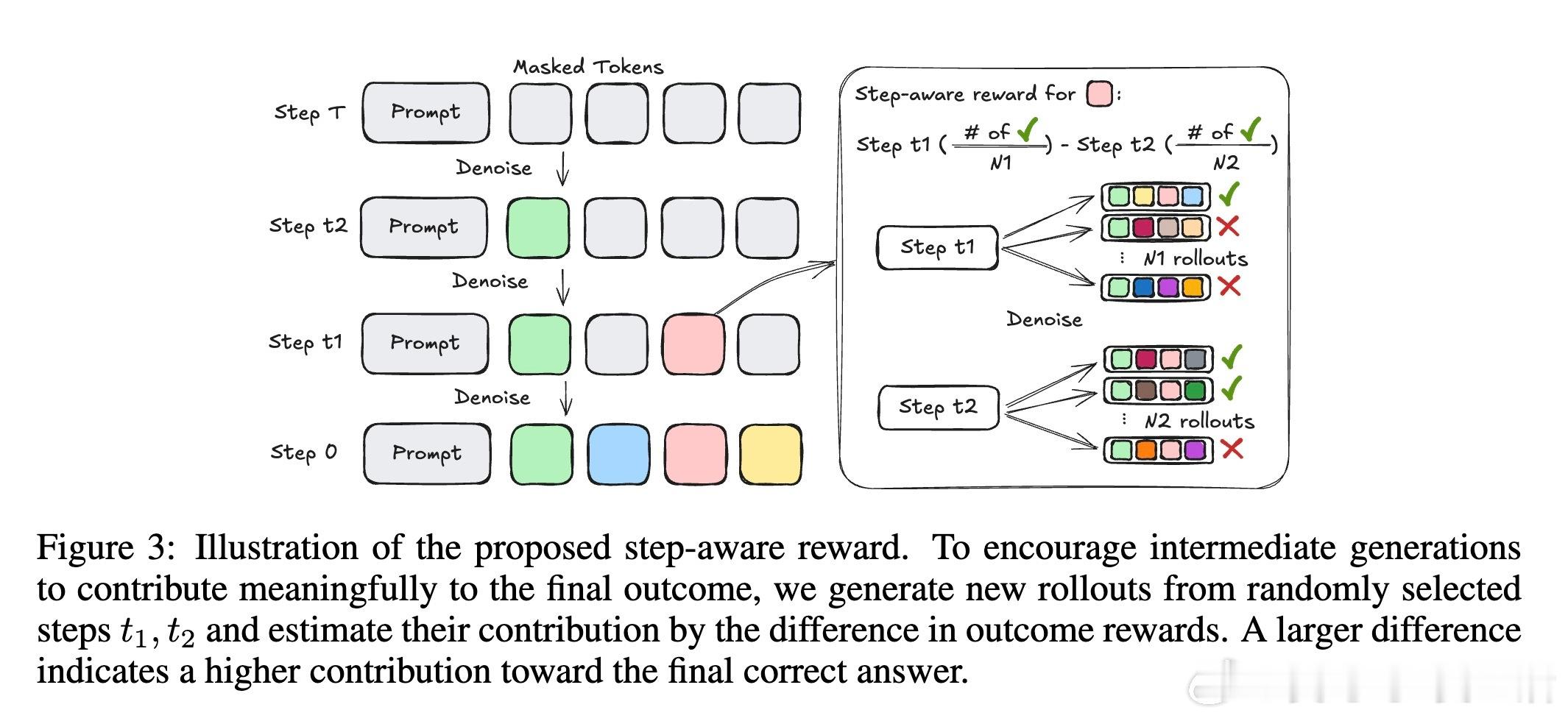
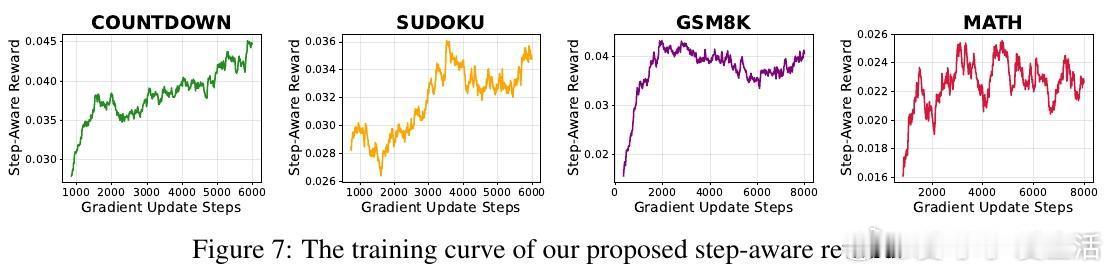
• 过程奖励机制:随机采样中间去噪步骤,比较其产生的答案准确率差异,作为奖励信号,无需人工标注中间状态。
• 强化学习框架:基于Group Relative Policy Optimization(GRPO),结合过程奖励,提升训练稳定性和推理连贯性。
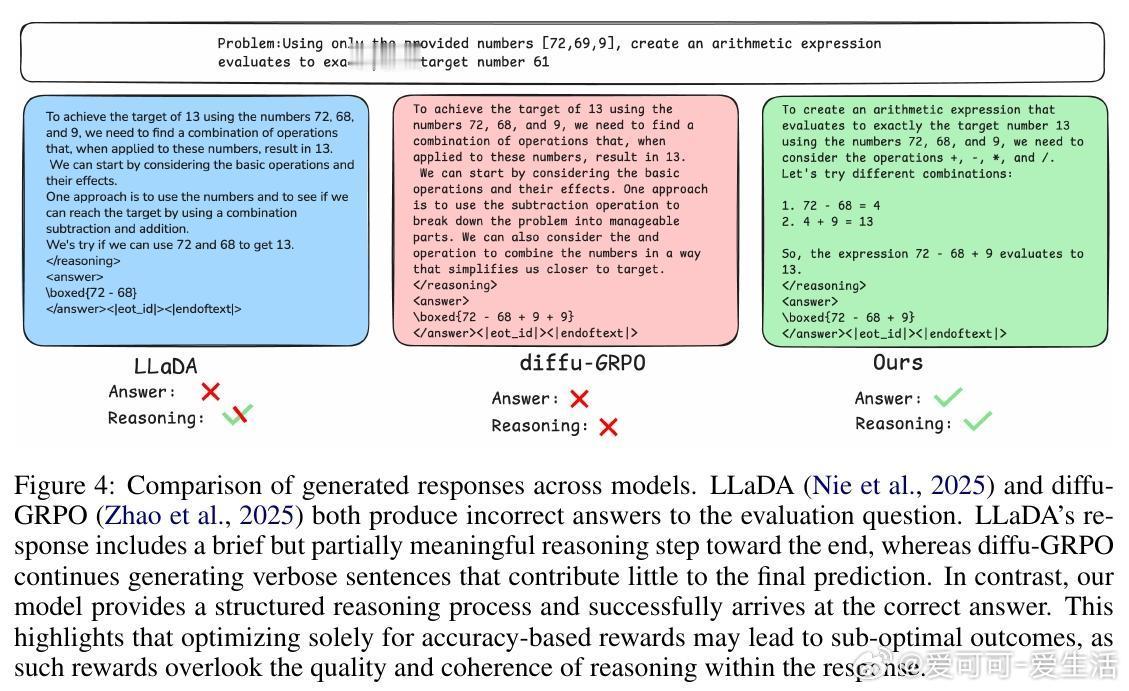
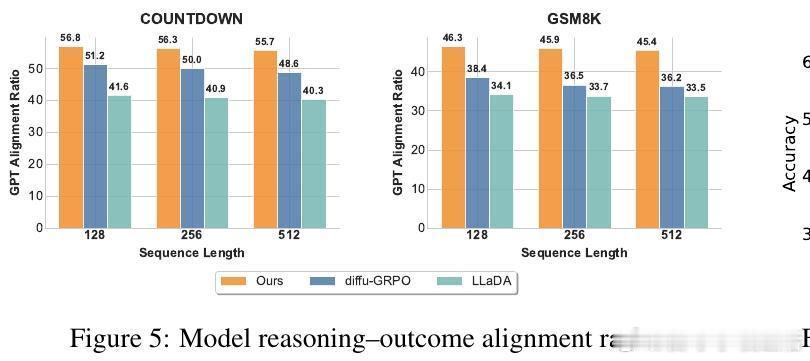
• 显著提升效果:在GSM8K、MATH、COUNTDOWN、SUDOKU等多个复杂推理基准上超越现有Mask-based dLLMs和强化学习方法。
• 中间答案精度更高:支持推理加速技术,通过在去噪中间步骤获得准确答案实现快速解码。
• 具备强泛化能力:在未见过的SVAMP数学推理和ARC常识问答数据集上均表现优异。
• 开源代码与模型已发布,便于社区复现和扩展。
心得:
1. 复杂推理的本质是逐层递进的约束满足,训练策略应顺应此层级结构而非仅关心最终结果。
2. 稀疏的结果奖励无法避免错误推理路径被强化,过程奖励为引导模型学会合理推理提供了有效“中间监督”。
3. 结合理论可辨识性和实证过程奖励,能系统提升扩散式语言模型在多步推理任务上的表现和可解释性。
详情🔗 arxiv.org/abs/2510.01544
代码🔗 github.com/Mid-Push/SAPO-LLaDA
扩散语言模型强化学习复杂推理层级建模人工智能