[LG]《Loopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall》M Jo, J Yoon, J Deschenaux, C Gulcehre... [KAIST & EPFL] (2025)
钻取离散扩散模型的采样壁:确定性绕过机制
离散扩散模型作为自回归生成的有力替代,通过并行解码实现整个序列的迭代精炼,提供显著的速度提升和全局上下文利用。然而,它们面临“采样壁”问题:采样后,丰富的类别分布信息崩塌为one-hot向量,无法跨步传播,导致后续步骤信息受限,引发闲置步骤和过度振荡等低效现象。本文提出“Loopholing”机制,通过引入确定性潜在路径保留并传播分布上下文,构建Loopholing离散扩散模型(LDDMs)。该机制在生成中产生随机one-hot输出和确定性连续向量;在训练中采用自条件策略,避免全序列展开,仅需随机采样时间步即可高效训练。这不仅深化了模型对上下文的理解,还缓解了信息丢失的核心痛点,推动非自回归文本生成向高质量、可扩展方向发展。
采样壁问题剖析
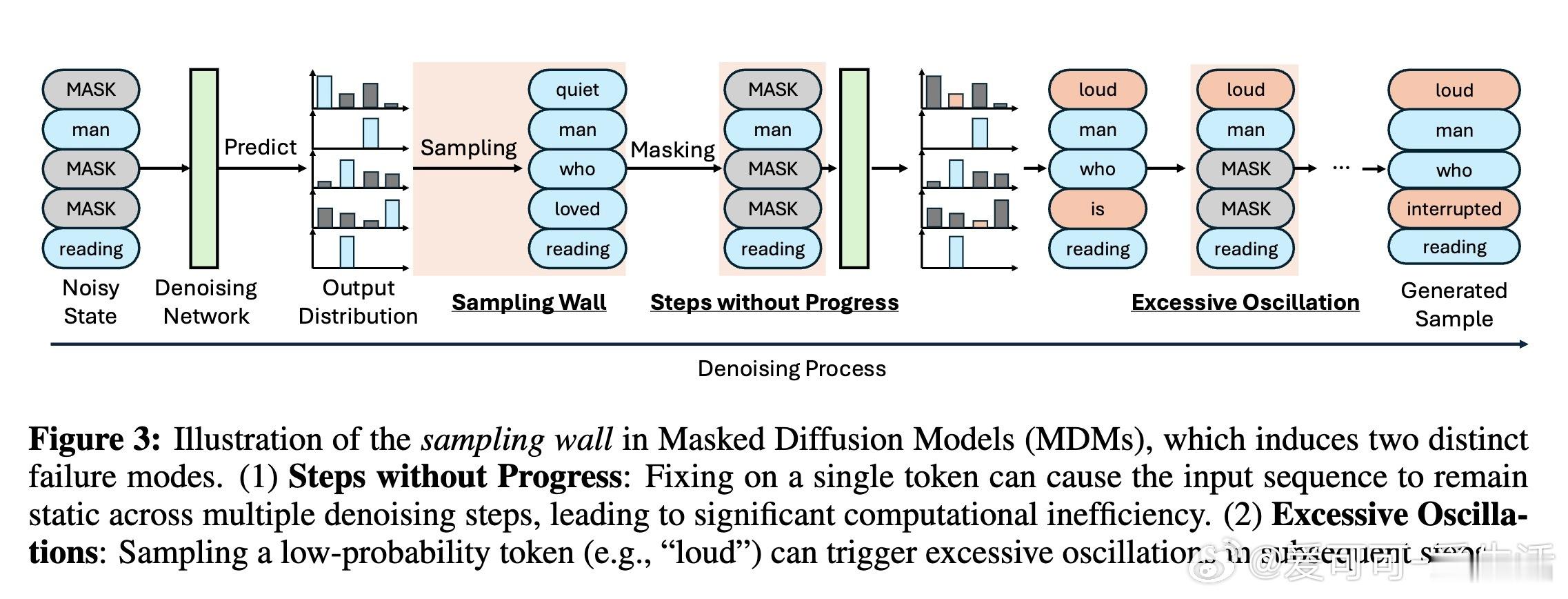
传统离散扩散模型的前向过程通过噪声调度逐步退化数据(如Masked Diffusion Models中渐进掩码,或Uniform Diffusion Models中均匀噪声)。反向去噪时,模型预测原始数据分布,但采样瞬间丢失概率细节。例如,两个分布[0.49, 0.51]和[0.20, 0.80]在采样相同类别后不可区分,导致后续重构从头开始,放大不确定性。Loopholing的核心假设是:显式传播采样前的丰富上下文(如潜在嵌入hs),能缓解闲置步骤(无进展迭代)和振荡(低概率采样诱发反复),从而提升生成连贯性和效率。这反映了生成模型的本质挑战:平衡随机探索与确定性指导,尤其在长序列中,信息持久化可模拟RNN的记忆机制,却无需模拟训练。
Loopholing机制详解
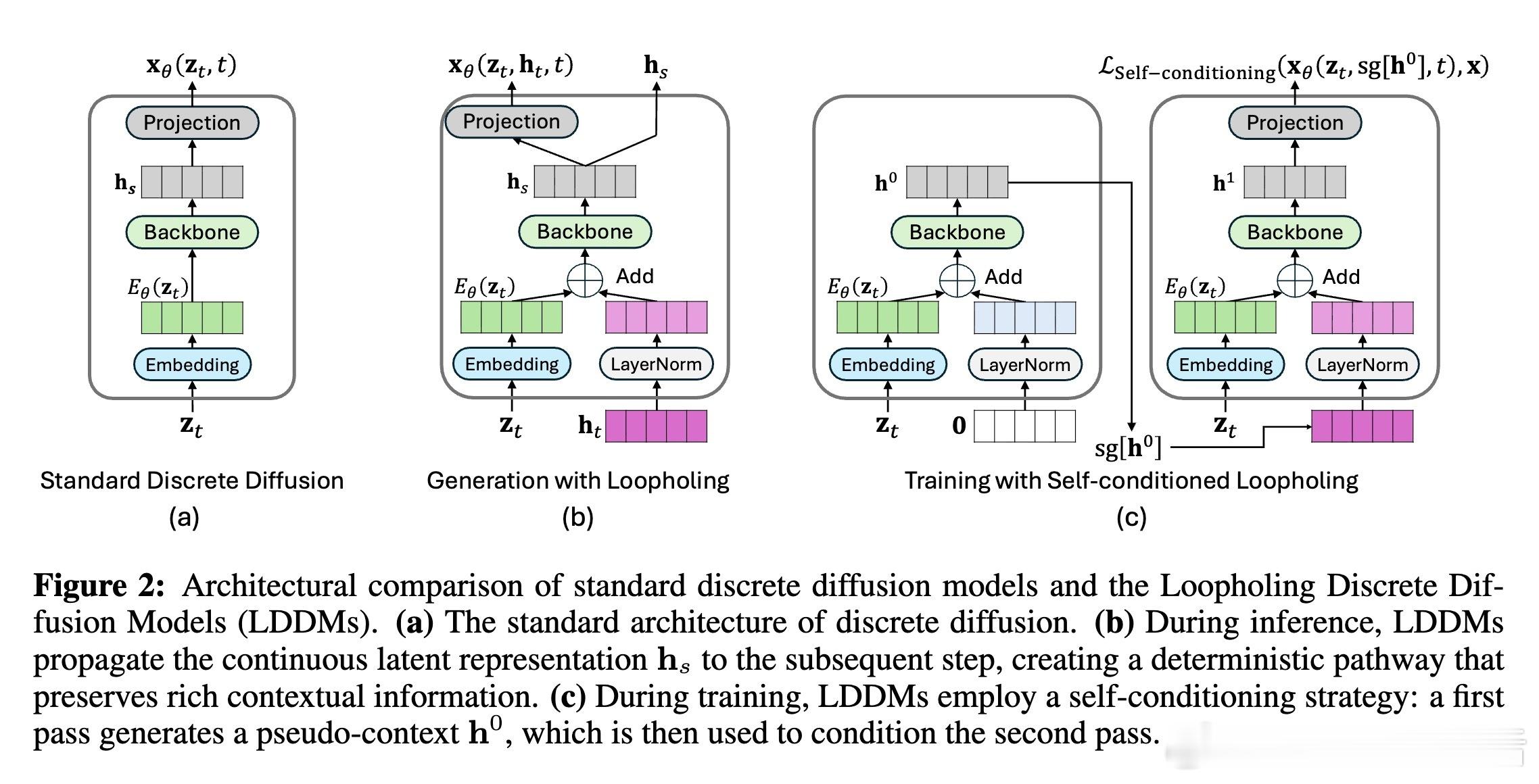
生成过程:初始化全掩码序列和零向量潜在状态ht。每个去噪步t→s中,融合令牌嵌入Eθ(zt)和归一化ht,经骨干网络fθ(如Transformer)更新hs,并投影为分布xθ。采样zs的同时,ht→hs形成确定性路径,避免one-hot瓶颈。该设计互补随机路径,维度更低(hs而非高维xθ),便于语言建模应用。
训练策略:为避免循环依赖的自展开,开销,使用双前向自条件:第一遍以零ht生成伪上下文h0;第二遍以停止梯度sg[h0]条件化,最终预测x1θ。损失为加权交叉熵(NELBO上界),以概率p应用自条件(p=0.5-0.9最佳)。这模拟真实传播,却保持扩散的单步训练优势,训练时间仅增30%,推理无额外开销。
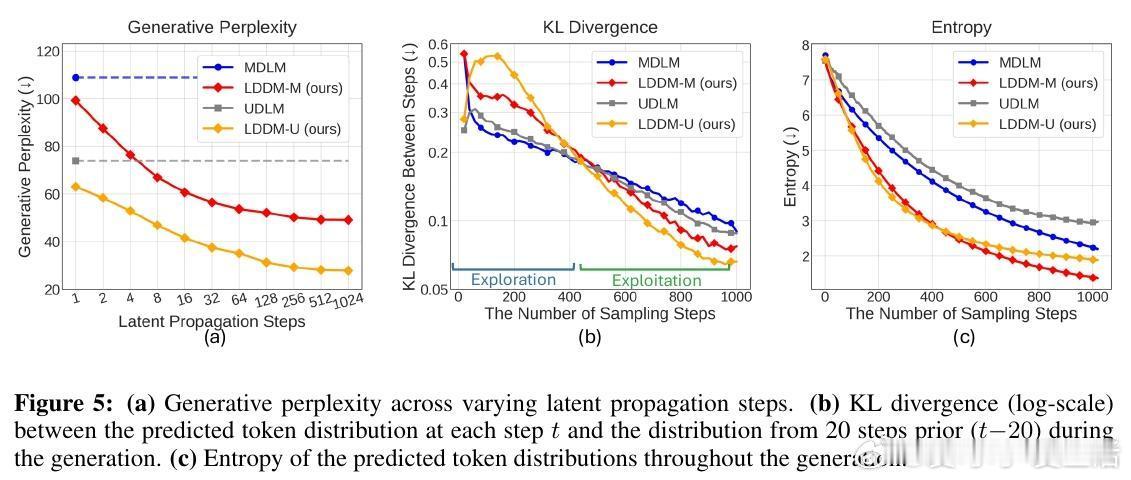
Loopholing的优雅在于其通用性:适用于Masked(LDDM-M)和Uniform(LDDM-U)框架,易集成现有模型,仅需少量修改。该机制本质上桥接了扩散的并行性和RNN的序列记忆,提供更稳定的去噪轨迹——早期探索加速(高KL散度),后期保守精炼(低熵预测)。
实验验证与洞见
在OpenWebText和One Billion Word数据集上,LDDMs训练100万步后,验证困惑度显著降低:LDDM-M从MDLM的23.82降至21.90,相对提升8%;LDDM-U从UDLM的25.51降至23.82。零样本泛化测试(PTB、Wikitext等)显示LDDM-M在多数数据集优于基线,凸显上下文传播对领域适应的益处。
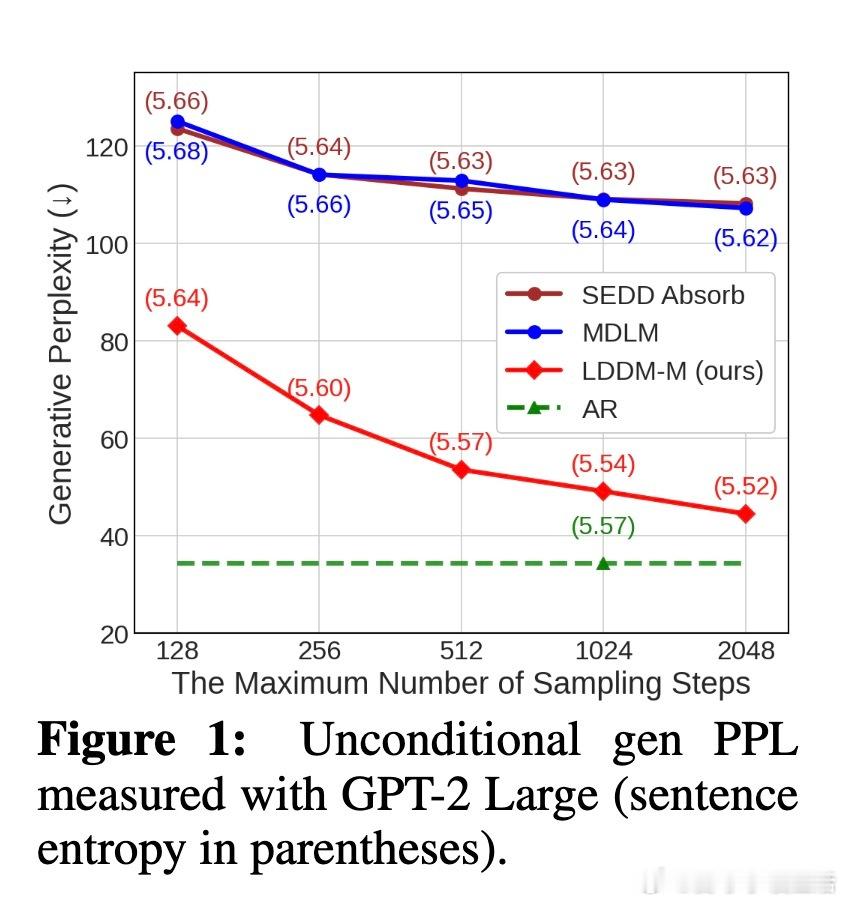
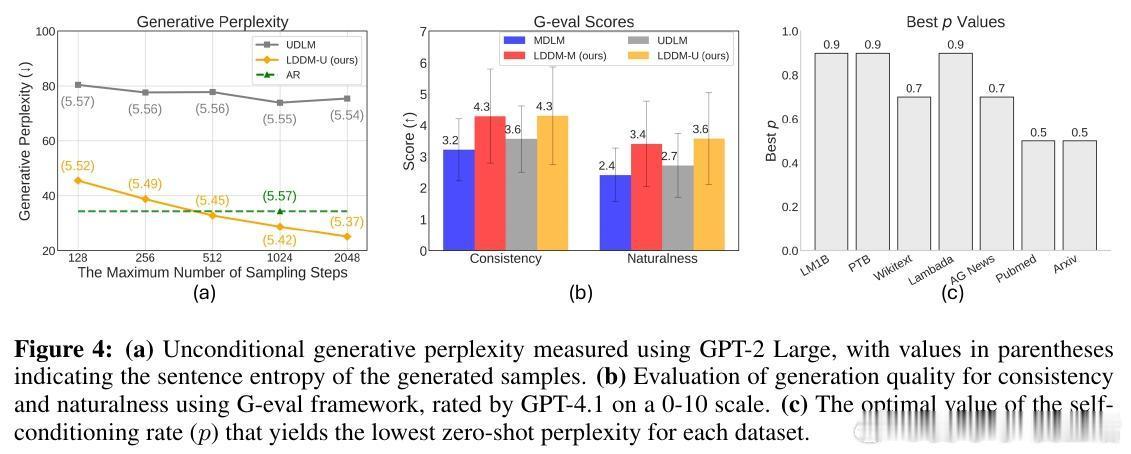
生成质量评估更突出Loopholing价值:使用GPT-2 Large的生成困惑度(Gen PPL)在1024步时,LDDM-M达49.13(MDLM的55%),LDDM-U达28.76(甚至超自回归基线34.40)。GPT-4评估的一致性和自然性得分提升,证明模型产生更连贯、人类般的文本,而句子熵稳定表明多样性未牺牲。消融研究证实:潜在传播长度k越长,性能越优;自条件率p=0.9平衡最佳;新指标TKL和TPE显示Loopholing减少振荡(后期低KL),提升置信(低熵)。
在算术推理任务(Countdown、Game of 24)上,集成至MGDM的LDDM-G将准确率从45%提升至56.3%(6M参数),85M模型达94.4%。这得益于保留解空间歧义,支持多路径探索,深化了Loopholing在结构化推理中的潜力。额外实验显示,改进源于机制而非计算预算(匹配2M步MDLM仍逊于1M步LDDM-M),并在下游任务如LAMBADA中提升12%准确率。
思考与展望
Loopholing揭示了离散扩散的瓶颈在于信息流动的断裂,而非并行范式本身。通过确定性路径,它不仅桥接了扩散与RNN,还为非自回归生成注入“记忆”深度,避免了自回归的顺序瓶颈。局限包括训练内存增加和理论框架待完善,但其可扩展性强:未来可扩展至多模态,或结合多步训练强化长程依赖。总体而言,LDDMs标志着离散扩散向实用、高质量生成的跃进,为AI文本合成提供可传播的创新路径。
原论文链接:arxiv.org/abs/2510.19304