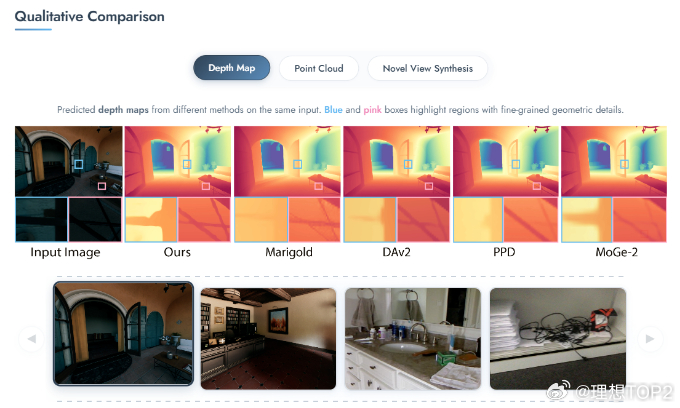
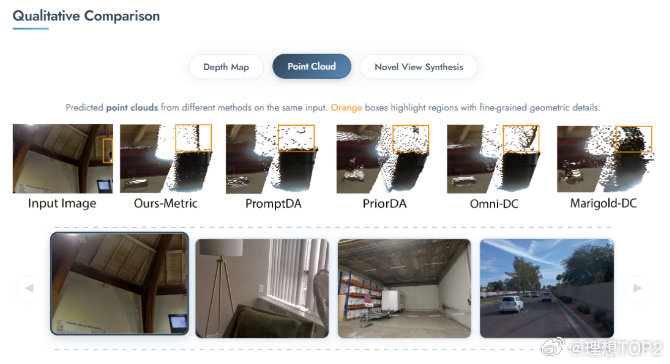
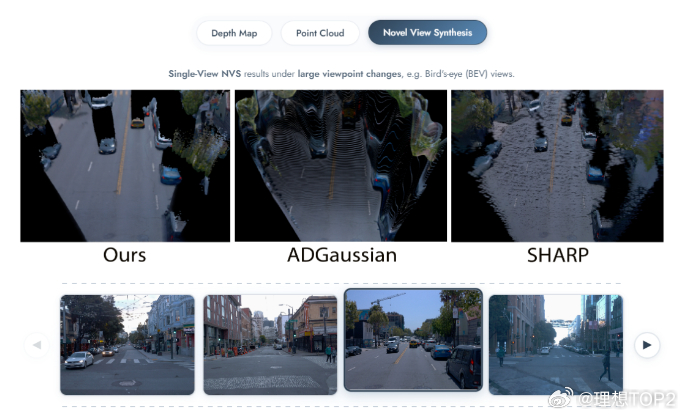
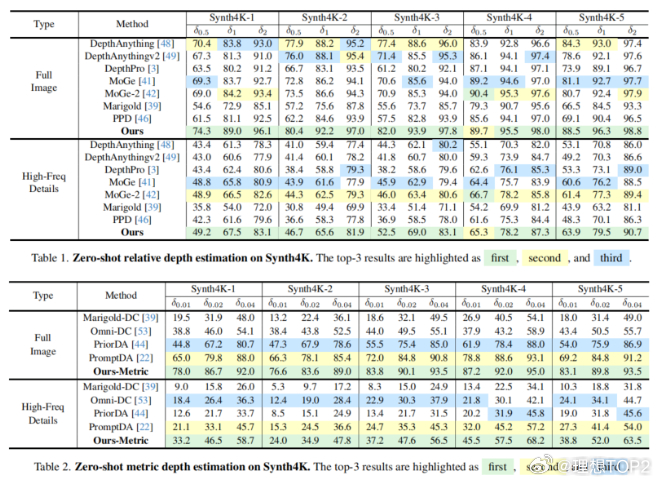
浙大&理想用全新连续性思路得到显著更好的深度估计效果2026年1月6日浙大&理想发布InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields 图1这篇论文实质是在讲用全新连续性思路,更少的计算成本,得到显著更好的深度估计效果,尤其是预测细粒度几何细节方面。深度估计可以理解成看到一张实拍图,去推算这张图里一切实体表面的三维结构。深度估计得越准,能更好的重建和生成世界模型 。目前主流深度估计方法,通常把深度图看作一个普通的二维图像(网格)。放得越大,看着就越模糊,越像马赛克,细节全丢了,且输出分辨率通常被限制在训练时的尺寸 。InfiniDepth基于神经隐式场(Neural Implicit Fields)。不再把深度看作一张由死板像素组成的画,而是看作一个连续的数学函数。可以询问这个函数图像上任意位置(哪怕是两个像素之间)的深度值,都能给一个精确的答案 。InfiniDepth的灵感来源是三个领域的前辈3D 重建领域的 NeRF & PiFU证明了不需要把世界切割成一个个死板的3D 像素,而是可以用神经网络把场景或人物建模成一个连续的函数。这种方式能以极少的参数量表现出极高的几何细节 。2D 图像的LIIF(Learning Local Implicit Fourier Representation) 。LIIF将隐式函数引入到了普通的2D图片中。不再把图片看作固定的像素矩阵,而是看作连续信号,从而实现了图片的任意倍率超分辨率。InfiniDepth实际上就是把LIIF 处理RGB图像的这种连续性思想,迁移到了深度图(Depth Map)的预测上。光流估计的AnyFlow证明了这种连续的隐式表示也可以用于预测像素的运动(光流),并且能做到任意尺度。即作者在论文背后提出的关键问题是既然 NeRF 能在 3D 空间做连续表示,LIIF 能在 2D 图像上做连续表示,那么深度估计为什么还要被限制在固定的像素网格里呢?提出这个关键问题后,就可以打破传统方法中输入图片多大,输出深度图就多大的限制,将深度也建模为一种神经隐式场,从而实现了分辨率的解绑。InfiniDepth核心三步:A. 特征提取(Feature Query)通过一个视觉编码器(使用 ViT 架构,具体为DINOv3)处理输入图像,提取出不同层级的信息。构建一个特征金字塔,既包含宏观的语义信息(大轮廓),也包含微观的纹理细节 。对于图像上任意一个想要查询的点(坐标),模型会从这个金字塔中抓取其周围的信息进行整合。B. 深度解码(Depth Decoding)模型将提取到的特征送入一个轻量级的解码器(MLP)。专门负责把这些特征翻译成具体的深度值 。这个过程是逐点进行的,计算非常高效。C. 无限深度查询(Infinite Depth Query)针对 3D 重建的优化,在进行新视角合成时,传统方法容易产生空洞 。当视角发生巨大变化时,原本图像上的像素在 3D 空间中会变得稀疏,就像把一块布拉得太长,中间透光了。InfiniDepth根据表面的倾斜程度和距离,智能地在稀疏的地方自动生成更多的查询点。就像在布料变薄的地方自动织入新的线,保证生成的 3D 点云在表面上是均匀分布的。图2更高分辨率下更好的深度图效果图3更好的点云效果图4BEV切视角更好的效果传统测试集的真值深度图通常是低分辨率且稀疏,往往无法捕捉边缘和高频细节等精细几何结构,所以浙大与理想团队就自己做了基于《赛博朋克2077》等5款3A游戏的一个新的测试集。图560个统计指标里拿了58个第一,两个第二。