[LG]《Rethinking Thinking Tokens: LLMs as Improvement Operators》L Madaan, A Didolkar, S Gururangan, J Quan... [Meta Superintelligence Labs & Anthropic] (2025)
LLM推理的新范式:用“改进算子”突破长链思考瓶颈
• 传统长链思考(Long CoT)虽提升准确率,但带来上下文膨胀、计算成本和延迟增加等问题。
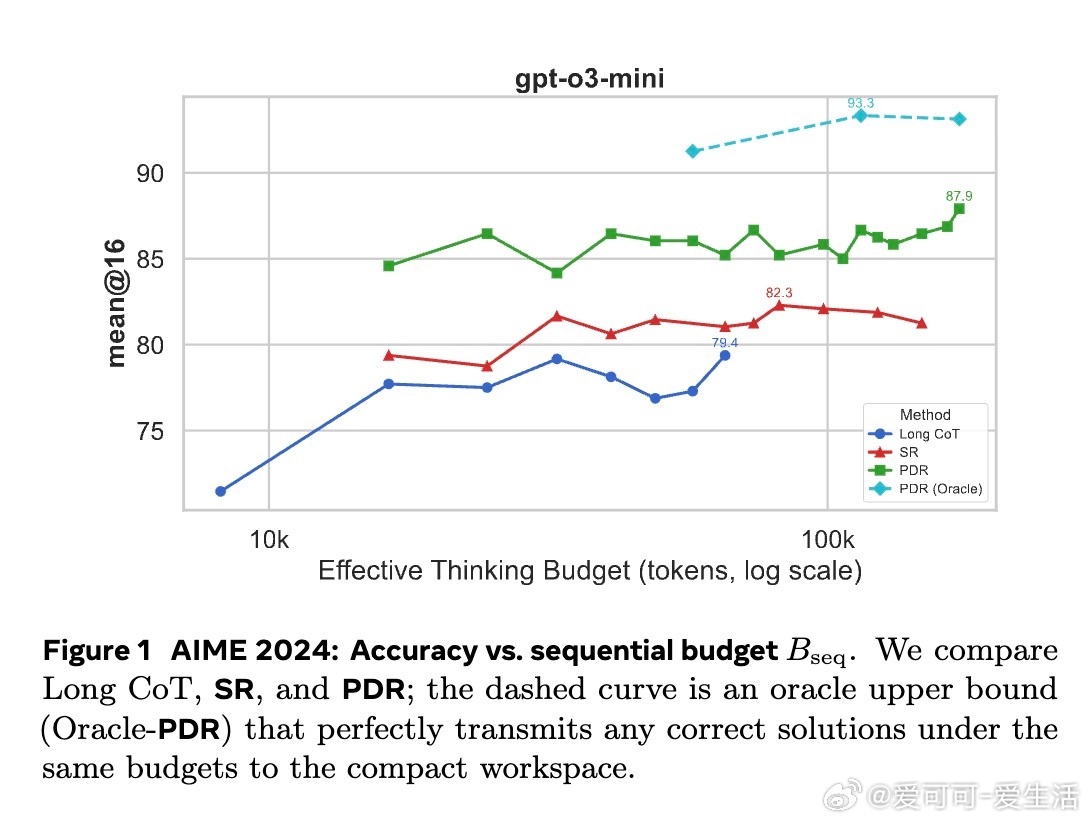
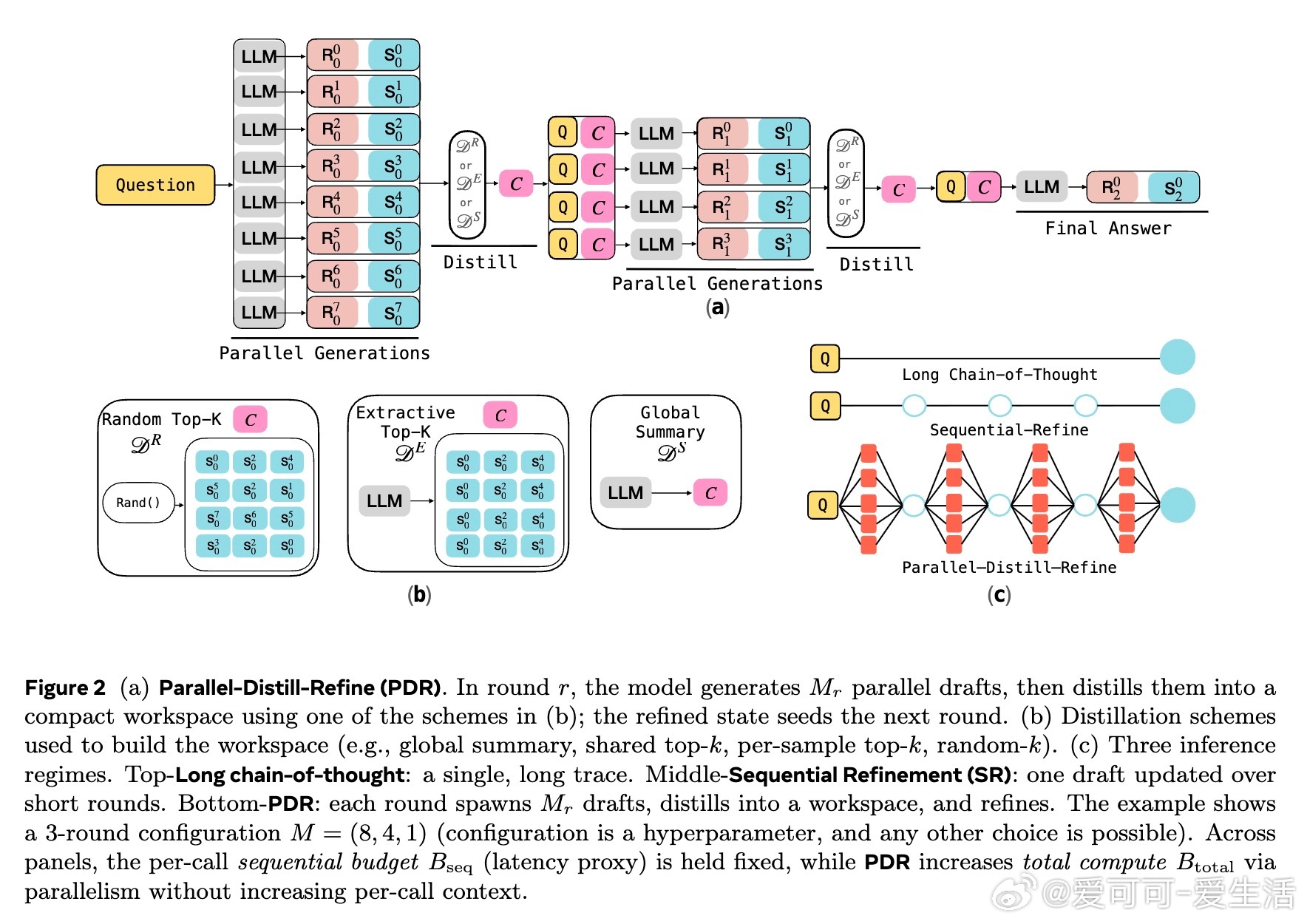
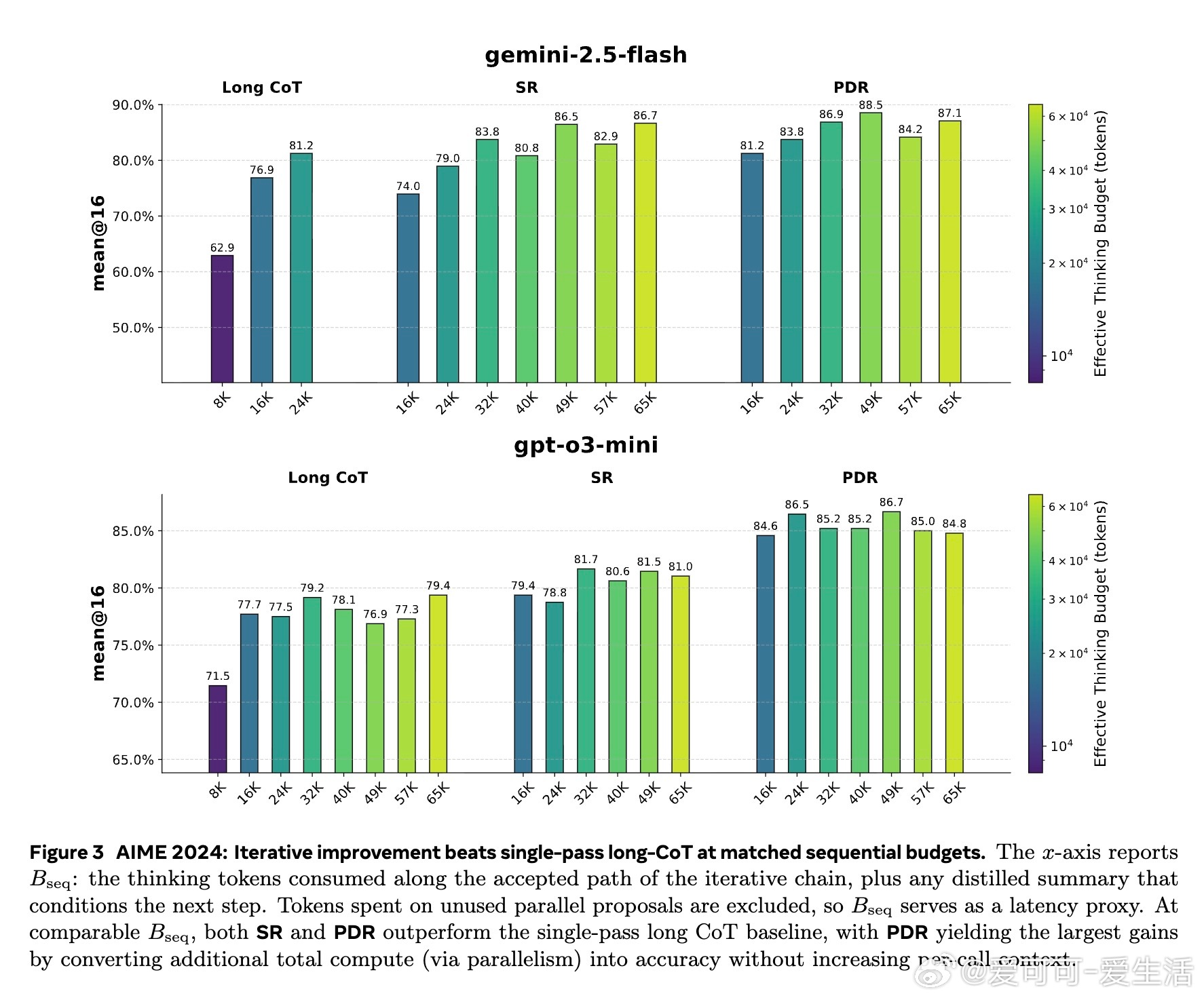
• 本文提出两种迭代改进算子:Sequential Refinement(\SR,单条思路反复打磨)和Parallel-Distill-Refine(\PDR,批量生成多解→压缩成摘要→基于摘要优化),后者可通过并行计算转换更多总计算量为准确率提升,同时保持单次上下文长度恒定。
• \PDR的核心设计是:每轮总结并压缩多条推理轨迹的关键信息(一致点、矛盾、未解决问题),构建紧凑文本工作区,避免上下文线性增长与遗忘问题。
• 训练时引入“算子一致性”强化学习策略,模拟多轮短上下文迭代,解决训练-推理接口不匹配,显著提升数学推理任务(AIME 2024/2025)准确率,最高提升达11%。
• 通过对比不同摘要策略,发现“全局摘要”和“逐样本Top-k”效果最佳,模型自验证能力决定最终性能,错误示例带来的“锚定偏差”影响明显。
• \PDR在固定延迟预算下,利用并行度调整总计算量,形成新的Pareto前沿,兼顾准确率与推理效率。
• 本文将LLM推理视作“空间受限的随机计算”,借鉴复杂度理论展示短上下文迭代推理的理论潜力,类似大脑全局工作区理论,强调信息压缩与模块协同的重要性。
心得:
1. 减少上下文膨胀并非简单缩短链条,而是通过“批量探索+压缩总结”并行提升推理宽度与深度,突破效率-准确度权衡。
2. 训练阶段若能模拟推理时的迭代摘要机制,模型更能学会“如何改进”而非“单步生成”,提高实战表现。
3. 摘要的质量与模型自我验证能力密切相关,未来提升“自我批判”和“多样性探索”能力,将是提升整体推理水平的关键。
了解更多🔗arxiv.org/abs/2510.01123
大模型推理强化学习并行计算数学推理模型训练人工智能