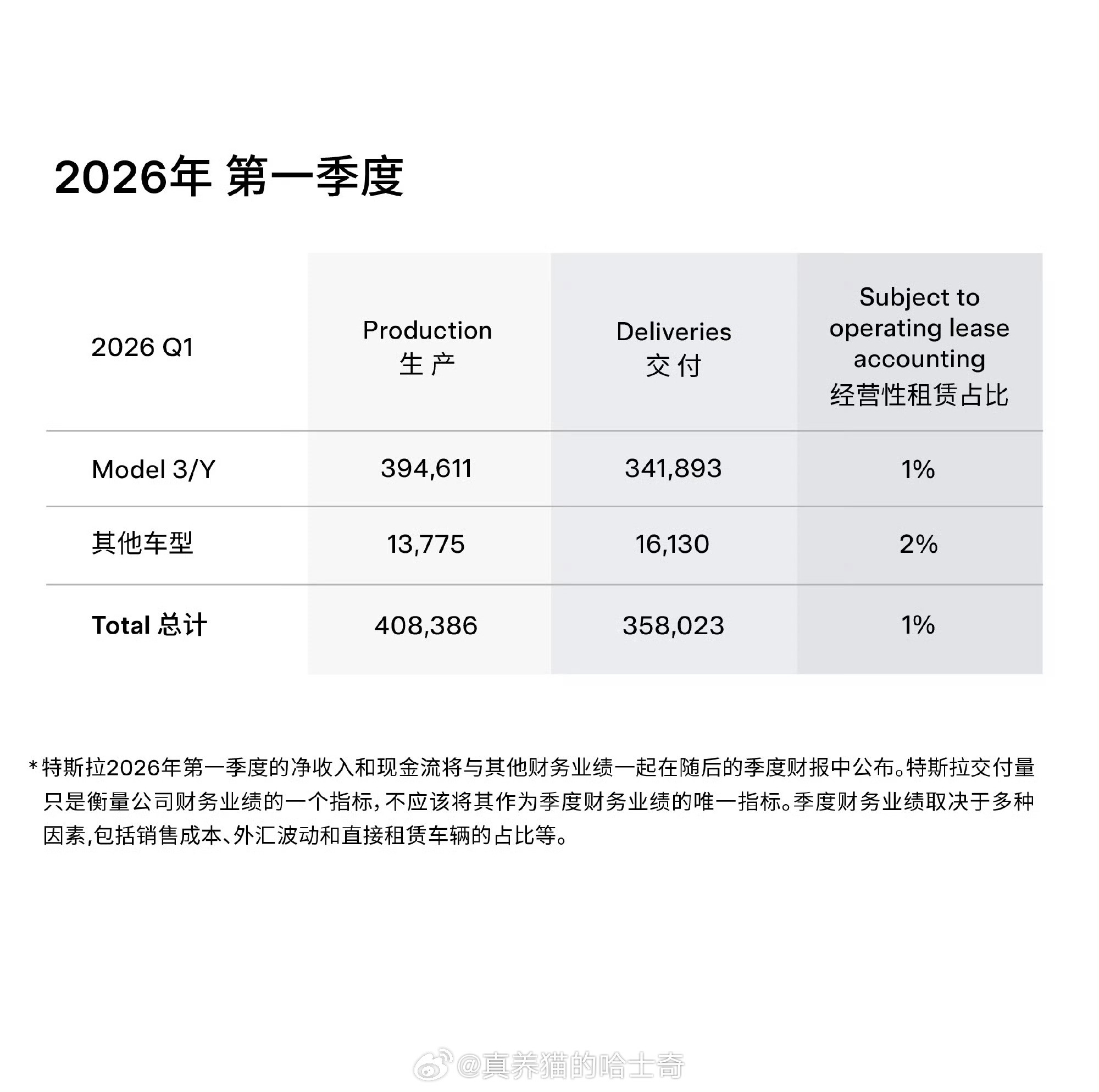
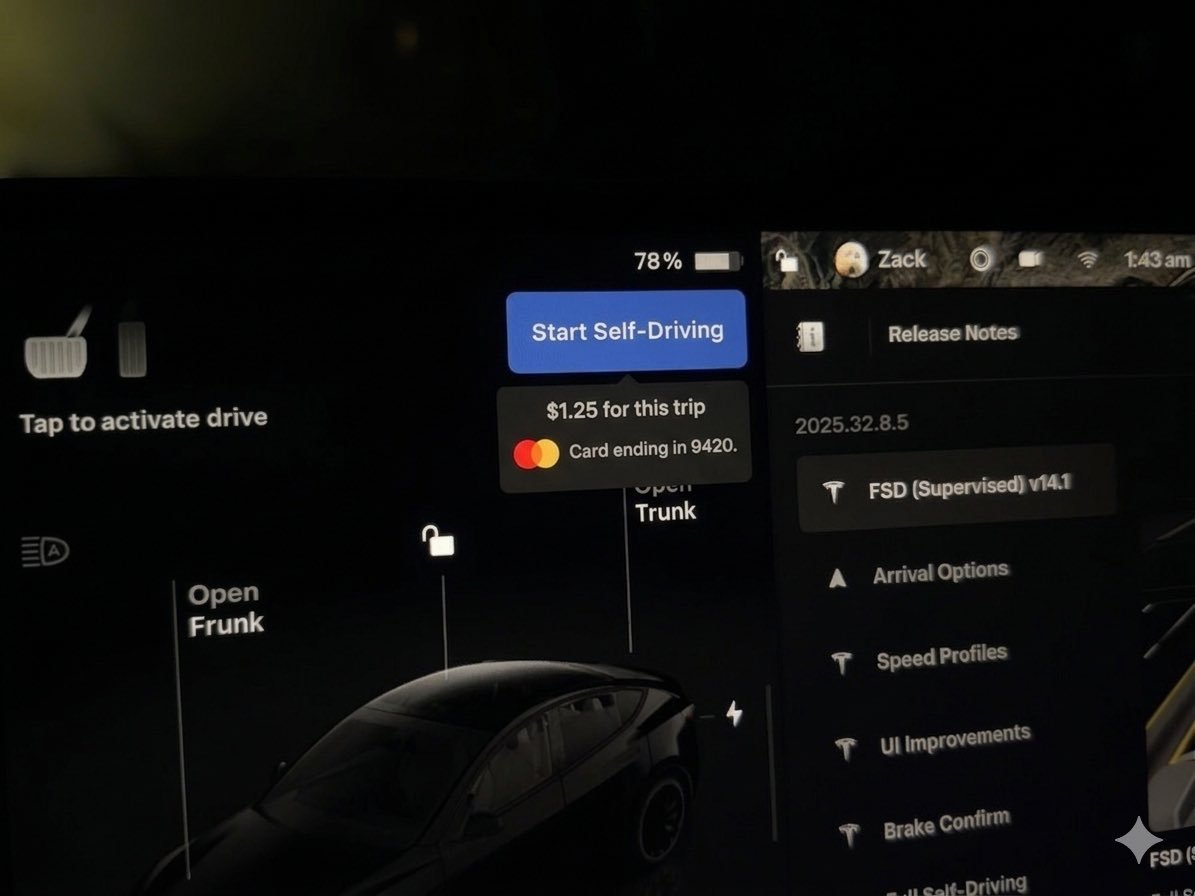
看了特斯拉 FSD v14.3 的更新日志,其中诸多的改进,比如通过 RL 训练在各种驾驶场景中都取得了改进,比如加强对警车、校车、加塞车的响应,甚至通过重写编译器提升了 20% 的反应速度。
这些如何在评测中体现?很难。
原因在于,在 FSD v14.2 中,上述这些场景在 99% 的情况下表现都已经非常好,提升 20% 无疑是很大的改进,但 FSD v13 延迟已经很低,如何量化呈现?
很难很难。
和一个做模型研发的朋友聊,从研发的角度,特斯拉内部可能积累了几十万条的极端场景闭环测试数据集。让 FSD v14.2 和 14.3 跑一遍,就能看出是否有提升了。
这些极端场景假设日常跑 1000 km 会遇到一次,特斯拉如果有 10 万条,跑一次就相当于内测测了 1 亿 km 了。
即便如此,特斯拉 AI VP Ashok 在去年演讲中说,评估仍然是他们面临的最有挑战的问题。
我们也能看到,从特斯拉内部车队开始推,再到今天推到外部用户全量,还是存在各种小 bug。
如果模型已经解决了一个又一个复杂场景,在 99% 的情况下表现都很好,继续推进就会越来越难。评测也会越来越难。
辅助驾驶这个事,快结束了。